
Summary: DataOps is a series of principles and practices that promises to bring together the conflicting goals of the different data tribes in the organization, data science, BI, line of business, operations, and IT. What has been a growing body of best practices is now becoming the basis for a new category of data access, blending, and deployment platforms that may solve data conflicts in your organization.
 As data scientists we all potentially suffer from that old hammer and nail meme as we tend to view the world of data through the filters of the ways we use it, predictive analytics, visualization, maybe deep learning and AI. But the more successful our profession becomes and the wider the adoption of our point of view about using data to predict best future actions, the more likely we are to be rubbing elbows with other data-using folks who don’t necessarily share our focus.
As data scientists we all potentially suffer from that old hammer and nail meme as we tend to view the world of data through the filters of the ways we use it, predictive analytics, visualization, maybe deep learning and AI. But the more successful our profession becomes and the wider the adoption of our point of view about using data to predict best future actions, the more likely we are to be rubbing elbows with other data-using folks who don’t necessarily share our focus.
I’m talking about all those others folks in the enterprise who use data for BI reporting of past conditions, data analysts assigned to keep those line of business users up to date with their required reports, the DevOps guys and gals building applications not necessarily related to data science, the citizen data scientists who sometimes view us as a bottleneck, and oh yes, those long suffering folks in IT on whose shoulders a lot of this rests. Think of all these as separate tribes competing for those data resources.
The problems this competition for data and its supporting resources creates aren’t new. Missed SLAs, confusion over a common version of the truth, and oh those squirreled away spreadsheets with data blended and sculpted into those analyses that no one else can access. All this has a business cost as well as being a source of stress for all involved. This cries out for a solution.
In the Past
In data science the availability of end-to-end analytic platforms has brought with it the ability to access almost unlimited internal and external data sources, to blend, cleanse, analyze, model, visualize, and deploy. But only if you’re a data scientist or citizen data scientist/analyst. And while these platforms can create repeatable workflows, they don’t work to the benefit of the BI or DevOps teams.
Then there’s Master Data Management (MDM), aka Data Governance. These are controls, procedures, and standards programs largely created by IT in an attempt to corral the anarchy, with an emphasis on control. A relatively small percentage of organizations have successfully implemented MDM. Its focus was always ‘master data’ and it didn’t solve all the other associated problems.
Each of these data-using tribes has its own tools and work arounds but a whole-organization perspective has been missing.
What is DataOps?
DataOps by itself isn’t new though it is undergoing a major expansion in scope. In 2012 and 2013 mentions of DataOps were found mostly in digital marketing confines having to do with getting data from a large number of sources including some unstructured into a RDB for future analysis and operational use, basically ETL and blending with unstructured data.
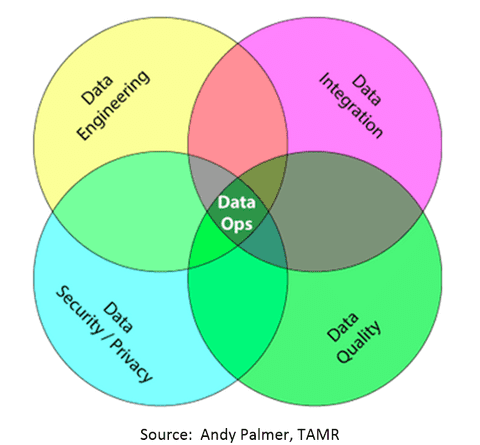 In the following few years IoT and other types of data in motion are often mentioned and since this is all now Big Data, the folks doing the promoting are often the NewSQL crowd of databases that can ingest unstructured data but retain some of the capabilities of RDBMS.
In the following few years IoT and other types of data in motion are often mentioned and since this is all now Big Data, the folks doing the promoting are often the NewSQL crowd of databases that can ingest unstructured data but retain some of the capabilities of RDBMS.
DataOps really blossomed following the formalization of DevOps in about 2013 because it was recognized that the same problems solved and principles used in DevOps could be adapted to data availability.
However, finding a consistent definition and scope for DataOps is a lot like the five blind men and the elephant, the definition has a lot to do with the professional perspective of the writer, be it BI, operations, or IT. Today, DataOps is a series of data management principles organized into a kind of loosely agreed manifesto. Here’s a reasonably good definition from Jack Vaughan in a 2017 techtarget post.
“DataOps (data operations) is an approach to designing, implementing and maintaining a distributed data architecture that will support a wide range of open source tools and frameworks in production.
A DataOps strategy, which is inspired by the DevOps movement, strives to speed the production of applications running on big data processing frameworks. Like DevOps, DataOps seeks to break down silos across IT operations and software development teams, encouraging line-of-business stakeholders to also work with data engineers, data scientists and analysts so that the organization’s data can be used in the most flexible, effective manner possible to achieve positive business outcomes.”
