New & Notable
Top Webinar

Recently Added

The future of DevOps: Using AI, automation and HPC
Martin Summer | May 15, 2025 at 11:48 amIntroduction DevOps has long been the backbone of modern software development, enabling faster development cycles and gr...

5 challenges in implementing AI in video surveillance
Zachary Amos | May 13, 2025 at 12:56 pmArtificial intelligence (AI) makes security cameras more versatile and useful. It can recognize suspicious behavior in r...
New Book: 0 and 1 – From Elemental Math to Quantum AI
Vincent Granville | May 11, 2025 at 11:41 pmThis book opens up new research areas in theoretical and computational number theory, numerical approximation, dynamical...

The power of distributed data management for edge computing architectures
Edward Nick | May 6, 2025 at 9:37 amA profound transformation occurs as organizations generate unprecedented volumes of data at the network edge. Edge compu...
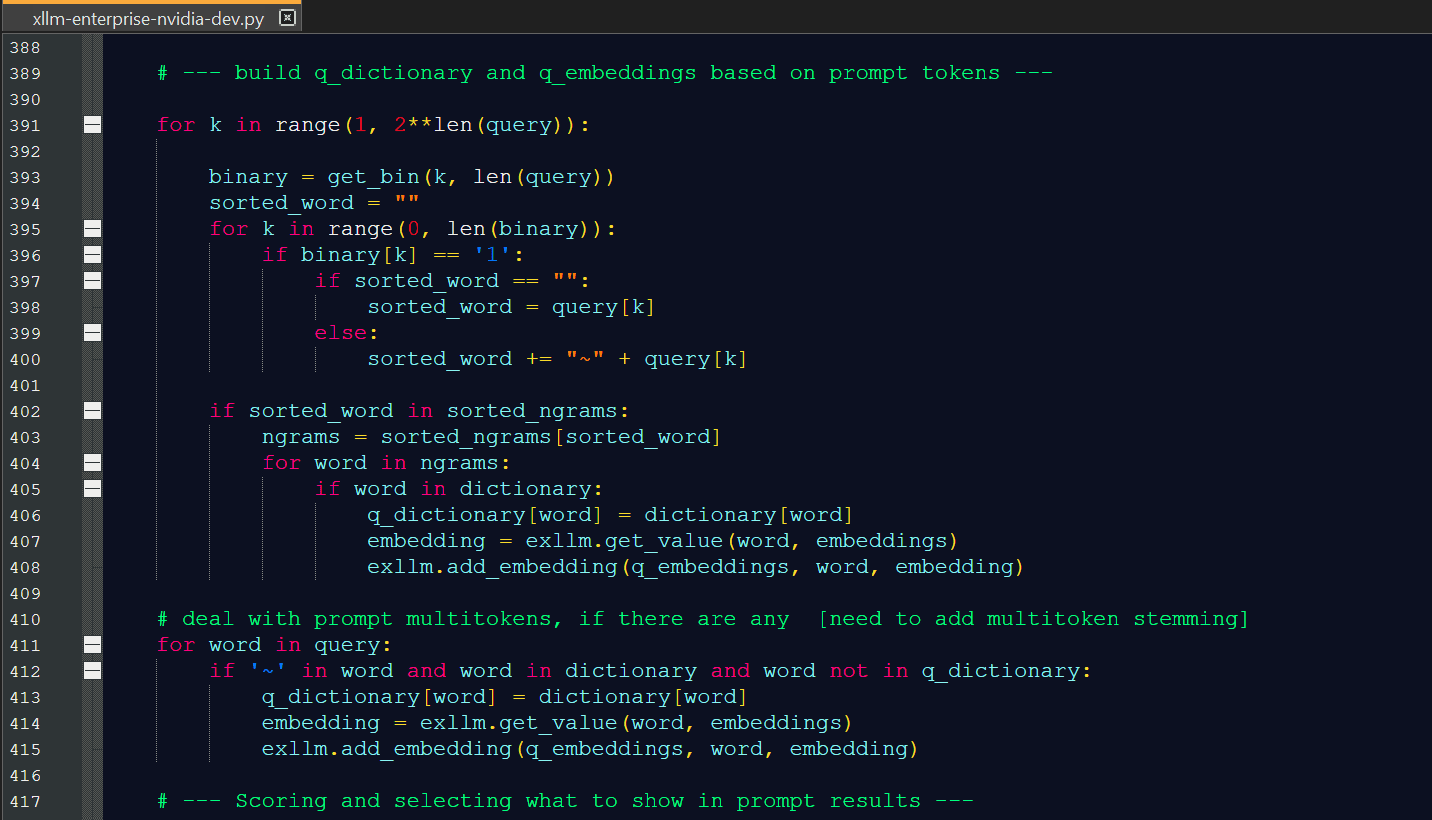
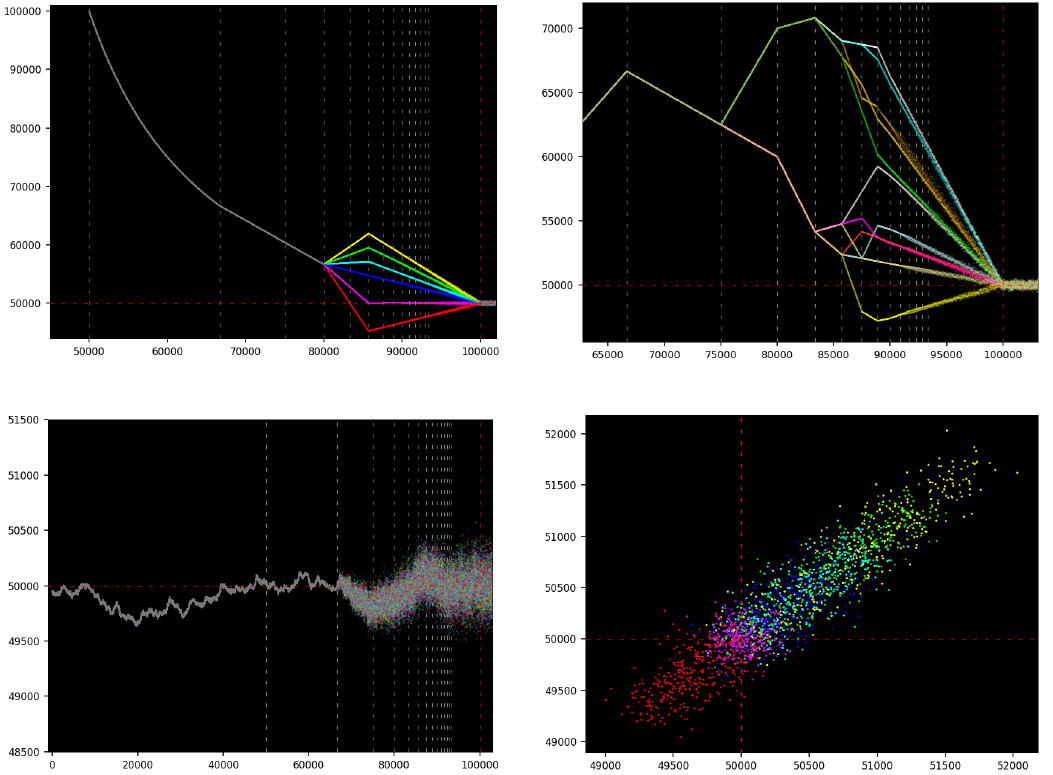
How to design LLMs that don’t need prompt engineering
Vincent Granville | May 2, 2025 at 5:07 amStandard LLMs rely on prompt engineering to fix problems (hallucinations, poor response, missing information) that come ...

