
By Jean-Jacques Bernard and Ajit Jaokar
This set of blog posts is part of the book/course on Data Science for the Internet of Things. We welcome your comments at jjb at cantab dot net. Jean-Jacques Bernard has been a founding member of the Data Science for Internet of Things Course. Please email at ajit.jaokar at futuretext.com if you are interested in joining the course.
Introduction
The rapidly expanding domain of the Internet of Things (IoT) requires new analytical tools. In a previous post by Ajit Jaokar, we addressed the need for a generic methodology for IoT Analytics. Here, we expand on those ideas further.
Thus, the aim of this document is to capture the specific elements that make up Data Science in an Internet of Things (IoT) context. Ultimately, we will provide a high level methodology with key phases and activities with links to specific templates and contents for each of those activities.
We believe that one the best methodologies for undertaking Data Science is CRISP-DM. This seems to be the views of a majority of data scientists as the latest KDnuggets poll shows. Therefore, we have loosely based the methodology on CRISP-DM.
We have also linked the methodology to the technical framework proposed [above] (Data Science for Internet of Things – A Problem Solving Methodology) which aims at providing a technical framework for solving IoT problems with Data Science.
The methodology we propose is divided in the following 4 phases:
- Problem Definition
- Preparation
- Modelling
- Continuous Improvement
We describe the first 3 phases in this post before describing the last phase and the detailed activities and deliverables encompassing each phase in upcoming posts.
The relationships between the first three phases are presented in the figure below.
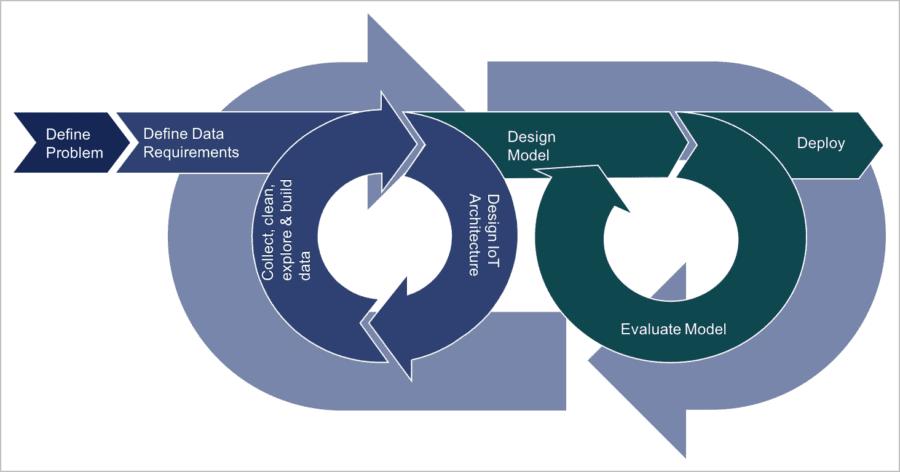
High level description of the methodology
Problem definition
This first phase is concerned with the understanding of the problem. It is important to define the terms here in the context of IoT.
By problem, we really mean something that needs to be solved, addressed or changed, either to suppress or revert a situation or create a new situation. Of course the end situation should be better than the initial situation. In the context of IoT, solving a problem means solving the initial problem and providing incremental feedback.
In any business context, to manage scarce resources, it is necessary to provide a business case for projects. Thus, it is important to define an IoT Analytics business case, which will provide a baseline understanding (i.e. measurement of the initial situation) of the problem through Key Performance Indicators (KPIs). In addition, the business case must provide a way to measure the impact of the project on the defined KPIs as well as a project timeline and project management methodology. The timeline and project management methodology should include deployment, a critical activity for large scale IoT Analytics projects.
The baseline and the measurement of the impact will be used to understand whether the IoT Analytics has reached its goals.
For instance, in the case of a Smart City project aiming at reducing road congestion, KPIs like number of congestion points and average duration of congestion at those points can be used to understand whether the project had a positive impact or not.
However, defining the problem and understanding how to measure it might be harder than it sounds as pointed here and here.
