
In this article, an R-hadoop (with rmr2) implementation of Distributed KMeans Clustering will be described with a sample 2-d dataset.
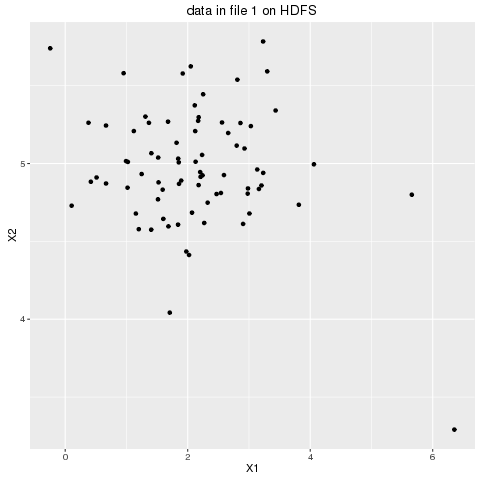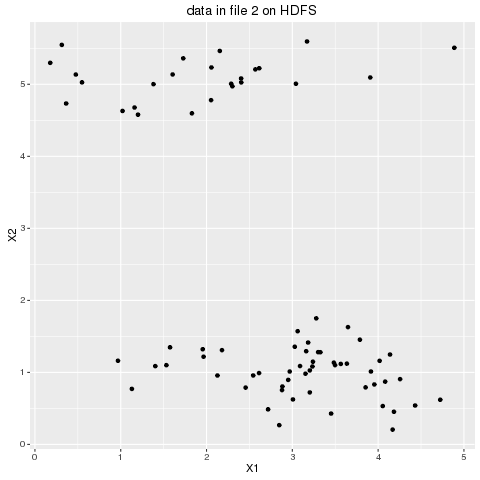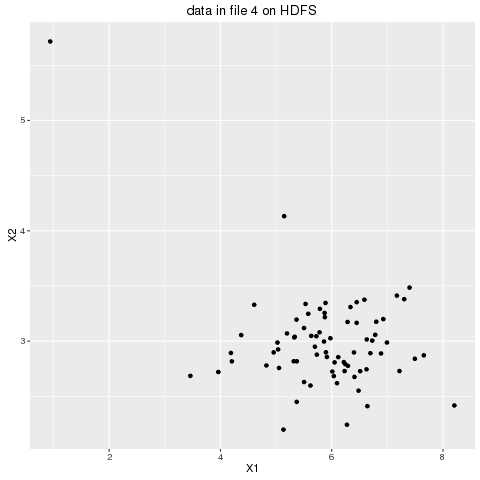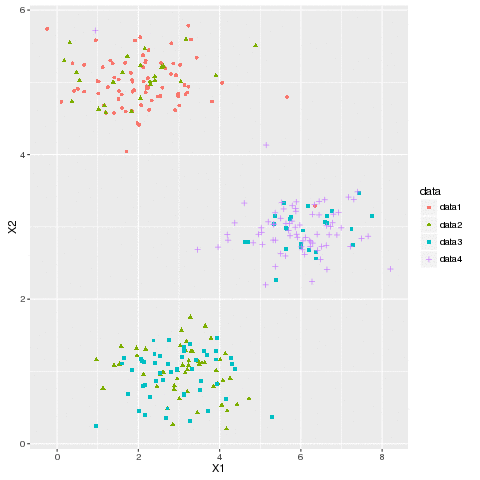
- First the dataset shown below is horizontally partitioned into 4 data subsets and they are copied from local to HDFS, as shown in the following animation. The dataset chosen is small enough and it’s just for the POC purpose, but the same concept can be used to cluster huge datasets.

- The partitioned dataset is to be clustered into K=3 clusters and the first 3 initial centroids are randomly generated.