To offer more specifics, few people have written more about DataOps than Toph Whitmore, Principal Analyst at Blue Hill Research. He offers these DataOps leadership principles which he assigns to IT.
- “Establish progress and performance measurements at every stage of the data flow. Where possible, benchmark data-flow cycle times.
- Define rules for an abstracted semantic layer. Ensure everyone is “speaking the same language” and agrees upon what the data (and metadata) is and is not.
- Validate with the “eyeball test”: Include continuous -improvement -oriented human feedback loops. Consumers must be able to trust the data, and that can only come with incremental validation.
- Automate as many stages—even BI, data science, and analytics, when possible—of the data flow.
- Using benchmarked performance information, identify bottlenecks and then optimize for them. This may require investment in commodity hardware, or automation of a formerly-human-delivered data-science step in the process.
- Establish governance discipline, with a particular focus on two-way data control, data ownership, transparency, and comprehensive data-lineage tracking through the entire workflow.
- Design process for growth and extensibility. The data flow model must be designed to accommodate volume and variety of data. Ensure enabling technologies are priced affordably to scale with that enterprise data growth.”
There are entire conferences devoted to DataOps so there is broad agreement on the principles involved.
What’s New and Why Is It a Secret?
 The first time I ran into DataOps was the March Strata+Hadoop conference in San Jose. Every year I make my way methodically around the display floor specifically looking for anything I haven’t seen before. And there it was, two new vendors side-by-side displaying for the first time their new “DataOps” software platforms.
The first time I ran into DataOps was the March Strata+Hadoop conference in San Jose. Every year I make my way methodically around the display floor specifically looking for anything I haven’t seen before. And there it was, two new vendors side-by-side displaying for the first time their new “DataOps” software platforms.
As recently as this year, 2017, Jack Vaughan quoted above went on to say “As with DevOps, there are no “DataOps” software tools as such; there are only frameworks and related tool sets that support a DataOps approach to collaboration and increased agility.”
So what’s new is that there’s a whole new category of software platforms that specifically takes the DataOps title and is now promoting itself as central to data science, at least insofar as we’re one among the many tribes of data users that need to cooperate in order to succeed.
What’s secret is that this category is still so new that neither Gartner nor Forrester have reviewed it making it difficult to discover exactly who the players are and their relative strength and positioning. Gartner and Forrester do have a category identified as ‘Data Wrangling’ but this appears to be more narrow than DataOps and focused on data science and not the other users.
As research organizations go, it appears that only Blue Hill Research and our previously credited analyst Toph Whitmore is covering this segment. They’ve written quite a bit about the characteristics and principles to be employed but very little in the way of competitor information.
Who Are the Players?
First, this is not intended to be an exhaustive list. It’s drawn from my Strata observations, some Blue Hill research, and examination of participants in some of the larger DevOps conferences. For specifics about their relative strengths and weaknesses you’ll need to dig in at their respective web sites.
Second, there is disagreement on the scope of what a DevOps platform should provide that is not examined here. At one extreme are what appear to be end-to-end platforms that provide a structure for implementing the principles mentioned above, and that extend beyond access, blending, cleaning, and storage to, in some cases, model building and deployment. At the other extreme are providers whose offerings cover only a portion of the whole DevOps data discipline.
Here’s a brief listing of DevOps providers that I could identify.
- Composable Analytics
- Data Kitchen
- DataOps
- Interana
- Nexla
- Qubole
- Trifacta
- Unravel Data
My bet is that it won’t be long before the major DB providers incorporate these same features.
You’ll Know You’re Ready for DataOps When…
Arguably the biggest winners in a properly implemented DataOps environment are the line of business users. DataOps should eliminate questions about ‘single version of the truth’ that may cause your predictive analytics and the company’s BI reports to disagree.
It also is intended to ensure that everyone’s data needs are met on time regardless of which data tribe you inhabit. And anything that reduces that 50% to 80% of the time we data scientists devote to wrangling the data would be welcome.
Another big winner will be IT Operations where the finger inevitably points when data bottlenecks arise. DataOps gives them the process and controls they so dearly need but arrived at through a cooperative governance structure involving all the users and providers.
One way to look at it is that the world has been divided into two competing camps. On our data science and BI side, the goals have been exploration and exploitation leading to more-is-better, driving self-service applications, promoting temporary and quality challenging improvisations like data lakes, and ad hoc blending.
On the operations side it’s been about protection, privacy, security, accuracy, and efficiency that has promoted the world of controls, restrictions, and process inefficiencies that have held us back from our all-you-can-eat goals.
DataOps provides a structure that promises to reconcile these two positions and give us the best of both.
About the author: Bill Vorhies is Editorial Director for Data Science Central. and has practiced as a data scientist and commercial predictive modeler since 2001.
{kind=link}