
I hate it when I hear senior executives state that they want to become data-driven, as if somehow having data is value in of itself. Now, one can hardly blame the unenlightened executive whose only perspectives on data are associated with statements like “Data is really the new oil” (Wall Street Journal) or “The world’s most valuable resource is no longer oil, but data” (The Economist). The infatuation with “data-driven” versus “value-driven” can be confirmed from Google Trends (Figure 1).
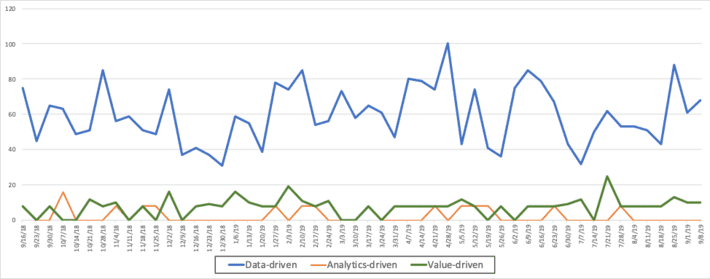
Figure 1: Data-driven versus Value-driven
However, this is where the value determination of data and oil diverge. Oil has value as determined by General Acceptable Accounting Principles (GAAP). There are accounting rules for how the value of oil is reflected on an organization’s financial statements. The quantifiable value of oil is determined by accounting “value in exchange” principles where oil commodity marketplaces can make the “in exchange” value determination.
However (and this is a big HOWEVER), data in of itself provides zero value as defined by General Acceptable Accounting Principles (GAAP). There is no marketplace where the “in exchange” value of one’s data can be determined. Consequently, data does not appear on your financial statements. Data has zero value using the accounting “value in exchange” approach.
On the other hand, if we take an economics approach – a “value in use” approach – then we have a framework for defining the value of data, which (surprise surprise) is determined by where and how the data is used to create new sources of quantifiable customer, product and operational value. Check out “Applying Economic Concepts to Big Data” for more details on the University of San Francisco research project with Professor Mouwafac Sidaoui and myself on determining the economic value of data.
Consequently, the value of data isn’t having it (data-driven) but derived in how you use it to create new sources of value (value-driven). To exploit the economic portion of data, Executives need to transition from a data-driven mindset (focused on amassing data) to a value-driven mindset (focused on exploiting the data to derive and drive new sources of customer, product and operational value).
Data may be the new oil or the most valuable resource in the world, but it is the analytic insights buried in the data that will determine the winners and losers in the 21st century.
Exploiting Economic Value of Data
Maybe the biggest economic difference between data and oil is that unlike oil, data never depletes, data never wears out, and the same curated data set can be used across an unlimited number of use cases. That forms the basis for “Schmarzo’s Economic Digital Asset Valuation Theorem” and my campaign for a Nobel Prize in Economics (see Figure 2).
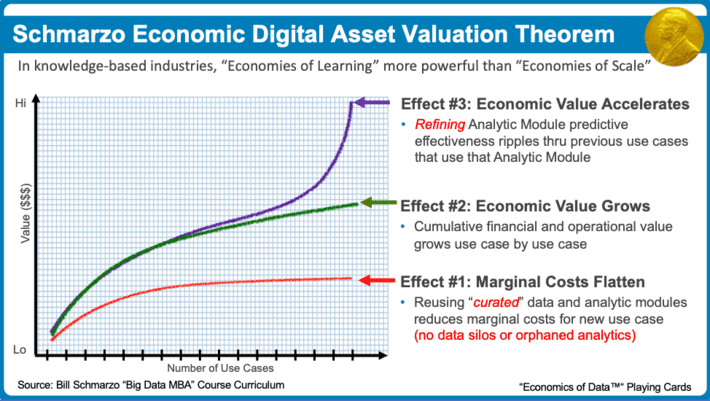
Figure 2: Schmarzo’s Economic Digital Asset Valuation Theorem
The Theorem yields three economic “effects” that are unique for digital assets like data and analytics:
- Effect #1: Marginal Costs Flatten. Since data never depletes, never wears out and can be reused at near zero marginal cost, marginal costs of sharing and reusing “curated” data flattens over a number of use cases.
- Effect #2: Economic Value Grows. Sharing and reusing the data and analytics accelerates use case time-to-value and de-risks implementation, which drives an accumulated increase in economic value.
- Effect #3: Economic Value Accelerates. Economic value accelerates because refinement of one analytic module lifts the economic value of all associated use cases that are using that same analytic model.
The economic value of digital assets is based upon the ability to share, re-use, and refine the digital assets; the ability to learn more quickly than your competition, which challenges conventional thinking about how organizations create differentiated business models.
So, if learning is tomorrow’s battleground, let’s talk about two key AI developments that can accelerate learning. Those key AI capabilities are Active Learning to accelerate deep learning model generation and Transfer Learning to more quickly generalize existing deep learning models.
Active Learning
Active learning is a special type of deep learning / machine learning algorithm that leverages human subject matter experts (or some other information source such as Wikipedia) to prioritize labeling the model input data. Machine learning models are basically guess-and-check machines — they look at some data, calculate a guess, check their answer, adjust a little bit, and try again with some new data[1] (see Figure 3).