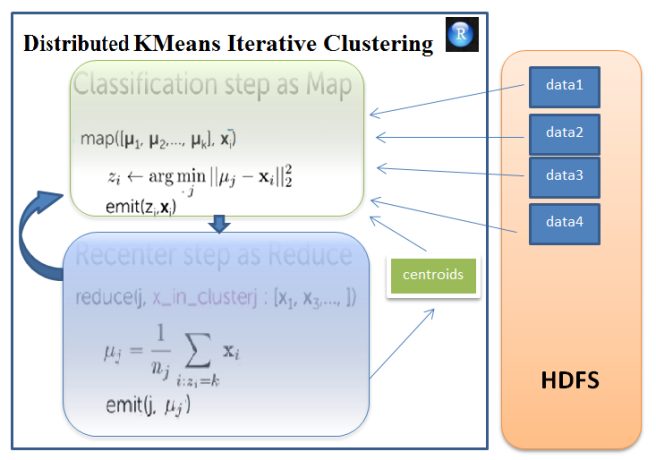
- Next, the KMeans clustering algorithm is parallelized. The algorithm consists of two key steps:
- Cluster Assignment:
- In this step, each data point is assigned to the nearest cluster center.
- This step can be carried for each data point independently.
- This can be designed using the Map function (there are 4 such map jobscreated) where the points from each of the 4 data subsets are parallelly assigned to the nearest cluster center (each map job knows the coordinates of the initial cluster centroids created).
- Once each data point is assigned to a cluster centroid, the map job emitseach of the datapoints with the the assigned cluster label as the key.
- Cluster Centroid (Re-) Computation:
- In this step, the centroids for each of the clusters are recomputed from the points assigned to the cluster.