Preparation
The second phase of the methodology is concerned with data collection, preparation (i.e. cleaning) and exploration. However, in the context of IoT, the sources of data are more diverse than in other data science set-ups, and there are also elements of architecture to consider before starting more classic exploratory type of work.
Therefore, we believe there are three types of activities in this phase:
- Define the data requirements
- Select and design the IoT architecture
- Collect, clean, explore and build data
And those three activities are to be conducted in an iterative manner, until the data build fits the problem we are trying to solve.
First we need to define the data needed to solve the problem defined previously as well as its characteristics. We need to do so in the context of the IoT vertical we are working in. Examples of IoT verticals include (not exhaustive):
- Smart homes
- Retail
- Healthcare
- Smart cities
- Energy
- Transportation
- Manufacturing (Industrie 4.0 or Industrial Internet)
- Wearables
The selection and design of the IoT architecture focuses on two parts: the network of devices and the processing infrastructure.
The first part is concerned with the set-up of the network of devices that will be used to measure and monitor some parameters of the environment of the problem. The design of this network is outside the scope of this article, but it is nonetheless important (for more information on this topic, you can refer to this article from Deloitte University Press). Some of the key considerations are:
- Availability & security
- Latency & timeliness
- Frequency
- Accuracy & reliability
- Dumb vs. smart devices
Those elements will determine some of the characteristics of the data that will be collected from the network of devices (in essence, this is a kind of meta-data). Those characteristics will be used to establish the processing infrastructure.
For instance, these are those characteristics which will help in choosing whether edge devices need to be used, whether event collectors are best suited, etc. For more information, see our article for an in-depth treatment of what potential processing infrastructures for IoT can be.
Then the final activities are the collection, cleaning and exploration of the data available. This is typical data analytics type of work, where the practitioner clean up the data available, and explore what are the properties of the data, etc. It is also a step where additional data can be build on the basis of the data available. However, this is also a step where it can become clear that the data provided by the IoT architecture is neither enough nor processed in a correct way.
This is why this phase is an iterative one, the learnings from the last step can be used to refine the IoT architecture until the data fits the problem to be solved.
Modelling
The modelling phase is the phase where a models are built and evaluated, both from a statistical standpoint and from a problem solving standpoint. It is composed of three activities:
- Design model to solve the problem
- Evaluate the model
- Deploy the model and the architecture
Like for the preparation phase, those activities are to be conducted in an iterative manner, until the model:
- Is statistically sound;
- Shows potential to solve the problem (i.e. impact on KPIs defined in the problem definition phase).
In this phase, the data scientist will choose among different types of algorithms, depending on the problem to solve and build models using those.
As described in the previous article, many algorithms and techniques are applicable, such as time series analytics, complex event processing (CEP) or deep learning. An important element, linked to the activities from the previous phase, is where will the analytics be applied. While this should be part of the design of the IoT architecture, this while guide the choice of algorithm to apply. Indeed, we can apply analytics at:
- The device (if we use smart devices)
- The edge
- The data lake / Cloud
- Etc.
In addition, the type of analytics will depend on the type of processing we are focusing on: batching vs. streaming.
When the model has been designed, then comes the evaluation activities, which should first evaluate the model using classic statistical and data science techniques: using training, validation and testing datasets, minimizing bias and variance and trading-off precision and recall.
Then, the model should be evaluated from a business point of view: does it improve the KPIs that were set during the problem definition phase? It might not be obvious to measure the improvement until the model is deployed, thus, it is important to keep an improvement loop over this phase and the previous. If the model does not improve the KPIs defined in the problem definition phase, then it is necessary to rework from the preparation phase since some of the assumptions underlying the data may be wrong.
When the model is considered as sound and solves the problem it was designed to solve, it is time to deployed it together with its IoT Architecture. The deployment of the architecture and model is a project in itself and should come with its own project management structure and timeline, as defined in the problem definition phase.
In upcoming posts, we will present the continuous improvement phase and explore the detailed activities and deliverables of each of the phases presented here.
To conclude on this post, we welcome your comments. Please email ajit.jaokar at futuretext.com if you are interested in joining the course.
{kind=link}