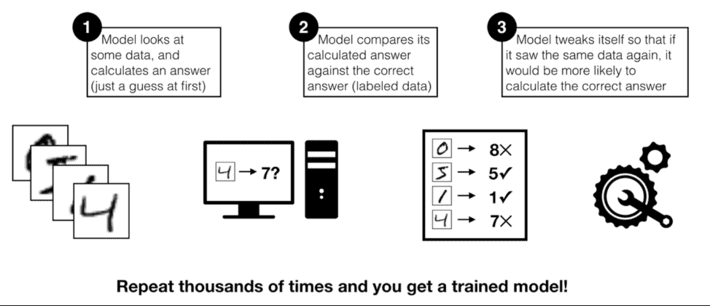
Figure 3: Machine Learning Check-and-Guess Approach
The key to an effective deep learning / machine learning’s model is access to labeled data. That typically requires the expertise of human subject matter experts (SME’s) where the expertise of that SME is dependent upon the complexity of the data being labeled (easy to label cats and dogs in photos, harder to label types of cancers and tumors in x-rays).
Active Learning uses mathematical techniques to prioritize what data the SME needs to label given the current state of the analytic model. Instead of asking SME’s to label all the data upfront, Active Learning prioritizes which data the model is most confused about at that point in time and requests labels for just that data. The model then trains a little bit on the freshly labeled data, and then again asks for SME assistance in labeling the new “most confusing” data (i.e., Is that a “4” or a “9” in Figure 4?).
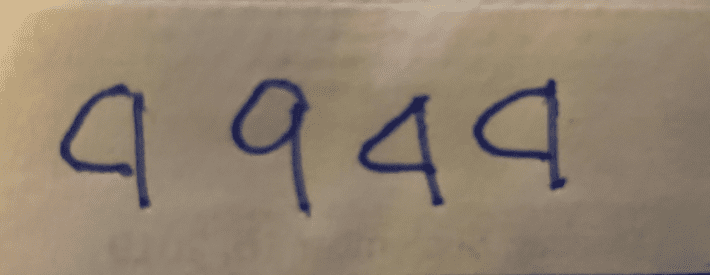
Figure 4: Distinguishing 4’s from 9’s
By prioritizing the most confusing examples, the model can focus the experts on providing the most useful information. This helps the model learn faster, and lets the experts skip labeling data that wouldn’t be very helpful to the model (see Figure 5).
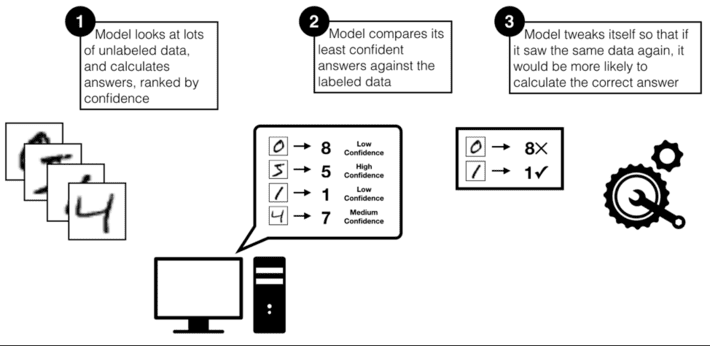
Figure 5: Prioritizing the issues that require human SME Assistance
This human-model collaboration can accelerate deep learning model development and model accuracy by prioritizing the resources requirements of the SME’s onto only those issues that require human assistance.
Transfer Learning
In deep learning, transfer learning is a technique whereby a neural network is first trained on one type of problem and then the neural network model is reapplied to another, similar problem with only minimal training (the neural network “learning” is “transferred” to another problem).
Transfer learning is a machine learning approach that seeks to re-use the Neural Network knowledge (weights and biases) gained while solving one problem and applying that knowledge to a different but related problem. For example, knowledge gained while learning to recognize cars could apply when trying to recognize trucks (see Figure 6).
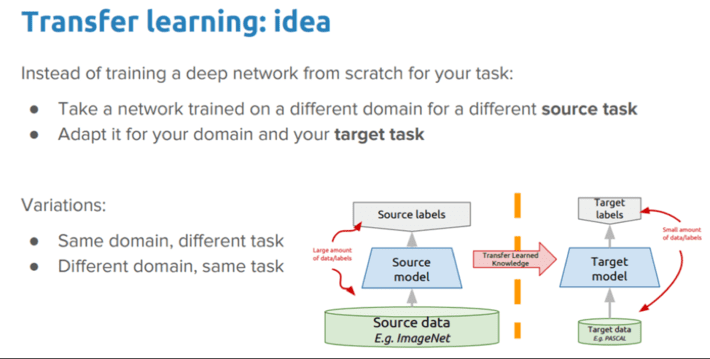
Figure 6: Source: “A Comprehensive Hands-on Guide to Transfer Learning”
Transfer Learning is key to accelerating neural network model re-use; to accelerating time-to-value and de-risking future projects through the re-use of a bona fide, real-world working Neural Network.
Focus on Value-Driven, Not Data-Driven Summary
I was recently in a customer meeting when I made the statement that “some analysts believe that in the near future, there will be more data stored at the edge than stored in the cloud.” Now I don’t know how true that statement might end up being, but it is a great provocative statement that is useful in challenging executives’ current mindset. And that’s exactly what happened.
No sooner had I made that statement when one executive worried, “How are we going to manage all of that new data?” However, it was our [soon-to-be] sponsor whose eyes lit up when he imagined “No, how are we going to monetize all of that new data?”
If learning is tomorrow’s battleground, AI innovations like Active Learning and Transfer Learning will be critically important in accelerating an organization’s learning capabilities by marrying the best of humans and AI. “Economies of Learning” is more powerful than the “Economies of Scale” in knowledge-based industries. And today, every industry is becoming a knowledge-based industry.
[1] Source: “Accelerate Machine Learning with Active Learning” by Matthew Slotkin
{kind=link}