
Summary: Dealing with imbalanced datasets is an everyday problem. SMOTE, Synthetic Minority Oversampling TEchnique and its variants are techniques for solving this problem through oversampling that have recently become a very popular way to improve model performance.

There are some problems that never go away. Imbalanced datasets is one in which the majority case greatly outweighs the minority case. Years ago we dealt with this by naïve oversampling or, if we had enough data, even under sampling to get the dataset more in balance. These days there are a variety of techniques to use which are becoming more and more mainstream. One things for certain though, if you’re trying something simple like logistic regression chances are your results are going to be terrible unless you preprocess your data to make the classes more even.
Imbalance versus Anomaly
These are two terms that are used without much precision, especially when you get down to the really small end of the range. It’s pretty ordinary to see classification problems where the minority case is only 10% or 20% of total. But the treatments for imbalance that we’re going to discuss cover a much broader range.
- Credit card fraud data is about 1:100.
- Lots of cases like equipment failure, medical diagnosis, factory production defect rates, and many ecommerce selections are in the range of 1:1000.
- Click through rates can be in the range of 1:10,000.
And while there is no firm bottom end to this scale, if you are in the range of 1:100,000 like system intrusions or other extremely rare events then you are most likely in the range of anomalies. We make this distinction because the techniques we’ll discuss here largely involve preprocessing the data to make the classes more even. At some point you’ll need to switch to anomaly detection techniques that include neural nets, single class SVMs, or these days even deep learning. Above that level, consider these techniques.
Your Options – At a High Level
- Just try it. Leave the data alone and run it through your favorite algorithms. Sometimes this will work and at least it will give you a baseline for comparison
- Perform resampling by:
- Oversampling the minority class: We used to do this the naïve way by just copying the minority case examples and adding them to the dataset until we got it even enough. Not anymore.
- Under sampling the majority case: If you’ve got a really big dataset you can consider this. However I always worry about accidentally throwing away some hidden relationships in the data that might actually be valuable.
- A combination of the two.
In practice we’re going to focus on oversampling. That is creation of new interpreted data points, not just copies, which can enhance our ability to separate the minority class as accurately as possible.
Some Practical Tips before You Begin
Judging Performance: Don’t rely on typical accuracy (error rate) measures. Most algorithms are biased to the majority class so you need to be looking at recall (predicted positive / actual positive) and also at the AUC for the ROC curves, both as evaluated on your holdout data.
Resample Your Training Data, NOT Your Validation and Holdout Data: Here’s a common mistake, resampling all the data then selecting your validation and holdout sets. Since we’re basically duplicating minority class data, we could be duplicating the same observation in both the training and validation data. A sufficiently complex model will perfectly predict those repeated items giving the appearance of high accuracy that won’t be true when you run it against your holdout and production data.
It’s Not Necessary that the Datasets be Equal: Some imbalance in the majority/minority datasets is acceptable and even desirable particularly when it means extreme replication of the minority set would be required. You may need to test several variations to find the upper limits of this acceptable imbalance.
Resampling with SMOTE
SMOTE, Synthetic Minority Oversampling Technique (Chawla, 2002) and its several variants will be our focus. There are a number of older options including RandomOverSampler which simply duplicates cases from the minority class. But SMOTE has become a mainstream choice as it tries to enhance the separation between majority and minority classes making the classification more accurate. As a measure of its increasing popularity it’s worth noting that SMOTE has been supported by SAS for several years and has just been introduced as a drag-and-drop GUI by IBM in their latest release of SPSS Modeler. All these are available in both R and Python.
In simple terms SMOTE uses a K-Nearest Neighbor calculation to create additional interpreted data points near the existing minority data.
