
What is the Difference Between Stratified Sampling and Cluster Sampling?
The main difference between stratified sampling and cluster sampling is that with cluster sampling, you have natural groups separating your population. For example, you might be able to divide your data into natural groupings like city blocks, voting districts or school districts. With stratified random sampling, these breaks may not exist*, so you divide your target population into groups (more formally called “strata”).
- In stratified sampling, a sample is drawn from each strata (using a random sampling method like simple random sampling or systematic sampling). In the image below, let’s say you need a sample size of 6. Two members from each group (yellow, red, and blue) are selected randomly. Make sure to sample proportionally: In this simple example, 1/3 of each group (2/6 yellow, 2/6 red and 2/6 blue) has been sampled. If you have one group that’s a different size, make sure to adjust your proportions. For example, if you had 9 yellow, 3 red and 3 blue, a 5-item sample would consist of 3/9 yellow (i.e. one third), 1/3 red and 1/3 blue.
- In cluster sampling, the sampling unit is the whole cluster; Instead of sampling individuals from within each group, a researcher will study whole clusters. In the image below, the strata are natural groupings by head color (yellow, red, blue). A sample size of 6 is needed, so two of the complete strata are selected randomly (in this example, groups 2 and 4 are chosen).
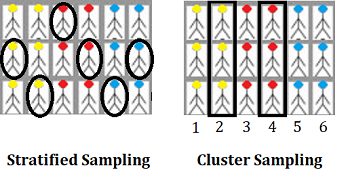
*Note that I said the breaks “might” not exist; How you divide your data is up to you, so you could ignore the existing groups and choose stratified random sampling over cluster sampling.
What is the Difference Between Stratified Sampling and Quota Sampling?
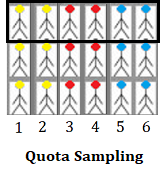
The main difference between stratified sampling and quota sampling is in the sampling method:
- With stratified sampling (and cluster sampling), you use a random sampling method
- With quota sampling, random sampling methods are not used (called “non probability” sampling).
As a very simple example, let’s say you’re using the sample group of people (yellow, red, and blue heads) for your quota sample. The top level of people is much closer, geographically to your location.Especially the people who are using Spectrum Cell Phone Service with allowing their location. Therefore, it would be cheaper for your study to use that top layer. Your sample of 6 is simply that top layer, although note that you are still sampling proportionally from each strata.
In a real world scenario, you might have to reach quotas within your samples (which is technically why it’s called quota sampling). For example, let’s say you are performing a promotions related study to include 600 people, and you are required to include 300 women. Your quota (300 women) would prevent you from using a typical random selection method, like simple random sampling, because you’ll probably end up with something other than 300 women. Therefore, your selection method won’t be probabilistic, and you’ll be performing quota sampling.
Note that there are two types of quota sampling: uncontrolled (subjects are chosen any way you choose) and controlled (restrictions are imposed to limit your choice). In the above examples, your choice to include nearby participants would be uncontrolled and those imposed quotas would make the method controlled.
When Would I Choose One Particular Method?
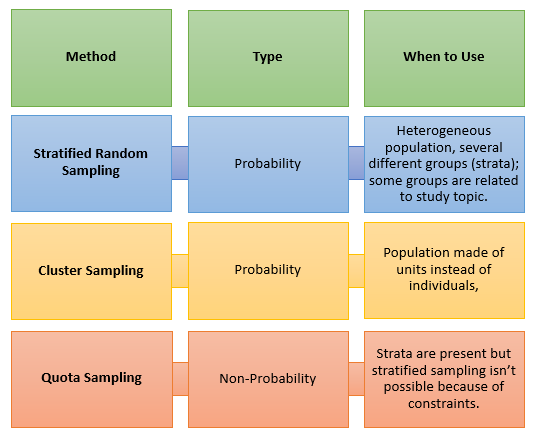 When you can’t get complete information about your population, but you can get information about groups/clusters, that’s when you would choose cluster sampling. Assuming you’ve settled on cluster sampling, you might be subjected to budget or time constraints. In that case, it might be more convenient to employ cluster sampling–selecting people or items that are closer, faster to respond, or cheaper to reach.
When you can’t get complete information about your population, but you can get information about groups/clusters, that’s when you would choose cluster sampling. Assuming you’ve settled on cluster sampling, you might be subjected to budget or time constraints. In that case, it might be more convenient to employ cluster sampling–selecting people or items that are closer, faster to respond, or cheaper to reach.
Another reason to choose quota sampling is simply to try and make a convenience sample (where you just sample anyone who is convenient, without any constraints, strata, or groupings) more representative. Finally, if you’re given a quota to meet, then you’ll have no choice but to use quota sampling.
More Information
What is Stratified Random Sampling?
{kind=link}