
Machine learning is getting more and more popular in applications and software products, from accounting to hot dog recognition apps. When you add machine learning techniques to exciting projects, you need to be ready for a number of difficulties. The Statsbot team asked Boris Tvaroska to tell us how to prepare a DevOps pipeline for an ML based project.
There is no shortage in tutorials and beginner training for data science. Most of them focus on “report” data science. A one-time activity is needed to dig into a data set, clean it, process it, optimize hyperparameters, call .fit() method, and present the results. On the other hand, SaaS or mobile apps are never finished, always changing and upgrading complex sets of algorithms, data, and configuration.
There are two different types of applications:
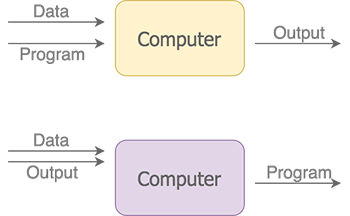
Machine learning often expands functionality of existing applications — recommendations on a web shop, utterances classification in a chat bot, etc. It means it will be part of the bigger cycle of adding new features, fixing bugs, or other reasons for frequent changes in overall code.
One of my last projects was to build a productivity bot — help knowledge workers in the large company to find and execute the right process. It has a lot of software engineering — integration, monitoring, forwarding the chat to the person, several machine learning components, etc. The main one was intent recognition where we decided to use our own instead of online services (such as wit.ai, luis.ai, api.ai) because we were using a person’s role, location, and more as additional features. As any agile project, we were aiming to get new functionality on a fast and regular basis.
The standard application that manages this fast-moving environment is managed through the pipeline of version control, test, build, and deployment tools (CI/CD cycle). In the best case, it means a fully automated cycle; from a software engineer submitting the code into central version control (for example github.com), through building and testing till deployment to the production environment.
Adding machine learning into this life cycle brings new challenges and changes in a DevOps pipeline.
Testing of statistical results
Traditional unit and integrations testing run on a small set of inputs and expect to produce stable results. The test will either pass or fail. In machine learning, part of the application has statistical results — some of the results will be as expected, some not.
The most important step for applying machine learning to DevOps is to select a method (accuracy, f1, or other), define the expected target, and its evolution.
We have started with 80% accuracy and put the stretch target to move 1 point per week for 10 weeks. The important decision here is what can an end user still accept as help or improvement over application without ML. Our targets were too strict and we were “failing” too many builds, which the client wanted to see in production.
The second important area in ML testing is testing the data set. There is only one simple rule — more is better. We have started training data sets for our bot with a small labeled set and used selected utterances from this data set as testing scenarios. As the data set grows we have better and better test results, but not so much in the production. We have changed the testing to 25% of the overall data set and keep strict separation of training and testing data for all cycles.
Change in results without changing the code
The traditional software engineering approach is to run tests every time there is a change in the codebase. But applying machine learning to DevOps, you need to remember that the quality of machine learning can change with no changes in the code.
The amount and quality of training data are critical for the results.
A testing cycle is usually triggered by a change in codebase. The push to Github starts other tools to build, test, etc. Github is a great tool for managing code, though not so great for managing data sets. Even it cannot host real-sized data sets — the limit on file size is 100M.
Our small data set was still able to fit into the Github repository and as it is pure text it was even able to show differences in each version. As it grew, we moved it into a separate storage account and used a set of python scripts to clean it and split it into a train file and a test file. At the same we had to change the frequency of retraining the classifier as the training time took too long.
Time to train the classifier
The third challenge every machine learning application faces in CI/CD cycle while applying to DevOps is the time needed to train the classifier. An agile process should be fast and able to make changes in a production system as soon as possible. Training of a machine learning classifier can easily take several hours or days. We had to move from retraining on each build to our current approach of retraining weekly to bi-weekly.
There are two basic architectural approaches to address these challenges with a lot of possible shades between them.
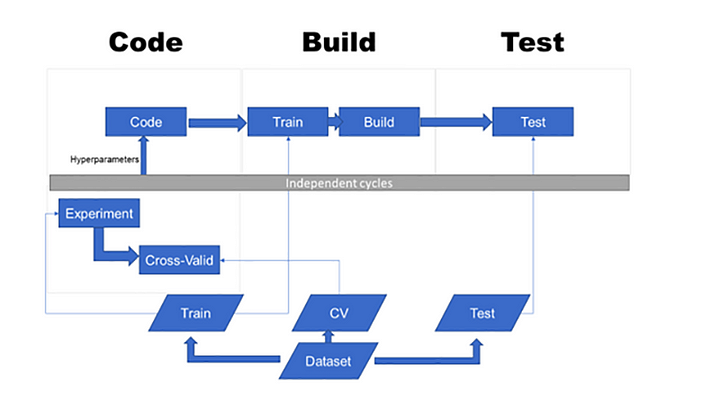
Include full processing into your CI/CD cycle
This is where we have started. And it looks to be the easiest and the most straightforward way for a small team and a small dataset.
Pros:
• Easy fit to existing process
• Full visibility of changes either in code or in data
Cons:
• Slow process
• A lot of “failing builds” for no apparent reason or change in code
• Complex management of training and testing data sets
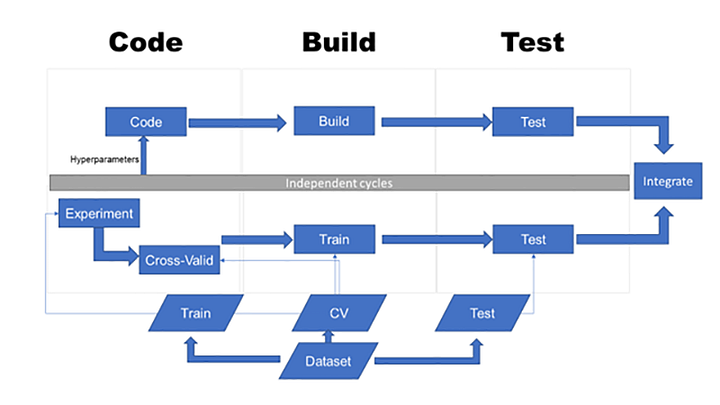
Carve out the machine learning part into a separate service
Pros:
• Clear separation of responsibilities
• Ability to use different languages / frameworks for each part (in our case python for machine learning and javascript for bot)
Cons:
• Risk of premature definition of services
Final thoughts
Our experience shows that there is no one-size-fits-all approach to combining traditional software engineering and machine learning in one project.
At the early stages of the project when our data structure and features were changing often, the most simple approach was the best. Quick and dirty is sometimes the best way.
It did allow us to start the feedback cycle and evolve the model. The important thing is not to forget the technical debt you are building into the software. As our data set grew we had to start moving parts out of core service.
The second step was to separate machine learning into independent services. By the time our build/test run went for 6 hours we had to move it out even though the rest of the software was not ready to separate into a microservice architecture. The main driver for the separation of machine learning is the size of the data set.
What is your experience with applying machine learning to DevOps?
{kind=link}