

In the previous post, we discussed causal AI applications
In this post, we discuss how to develop such applications
The post is based on the causalnex library which we have been experimenting with
consider the question
if we increased the training budget by 15% would our employee attrition reduce by 5 percent? (considering that there maybe other variables involved)
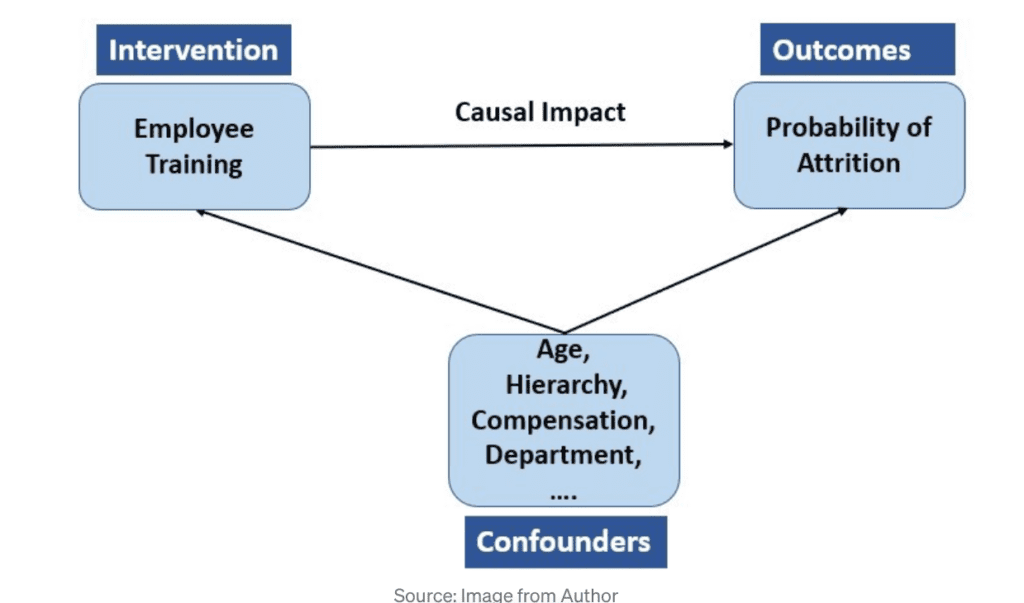
such a question is a causal question and it is also a counterfactual question (what-if question)
Traditional machine learning is not designed to solve such problems
Most machine learning models are concerned with correlation. In contrast, Causal models are concerned with cause and effect relationships – for example – “How much would a power failure cost to a given manufacturing plant?” Some domains like medicine use randomised control trials – but these are expensive to replicate at scale
Causal models provide specific benefits:
- They help to determine cause and effect relationships
- They can work well with unseen data
- They can work well with relatively small amounts of data
- Causal models are explainable
- Causal models can provide ‘what-if’ analysis
- Causal models can more easily incorporate human input(expert domain knowledge)
There are two practical ways to use causal models
- for intervention of factors – ex if we invested 10 percent more in product development – how much would sales increase by? (keeping in mind that there would be other factors that influence sales)
- for counterfactual queries if we increased the training budget by 15% would our employee attrition reduce by 5 percent?
A structural causal model (SCM) represents causal dependencies using graphical models. Bayesian Networks are one of the most widely used SCMs. Bayesian Network consists of a DAG(Directed Acyclic Graph), a causal graph where nodes represent random variables and edges represent the relationship between them, and a conditional probability distribution (CPDs) associated with each of the random variables. The links between variables in Bayesian Networks encode dependency but not necessarily causality.
Hence, we need to use the framework of SCMs to model causal relationships using the following steps:
- Structure Learning. The structure of a network describing the relationships between variables can be learned from data, or built from expert knowledge.
- Structure Review. Each relationship should be validated, so that it can be asserted to be causal. This may involve flipping / removing / adding learned edges, or confirming expert knowledge from trusted literature or empirical beliefs.
- Likelihood Estimation. The conditional probability distribution of each variable given its parents can be learned from data.
- Prediction & Inference. The given structure and likelihoods can be used to make predictions, or perform observational and counterfactual inference.
source: steps based on implementation from causalnex library
Models can reflect both statistically significant information (learned from the data) and domain expertise simultaneously. However, creating practical solutions is not easy. It is necessary to constrain the search space by strategies such as grouping features into themes and finding relationships between themes. In general, domain knowledge can be used to both constrain the search space and to estimate variable distributions. constrain the search space to inspect how themes of variables relate. There is unfortunately no way to fully automate causal Inference.
I expect that we will many more causal applications and models in the near future.
for causalnex library see https://causalnex.readthedocs.io/en/latest/
Image source https://towardsdatascience.com/causal-ai-enabling-data-driven-decisions-d162f2a2f15e
{kind=link}