
The question of how to structure or arrange data in order to gain worthwhile insights is quite different from the issue of what data to include or how it should be analyzed. I often find myself preoccupied with structure and organization. In part, this is because of my belief that unique logistics can lead to different types of insights. Popular these days to the point of gaining industry dominance is holding data as large tables. If we peer into the code for the application handling the tables, in all likelihood bytes are being moved to and from many different locations in memory and files. In my line of work, data is often transferred between different tables. This sometimes occurs manually – if cut-and-paste can be described as manual. Why not get a machine to do it? I am certainly not opposed to the suggestion. Then it would be a machine moving data between tables. It is important to note that something, somebody, or both must handle the data logistics. It just so happens that when a computer does the job, the logistics are preset in code. When I handle the logistics manually, it can be shaped on the fly. When people think about this movement of data, I believe they tend to focus on the movement itself rather than the logic behind it. I suggest that data logistics – or perhaps just logistics more generally – is more about the reasoning behind the structure – the structure giving rise to movement.
How should a computer spell checker program work? Personally, I would create a data file (a.k.a. dictionary) containing a list of correctly spelled words. I would scan the specimen document and compare each word to the contents of the data file. For added speed, I might divide the data file either by first letter or first two letters; so then it isn’t necessary to scan the entire data file to check spelling. I would store the current position of the specimen scan in case the user decides to temporarily suspend the process – although the speed of the CPU might mitigate the need. It is certainly necessary to make the program check for user input on a separate thread so the user can split CPU resources. A secondary data file should be created in case the user wants to add words. The primary data file needs to be protected in case the user wants to revert back to the original. So although no movement of data has occurred, nonetheless I can reason through the structure of the enabling system. Data logistics for me is the art of anticipation, accommodation, and enablement.
In my day-to-day work activities, the analytics that I do goes towards addressing business challenges, obstacles, and situations. Although I can achieve high levels of granularity, generally speaking I monitor phenomena at an aggregate level. Because of this predisposition towards aggregate analysis, the structure of the data tends to be fairly simple: it is normally stored as tables. Compare this to the problems faced by a field investigator who might attempt to solve a murder case using the data available on site. I understand the idea of trying to address this and other types of problems using an almost actuarial approach or as business concern. But a field investigator does not play the role of social researcher or operations manager. Aggregate analysis is not particularly helpful. This person needs to use the specific facts at hand to solve the case. Venturing far from the facts can make the findings easier to question during court proceedings; more importantly, it can interfere with case resolution. A data logistician should recognize the need for data to retain the structural details of the narrative from witnesses and from multifarious resources such as surveillance relating specifically to the case.
Using Structure to Hold Relational Details
I developed Neural Logic, as it is currently described in this blog, over a couple of days. I only needed a bit more than an hour to create the prototype interpreter. However, I spent a couple of nights reasoning out the logistics – in my head – in bed as I tried to sleep. Neural Logic is not a programming language but a method of scripting relationships in data. At the core of this methodology is “forward and reverse containment logic.” Assume there is “Don Philip” and “cat” – and it is necessary to retain the relationship that Don Philip owns the cat. Forward containment can be expressed simply as Don Philip>own>cat. The cat exists (its concept is contained) only in relation to what Don Philip owns. Reverse containment differs in that the left is subsumed by the right: e.g. (Jake>kill>cat)<for<fun. This is the basic structure – subject to further development, of course.
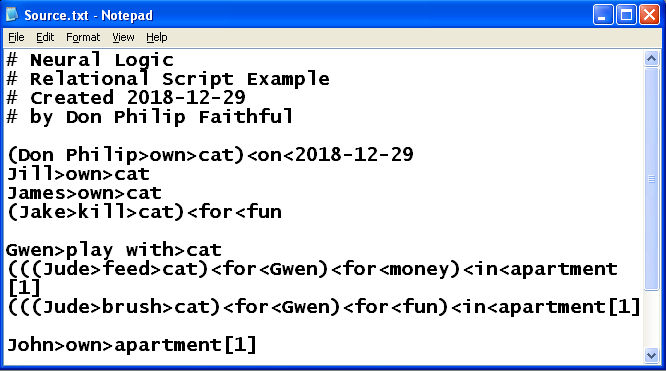
Why would anyone want to retain the relational details of data? An algorithm can be used to search for relational similarities and peculiarities. For example, 15-year-old Jake killed a cat for fun. This might be useful in the assessment of whether 51-year-old Jake has the capacity to kill anything. If the relational details are not stored, the unstructured text buried in some police records might render the past event relatively inaccessible. Possibly the person who designed the database was mostly concerned about incident categories rather than narrative details – i.e. had a more businesslike perspective on the data generated by case investigators. Personally, I would use a combination of standard text, keywords, categories, and relational code to describe noteworthy events. Below I provide some lines of relational code using Neural Logic. Notice that several people own cats. Nothing in the code indicates that they own the same cat or that the type of ownership is the same, just to be clear. Sameness can be expressed by using a shared unique reference: e.g. [1] for apartment; otherwise, sameness cannot be assumed.
