

During the 1970s, Ethernet pioneer and 3Com Internet equipment company founder Bob Metcalfe was working on something called the “Data Reconfiguration Service” for the early Internet. “It was an effort to write a special purpose programming language to convert data formats, Metcalfe said during a 2021 OriginTrail.io panel session. “And the goal was so that the different data formats sprinkled around the Internet could be unified into one siloless web of information that everyone could access. This project did not succeed. What killed that effort [at least early on] was standardization. It proved more effective to use the same software, rather than go between incompatible things.”
“First you build a platform, and then the apps emerge. And then you build another platform, and the apps emerge,” Metcalfe said. Each platform needs a killer app to make it go. Ethernet’s killer app, Metcalfe said, was the laser printer. “We all decided that the only way you could print on this gorgeous, high-speed bitmap printer [which was eight feet long and five feet wide during the 1970s] was over the Ethernet. So guess what? Everybody had to be on the Ethernet. This printer was what drove people to plug in this card [in the 1980s and 1990s] into their PCs.”
In 2021, Metcalfe joined the Advisory Board of OriginTrail, a decentralized knowledge graph service provider that uses P2P data graphs in conjunction with blockchains to enable the sharing of trusted supply chain data at scale. He and Trace Labs Founder and CTO Branimir Rakic (OriginTrail is a TraceLabs product) discussed connectivity trends on a YouTube video that is my source for this information. Rakic listed the physical layer, the data layer, and the app layer. Metcalfe called out the people layer of buyers and sellers.
“Why are neurons better than transistors?” Mecalfe asked. “The answer is connectivity.” There are layers of connectivity we haven’t begun to get to, he pointed out.
Metcalfe doubled down on Metcalfe’s Law (a.k.a., the Network Effect) in a 2013 paper he published in one of the IEEE journals.
The original law: “The value of the network grows as the square of the number of attached nodes.”
The additional 2013 law: “Value can go to infinity if nodes go to infinity.” The stumbling block, of course, is that nodes can’t go to infinity, but the implication is that network growth, as it continues, drives more utilization, which in turn results in the square of the value. To make his point, Metcalfe fit an adoption curve to Facebook’s revenue growth.
He praised OriginTrail for focusing on fleshing out an additional layer of connectivity with the decentralized knowledge graph approach. My takeaway was that a siloless network of networks approach (which P2P data networks such as IPFS are enabling will eventually result in another wave of value on top of what’s already been achieved.
Contextual computing and the next level of connectivity
How to unleash the value of siloless networks of networks? By enabling discoverability and reuse at the data layer that hasn’t been made available by APIs and application-centric programming.
Instead, use a knowledge graph base for development, which declares reusable predicate logic and rules in the form of an extensible core data model–an ontology. 85 percent of code becomes superfluous if machine-readable context and rules are made available for reuse via ontologies in graphs.
Several years ago, former Defense Advanced Research Projects Agency (DARPA) I2O director John Launchbury put together a video explaining the various approaches to AI over history and how those approaches must come together if we’re to move closer to artificial general intelligence (AGI).
Launchbury remembers the first phase of AI–rule-based systems, including knowledge representation (KR). (These days, most KR is in knowledge graph form.) Those systems, he pointed out, were strong when it came to reasoning within specific contexts. Rule + knowledge-based systems continue to be quite prominent–TurboTax is an example he gave.
