
Abstract
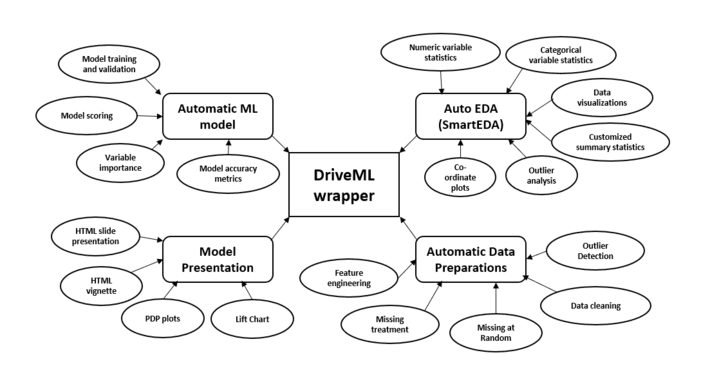
Implementing some of the pillars of an automated machine learning pipeline such as (i) Automated data preparation, (ii) Feature engineering, (iii) Model building in classification context that includes techniques such as (a) Regularised regression [1], (b) Logistic regression [2], (c) Random Forest [3], (d) Decision tree [4] and (e) Extreme Gradient Boosting (xgboost) [5], and finally, (iv) Model explanation (using lift chart and partial dependency plots). Accomplishes the above tasks by running the function instead of writing lengthy R codes. Also provides some additional features such as generating missing at random (MAR) variables and automated exploratory data analysis. Moreover, function exports the model results with the required plots in an HTML vignette report format that follows the best practices of the industry and the academia.
- [1] Gonzales G B and De Saeger (2018) /span>doi:10.1038/s41598-018-21851-7
- [2] Sperandei S (2014) doi:10.11613/BM.2014.003
- [3] Breiman L (2001) doi:10.1023/A:1010933404324
- [4] Kingsford C and Salzberg S (2008) doi:10.1038/nbt0908-1011
- [5] Chen Tianqi and Guestrin Carlos (2016) doi:10.1145/2939672.2939785.
The various functionalities of DriveML
Resources:
DriveML paper is now available in ArXiv
{kind=link}