
Summary: Got a good AUC on your hold out data? Think that proves that it’s safe to put the model into production. This article shows you some of the pitfalls in this new era of black box Deep Learning Neural Nets and a method for identifying potentially devastating errors.
 Image source: XKCD
Image source: XKCD
Recently we’ve been reading that the increased adoption of Deep Learning (DL) image, text, and voice processing tools has been driven by the fact that major developers like Google and Facebook have been able to achieve accuracies of 99% or greater. That’s great. Deep Learning is indeed on a roll. But before you rush out to add DL to your app, take a step back and consider whether the answers you’re getting are in fact right even with very high AUC scores.
Deep Learning is an evolution of Neural Nets (NN) and NNs have been around for a long time. In voice, text, and image they’re used as classifiers. Is that a cat? Yes or no. Does this conversation with your CSR show that the customer is unsatisfied? Yes or no. Does that CAT scan show a diseased heart that needs to be operated on right away? Yes or no.
However, Deep Learning applications of NNs are black box predictors. In the early days of NNs this was also a problem since you couldn’t see how they were working and therefore couldn’t explain it. We relied on error measures applied to held-out data and if the result was good we figured we could trust the model.
Before Deep Learning our supervised modeling was based on a target variable and a bunch of independent features that we could examine and understand. For example, one reason we liked decision trees is that they were easy to interpret and explain. Eventually, as the wrappers around NNs became sophisticated enough to export code we could look at the weight assigned to each feature and have some level of explanation and some comfort that the model was reasonable in addition to a good AUC.
Fast forward to Deep Learning NNs and now we’re back to the black box. What’s more, although training still requires a target variable (lots and lots of pictures of cats and not-cats) there are no longer any interpretable independent features for image and text. When we’re dealing with pixel groupings or bags of words, how do you know that your DL model is looking at the right things, even when the AUC is high?
Our hat’s off to Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin (all Univ. of Washington) who earlier this August published an important research paper illustrating why Deep Learning classifiers (indeed any classifier) should not be trusted on AUC alone and what to do about it.
Their message is about a technique for increasing interpretability which we’ll get to in a minute. What struck me however was how misleading high AUC DL models could be once you understood they were getting the right answer but for completely the wrong reasons.
The following examples are drawn directly from their research paper or subsequent blogs written by them.
An Example from Text Processing
In their first example, the task is to classify articles as pertaining to “Christianity” or “Atheism” (using the well-known “20 Newsgroups” data set). This is considered difficult because the two topics are likely to share many common words. Actually, their classifier seemed to do a very good job with an AUC of 92.4.
However, when you look at the words their model used to differentiate you see quite a different story.

What the model actually used for classification were these: ‘posting’, ‘host’, ‘NNTP’, ‘EDU’, ‘have’, ‘there’. These are meaningless artifacts that appear in both the training and test sets and have nothing to do with the topic except that, for example, the word “posting” (part of the email header) appears in 21.6% of the examples in the training set but only two times in the class “Christianity.”
Is this model going to generalize? Absolutely not.
An Example from Image Processing
In this example using Google’s Inception NN on arbitrary images the objective was to correctly classify “tree frogs”. The classifier was correct in about 54% of cases but also interpreted the image as a pool table (7%) and a balloon (5%).

Using LIME to Solve the Problem
Fortunately, Ribeiro, Singh, and Guestrin have shown us a way out of this problem. Personally I think this is one of the most interesting innovations to come along in quite a while and everyone should give serious consideration to using this technique, especially with black box classifiers.
Their technique is called LIME (Local Interpretable Model-Agnostic Explanations). Model Agnostic is intended to show that it will work on any classifier, not just DL. ‘Local’ refers to the fact that they ‘perturb’ the data by removing portions of the data (words or images) and then retraining to see the impact.
This graphic illustrates that by removing portions of the tree frog image they were able to determine that the primary area of the image that drove correct classification was the face. Similarly, the same technique showed that the incorrect pool table identification was based on the green background and the similarities of the ‘fingers’ to pool balls. And the balloon classification was based on the association with the shape of the ‘heart’ with balloons.
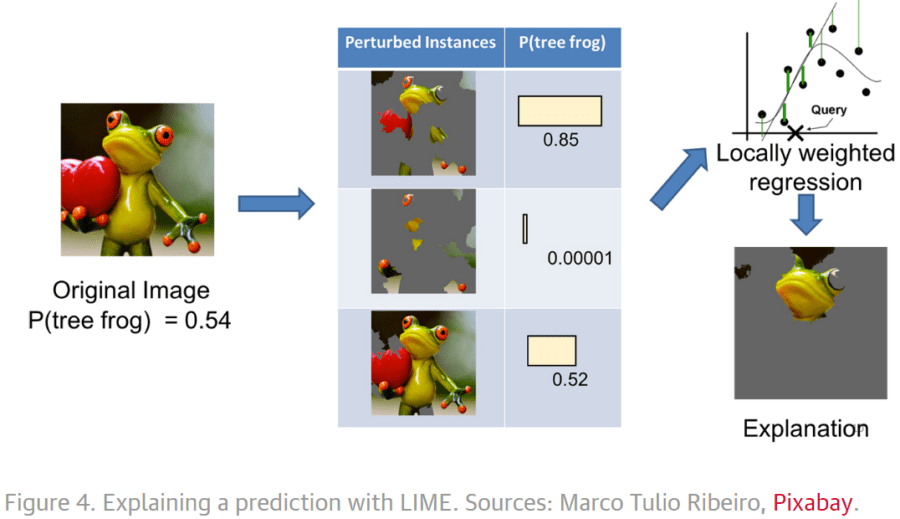
LIME allows the user to correctly identify false correlations (text model above) and reject the model. It also allows the refinement of models (frog image) by biasing the model to focus on the ‘face’.
Ribeiro, Singh, and Guestrin would say this is as much about interpretability as it is about accuracy. It answers the question which happens to be the title of their paper “Why Should I Trust You? Explaining the Predictions of Any Classifier”.
I would add that it’s a great cautionary tale against accepting AUC accuracy measures as ground truth in the age of black box Deep Learning Neural Nets.
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist and commercial predictive modeler since 2001. He can be reached at:
{kind=link}