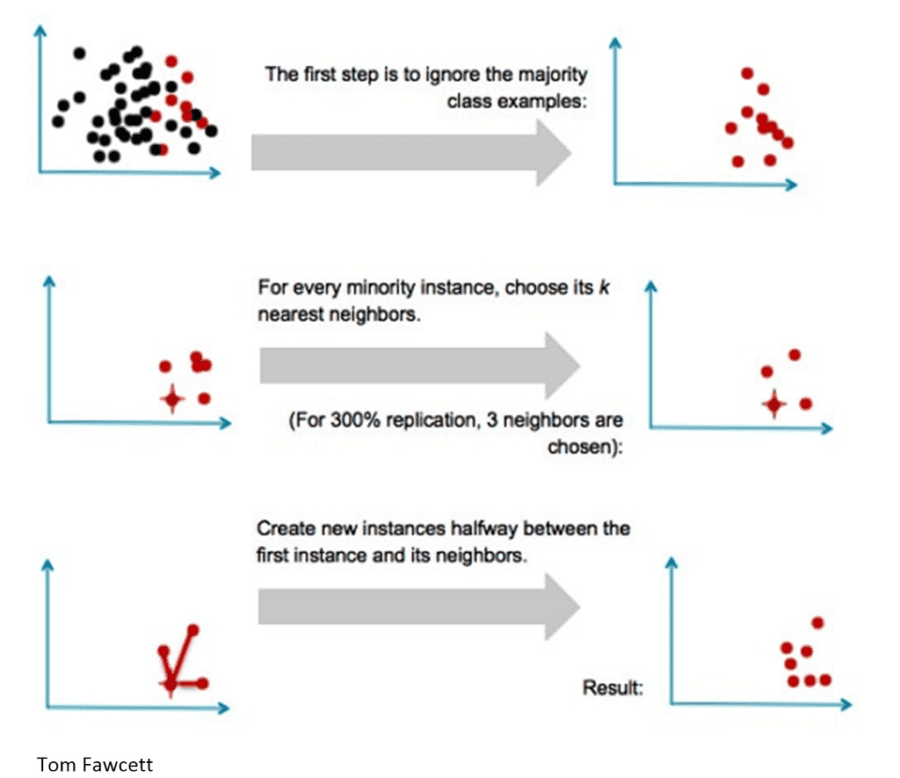
SMOTE Variations
As SMOTE has evolved the development community has recognized that the most difficult problem in imbalanced datasets is correctly defining the border between the two groups. There are four variants that are supported in both R and Python that you can investigate.
SMOTE SVM: Typically employs a neural network with two hidden layers and a dropout layer, trained with categorical cross entropy as the objective and adam as optimizer.
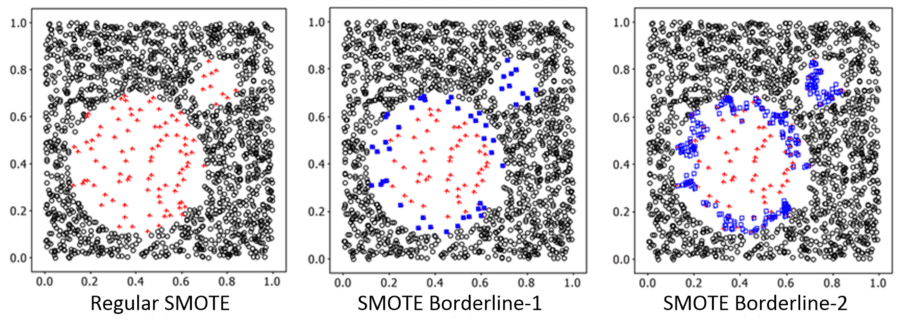
SMOTE Borderline-1 and SMOTE Borderline-2: In these variants only data items that are ‘in danger’ (of confusion between the sets) are considered. In Borderline-1 the assumption is that the interpreted data point is from the class opposite of the one sampled. In Borderline-2 the assumption is that the interpreted data point can be from either class. This is a relatively fine distinction (drawing on the work of Hui Han, et.al. Tsinghua University, Beijing, 2005). This illustration from their original paper shows how the technique focuses on strengthening the borderline between classes.
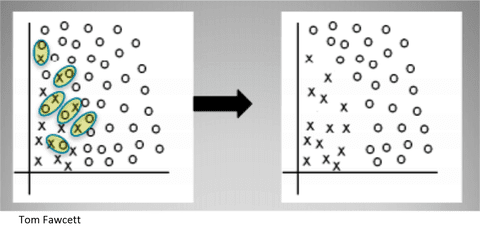
SMOTE Tomek
Tomek links are pairs of data points that are from different classes but are their own nearest neighbors and therefore very close to each other. SMOTE Tomek seeks to clarify the boundary by removing the majority instance in each pair.
The resulting differences from these SMOTE variants appear quite subtle but in practice can have major impact on model performance. You will likely to have to experiment to determine which works best in your case.
There are many other techniques available in both Python and R to address both under and oversampling, and of course, there are other algorithms to try. SMOTE is gaining in both reputation and popularity and it would be a good place to start.
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist since 2001. He can be reached at:
{kind=link}