- This is done in the Reduce function, where each cluster’s data points come to the reducer as a collection of all the data points assigned to the cluster (corresponding to the key emitted by the map function).
- The reducer recomputes the centroid of each cluster, corresponding to each key.
The steps 1-2 above are repeated till convergence, so this becomes a chain of map-reduce jobs.
The next figures show the map-reduce steps, first for a single iteration and then for the entire algorithm steps.
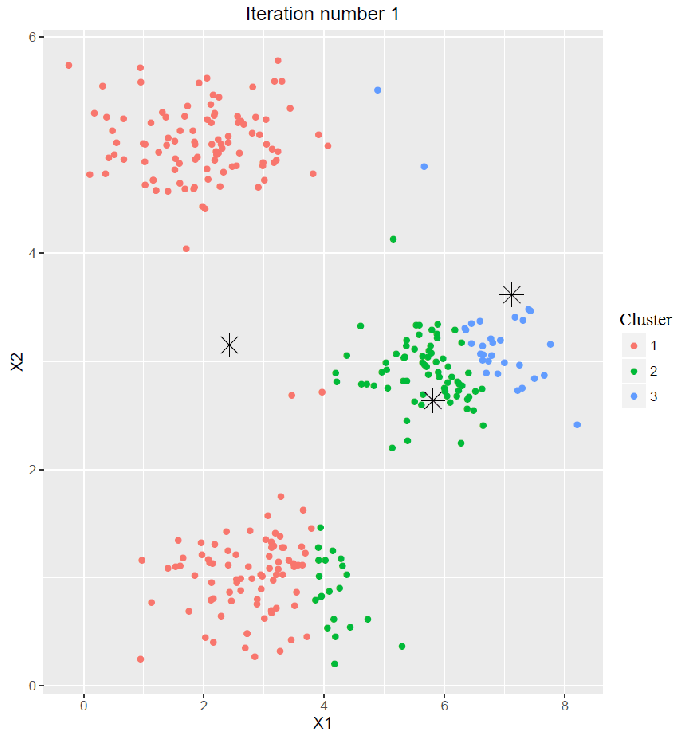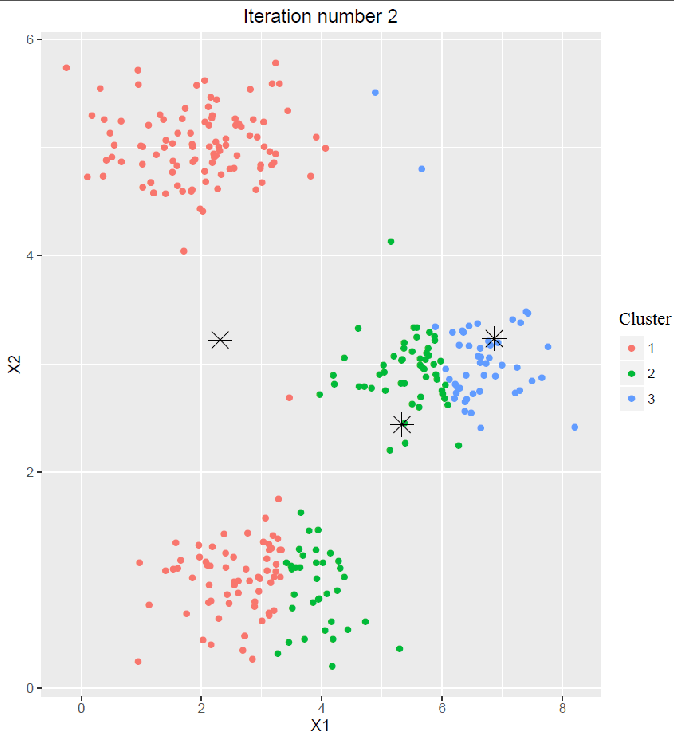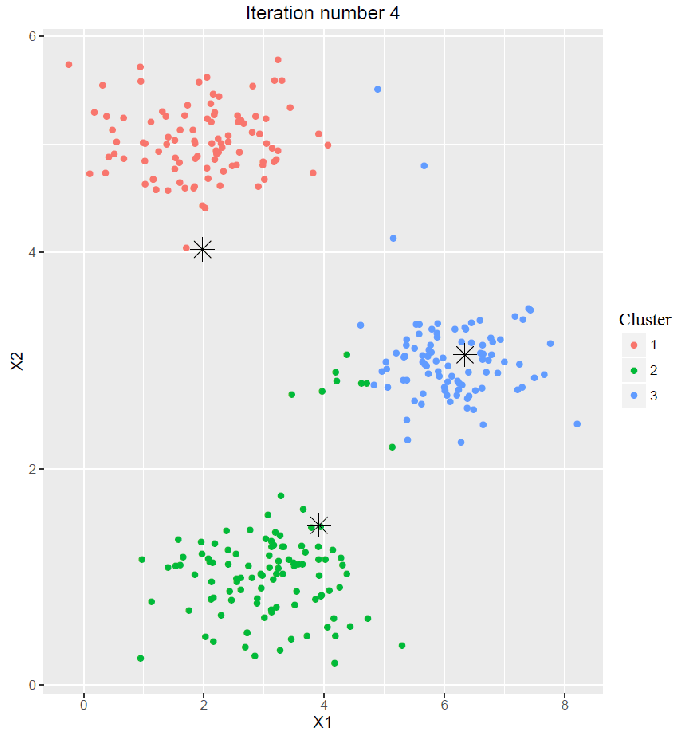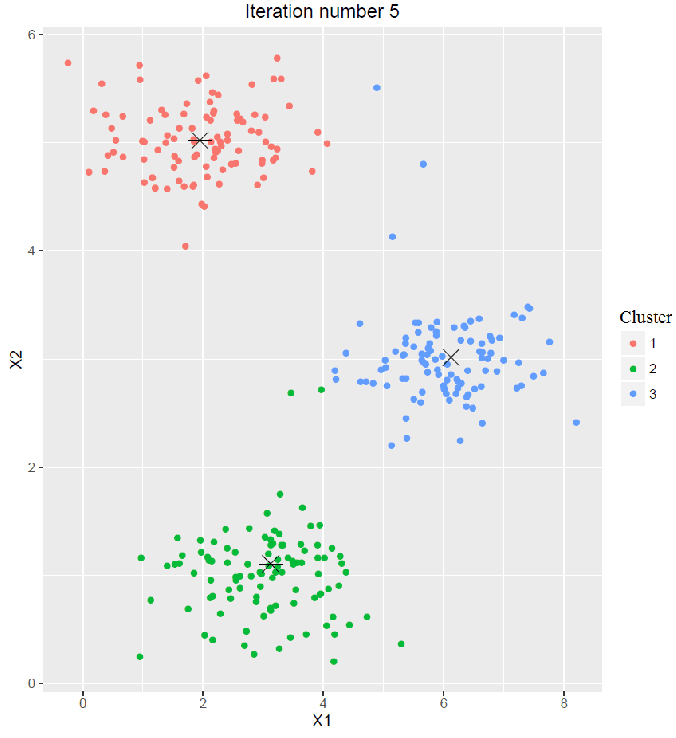
- Cluster Assignment:
- The next animation shows the first 5 iterations of the map-reduce chain.
- Every time the cluster-labels assigned to each of the points in each of the data subsets are obtained from the corresponding map job.
- Then the updated (recomputed) cluster centroids are obtained from the corresponding reduce job for each of the clusters, in the same iteration.

{kind=link}