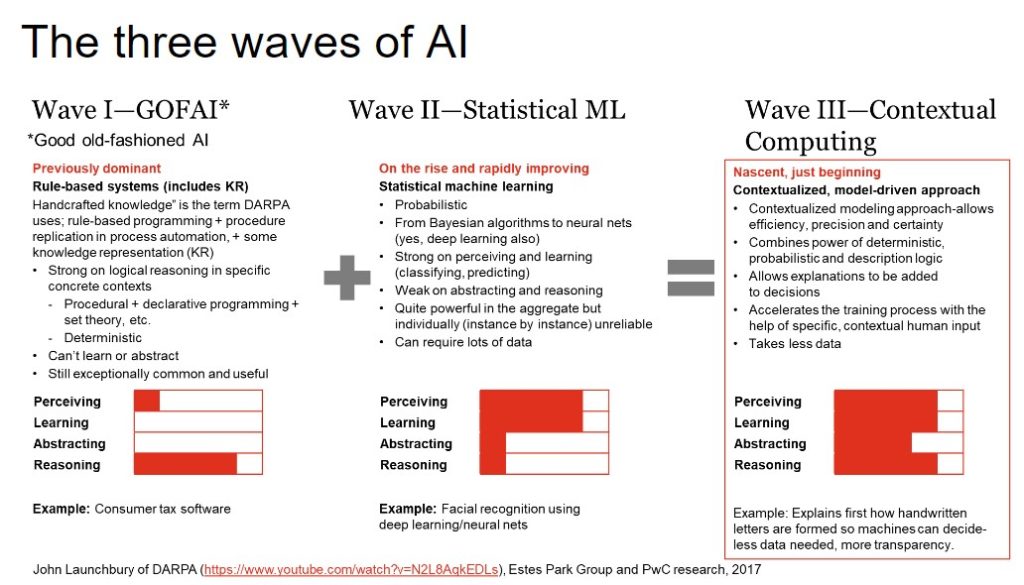
Knowledge representation using declarative languages in the form of knowledge graphs continues to be the most effective way of creating and knitting together contexts. Datalog is one example: A factual declaration on one side of an expression and a rule on the other side. The RDF stack (triplified data in subject/predicate/object form, in which each triple is a small, extensible graph) is another example.
Machines only solve problems within their frame of reference. Contextual computing would allow them to work within an expanded frame of reference, by allowing networks of context, which some would call an information fabric. In the process, machines move closer to what we call understanding, by associating each node with the settings, situations, and actions it needs to become meaningful. Relationships provide the means of describing those settings, situations, and actions in the way that nodes are contextually connected.
The second phase of AI Launchbury outlined is the phase we’re in now–statistical machine learning. This stage includes deep learning or multi-layered neural networks and really focuses on the probabilistic rather than the deterministic. Machine learning as we’ve seen can be quite good at perception and learning, but even advocates admit that deep learning, for example, is poor at abstracting and reasoning.
The third phase of AI Launchbury envisions blends the techniques in Phases I and II together. More forms of logic, including description logic, are harnessed in this phase. Within a well-designed, standards-based knowledge graph, contexts are modeled, and the models live and evolve with the instance data.
In other words, more logic becomes part of the graph, where it’s potentially reusable and can evolve.
Harnessing the power of knowledge graphs and statistical machine learning together
In January 2023, given the ubiquitous Internet and so many concurrent improvements to networked computing, everyday developers are using ChatGPT to help them reformat code. Developer advocate Shawn Wang (@swyx) tweeted a telling observation to begin the new year:
ChatGPT’s current killer app isn’t search, therapy, doing math, controlling browsers, emulating a virtual machine, or any of that other cherrypicked examples that come with huge disclaimers.
It’s a lot more quotidian:
Reformatting information from any format X to any format Y.
It’s not like ChatGPT always (or ever) gets the reformatting entirely right. It just might give developers a leg up on a reformatting task. Much will depend on the prompts each user harnesses for the reformatting purpose, as well as the breadth of the training set, the validation methods used, and the knowledge of the user.
But in any case, ChatGPT could be one indicator that improved construction and maintenance of a unified, siloless web is becoming feasible with more capable machine assist. This means the standardization Metcalfe mentioned might also soon be feasible. Data networks of networks, if well architected, will be able to snap together and interoperate with one another, as well as scale, not just because of statistical means, but because of human feedback and logic in the form of symbols.
{kind=link}