From raw data to real-time insights: Building high-speed data pipeline diagrams
Erika Balla | April 30, 2025 at 11:43 amData pipeline diagrams function as blueprints that transform unprocessed data into useful information. According to an I...

How AI is redefining e-commerce experiences through data-driven design
Edward Nick | April 29, 2025 at 9:46 amIn the evolving landscape of e-commerce, artificial intelligence (AI) has emerged as a transformative force—reshaping ...
How generative AI is reshaping traditional QA strategies
Saqib Jan | April 29, 2025 at 9:42 amSoftware development cycles accelerate constantly, pushing quality assurance teams to keep pace. However, the pressure e...

Geometric deep learning: AI beyond text & images
Kevin Vu | April 23, 2025 at 10:22 amDiscover how Geometric Deep Learning revolutionizes AI by processing complex, non-Euclidean data structures, enabling br...

What’s wrong with data-based decision-making?
Tania Kalambet | April 23, 2025 at 10:11 amWhether launching a new product or changing an existing one, decision-makers are relying on data more heavily than ever....
New Videos

A/B Testing Pitfalls – Interview w/ Sumit Gupta @ Notion
Interview w/ Sumit Gupta – Business Intelligence Engineer at Notion In our latest episode of the AI Think Tank Podcast, I had the pleasure of sitting…

Davos World Economic Forum Annual Meeting Highlights 2025
Interview w/ Egle B. Thomas Each January, the serene snow-covered landscapes of Davos, Switzerland, transform into a global epicenter for dialogue on economics, technology, and…

A vision for the future of AI: Guest appearance on Think Future 1039
As someone who has spent years navigating the exciting and unpredictable currents of innovation, I recently had the privilege of joining Chris Kalaboukis on his show, Think Future.…