

Object detection brings up several challenges in pattern recognition and computer vision, such as identifying and detecting various objects, and finding the location of each object in overlapping images. In object detection, the object is identified by the image given as input and location of that object is traced. Currently, there exists several algorithms that analyze the input image and provide output in terms of the detected objects, where each of them is associated with the class label as well as location (having all the coordinates of the bounding box) [1]. Among all of the object detection approaches, SSD (Single Shot Detector) is considered to be robust and fast since it uses multiple convolution for the detection of object. This blog will discuss about the SSD, its significant parameters and working of SSD.
What is SSD?
SSD is known to be a single-shot detector for object detection without exploitation of any substitute or proxy region proposal network (RPN). It envisages the classes as well as boundary boxes straight from the feature maps through a single pass only. It has improved its accuracy by introducing small convolutional filters (multi-scale features) to forecast the object classes and offsets to original (default) boxes. These are the improvements that have enabled SSD to compete with the accuracy rate of R-CNN exploiting lower resolution pictures, which additionally makes the speed higher [2].
SSD plays a significant role concerning the two key tasks of object detection i.e., classification and localization. The adaptability of the image increases its robustness of detection by taking into consideration windows of various sizes. Through SSD, detection becomes relatively easy. SSD enables feature sharing among the classification and localization tasks. SSD makes the algorithm minimize the computational cost and enables the network to acquire the features [3].
Parameters of SSD
Grid Cells
Various object detection techniques use the sliding window phenomenon to identify and locate the object, but SSD does not use this approach, rather, it divides the picture or input image by using a grid and each of the grid is itself kept responsible for identifying and detecting the objects within the particular region of that image. Detecting the object means predicting the location as well as the class of the object in that specific area/region. If there exists no object in that area, then it is considered as background class ignoring the location. Figure 1 below shows the image where a 4 x 4 grid has been used. Each grid cell has the ability to detect the class, shape, and location of the object that it contains [4].

Figure 1. Example of 4 by 4 grid cell
Anchor Box
Every grid cell is assigned with several anchor boxes in SSD which are pre-defined and are set responsible for shape and size in the grid cell. For instance, in Figure 2 below, the taller anchor box corresponds to the swimming pool and the wider anchor box corresponds to the building.
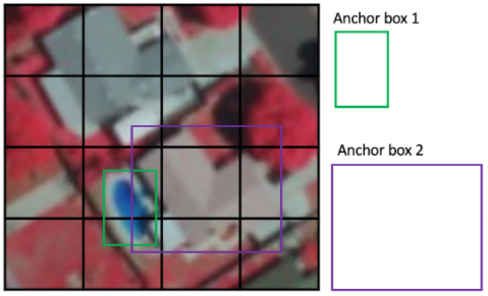
Figure 2. Anchor box
Aspect Ratio (AR)
In an image, some of the objects are taller, some are larger or wider and some are small in size. The architecture of SSD enables the already defined aspect ratios of anchor boxes to interpret this. The parameters of ratio are used to state different ARs of anchor boxes that link with each grid cell at each of the scale levels.
How do SSD works?
SSD object detection task comprises of two parts [5]:
- Extraction of the feature map
- Application of convolutional filters for detecting the objects
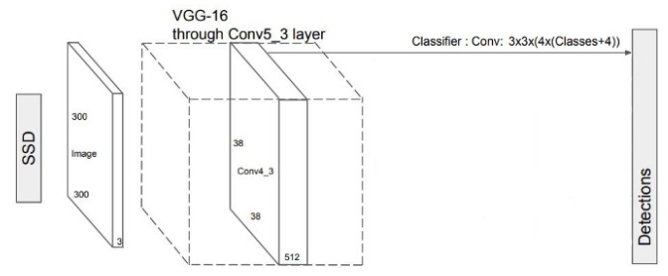
Figure 3. SSD single shot detector model
Extraction of Feature Map
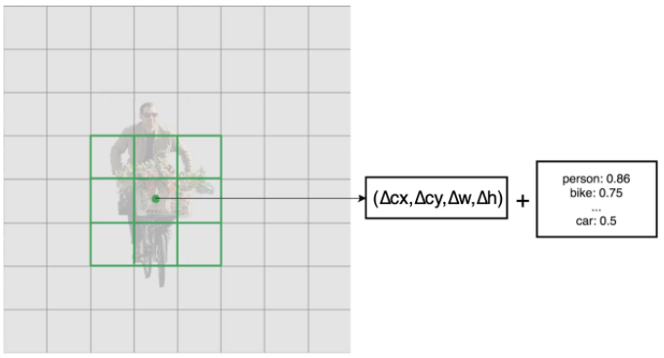
SSD makes use of the VGG16 for the extraction of the feature maps. After that, it detects the object/item by making use of layer Convo4_3. In Figure 1 below, a Convo4_3 layer has been drawn to be 8 x 8 spatially. For every cell which is known as location, the layer makes the predictions of 4 objects.