The interesting part is in asking the questions. We might want to know who on the database owns a cat. We can pose the question as follows: “l/?> own>cat”. More precisely, on the left side of the expression being analyzed, what element of data precedes “own>cat”? Forward containment suggests that the owner is immediately to the left. I offer a number of other questions the results of which I will discuss individually.
On the runtime screen – a.k.a. “DOS box” or “DOS prompt” (since the program is running on Windows XP), notice that the interpreter didn’t have answers to a few questions. This is because I asked some questions that the interpreter didn’t have data to answer. Why? Because ((Don Philip>ask>questions)<for<output)<for<diagnostics. By the way, I use verbs in the third-person present tense: hence, I use “ask” rather than “asks.” I am still working on some of the specifics of implementation.
Question 1
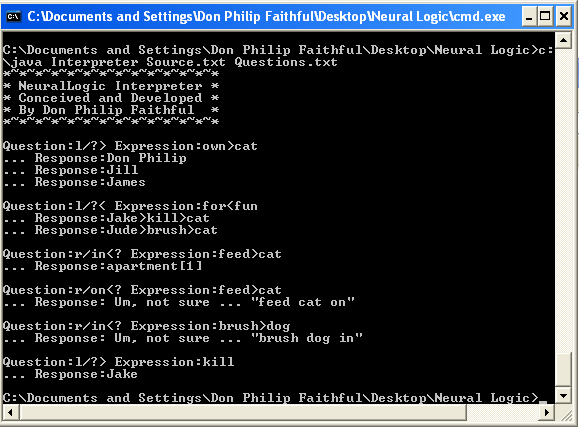
Question:l/?> Expression:own>cat
… Response:Don Philip
… Response:Jill
… Response:James
In the above, the question is who or what owns a cat. The datafile contains three explicit incidents of cat ownership. Although it is true that Jake killed a cat, this does not necessarily mean that the cat belonged to him. Hence, Jake does not appear on the list.
Question 2
Question:l/?< Expression:for<fun
… Response:Jake>kill>cat
… Response:Jude>brush>cat
Because containment is reversed, the implications of searching for a left-side construct means that the left is subsumed by the right: i.e. the left does not cause the right but rather belongs to the right. The left of the expression is what is done for fun – not who is having fun. The datafile suggests that Jake killed a cat for fun. Jude brushes a cat for fun. These are probably not the same cats. There isn’t enough information to be definitive. How is tense determined? The tense is always present tense. In terms of how the time of the event is determined, that can be included in the narrative.
Question 3
Question:r/in<? Expression:feed>cat
… Response:apartment[1]
The question is not about who feeds cats. Rather, when a cat is fed, where does the feeding occur? Jude is the only person in the data feeding a cat; this occurred in an apartment. The apartment belongs to John. But Jude feeds the cat for Gwen; and he is compensated for doing so. We therefore have the opportunity for further investigation – the relationship between Gwen and John and between Jude and John – given that Jude has access to an apartment that belongs neither to Gwen nor Jude.
Question 4
Question:r/on<? Expression:feed>cat
… Response: Um, not sure … “feed cat on”
There isn’t enough data. The question is about the details to the right of a forward containment expression. But the question involves reverse containment. This takes some thought, of course.
Question 5
Question:r/in<? Expression:brush>dog
… Response: Um, not sure … “brush dog in”
There isn’t any data about a dog being brushed.
Question 6
Question:l/?> Expression:kill
… Response:Jake
In the above, the question isn’t who or what was killed – but who or what did the killing. The datafile indicates that Jake killed a cat. (I want to reassure readers that no cats or other animals were harmed or injured in the production of this blog. A cat was used as reference as opposed to a human purely by chance. In terms of why anything had to be killed, I wanted to spotlight the possible use of relational data to solve homicide cases. I point out that “dead cat” is used in other contexts – e.g. “dead cat bounce” when a stock recovers suddenly after a freefall only to continue dropping shortly thereafter.)
In case anybody is interested, I don’t have any pets. But if I could have a pet, I would like a donkey that could haul coconuts. Behold the hard-working creature below that I would be proud to have as a pet.

(Don Philip>want>donkey[1])<as<pet
donkey[1]<is<hard-working
Those with a good sense of linguistics might point out . . .
Don Philip>want>(donkey[1]<as<pet)
After all, the relationship doesn’t exist to be subsumed under pet. The alternative above would actually result in the same answer although I indeed recognize the need to accommodate different relational structures.
Speaking of hard-working, I want to point out that since Neural Logic was only deployed recently, in all likelihood it will radically change. I am merely sharing its early development. I believe it represents a worthwhile conversation piece. In terms of how this scripting format differs from codified narrative, I would say that Neural Logic allows for expression that is highly quotidian in nature and unlikely to be quantified – whereas codified narrative is still designed for analytic interpretation – e.g. the comparing the “odour of data.” Neural Logic code is not meant to ever progress to that level. Still, there are certainly some potential overlaps in application. Codified narrative is structured by the narrative itself. Neural Logic code is structured by the relationships within the narrative, which might not be well expressed by the storyline itself. The storyline can get quite distorted in order to focus on the relationship between elements. So the main difference is that codified narrative follows the unfolding of events; relational code follows the invocation of relationships.
{kind=link}