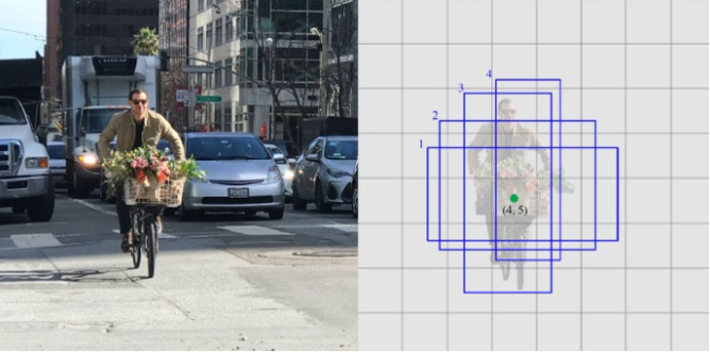
Figure 4. (a) Actual image and (b) predictions at every cell [6]
Every prediction comprises the boundary box long with 21 scores of each class. Among them, one extra class is kept for no object. The highest score is picked as the class for the bounded object. Here, 38 38 4 predictions are made in total by the Convo4_3 layer: 4 predictions for each cell irrespective of the depth of the feature map [6]. There receive several predictions having no object and SSD keep a class o indicating that this cell has zero or no object.
Applying Convolutional Filters
As it has already been said that SSD does not make use of delegated RPN, rather, it resolves the object detection by a simple approach. It identifies the location as well as class scores exploiting small convolution filters. After the process of extraction of feature maps, SSD put on 3 by 3 convolution filters for every cell for making the predictions and forecasting. These convolutional filters calculate the outcome and result in the same manner as that of the regular CNN filters. Each of the filters results in 25 channels, out of which 21 scores for every class with the addition of one boundary box. For instance, four 3 by 3 filters will be applied in Convo4_3 to the feature map having 512 input channels resulting in 25 output channels [6], [7].
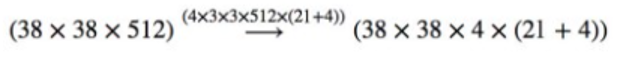
How Algoscale can help in video and image analytics?
Algoscale provides the organizations with AI-business solutions and empowers them to generate inclusive security competencies through video and image analytics. Using Algoscale real time stream of video analytics, enterprises can easily draw the interpretations and inferences.
This is the right time for you to secure your business by using our advanced video analytics to acquire critical information and find relevant images across stream of video files. Improve your ROI, unleash the patterns and insights by hauling out key data from the video.
References
[1] A. Kumar, Z. J. Zhang, and H. Lyu, Object detection in real time based on improved single shot multi-box detector algorithm, EURASIP J. Wirel. Commun. Netw., vol. 2020, no. 1, Art. no. 1, Dec. 2020, doi: 10.1186/s13638-020-01826-x.
[2] K. Wadhwa and J. K. Behera, Accurate Real-Time Object Detection using SSD, vol. 07, no. 05, p. 5, 2020.
[3] R. object detection with deep learning and O.-P. says, Object detection with deep learning and OpenCV, PyImageSearch, Sep. 11, 2017. https://www.pyimagesearch.com/2017/09/11/object-detection-with-deep… (accessed Oct. 10, 2021).
[4] S. Jia et al., Object Detection Based on the Improved Single Shot MultiBox Detector, J. Phys. Conf. Ser., vol. 1187, no. 4, p. 042041, Apr. 2019, doi: 10.1088/1742-6596/1187/4/042041.
[5] S.-H. Tsang, Review: SSD Single Shot Detector (Object Detection), Medium, Nov. 11, 2019. https://towardsdatascience.com/review-ssd-single-shot-detector-obje… (accessed Oct. 10, 2021).
[6] J. Hui, SSD object detection: Single Shot MultiBox Detector for real-time processing, Medium, Dec. 15, 2020. https://jonathan-hui.medium.com/ssd-object-detection-single-shot-mu… (accessed Oct. 10, 2021).
[7] Papers with Code – SSD Explained. https://paperswithcode.com/method/ssd (accessed Oct. 10, 2021).
{kind=link}