
Oh,the lowly data engineer. Harvard Business Review declared the role of the data scientist as “the sexiest job in the 21stcentury.” But the data engineer labors away in near obscurity acquiring, transforming, enriching, munging and preparing data for the data scientist to do their black magic.
In addition to building data pipelines – who do you think operationalizes the data science? Again, it’s the data engineer.
We have helped data engineers deploy machine learning models and operationalize data science for some time. Using the Pentaho Data Pipeline, we enable the lowly data engineers to leverage existing data and feature engineering efforts, thereby significantly reducing time-to-deployment. With embeddable APIs, organizations can also include the full power of Pentaho within existing applications.
Good news for the Data Engineers, you can now be even faster and better organized at getting things done! Now you have a tool to dance the tango and mambo with the data scientists like Johnny and Baby. At Hitachi NEXT today in San Diego I had a chance to attend some of the Pentaho sessions and visit their booths at the exhibit hall. I was excited to see new capabilities such as integration with Jupyternotebooks – an advanced data science development tool, orchestration of analytic models written using TensorFlow and Keras machine learning libraries, and simplified analytic model management.
Here is what I learned:
1) Integration with Jupyter Notebooks
Data scientists are most comfortable working in their IDEs and spend a lot of time writing scripts to prepare data to feed the models they are exploring. To address this, we have validated a best practice for data engineers to access, cleanse, integrate and deliver data as a service for use by data scientists.
Rather than manually create and maintain one-off scripts to access, massage and wrangle data assets, data scientists can now focus on the more intellectually rewarding part of their jobs – model exploration. They can concentrateon developing insightful and accurate analysis in the familiar IDE of a Jupyter Notebook, an incredibly powerful and popular tool for contemporarydata science, and leave data preparation and integration to data engineers. Using the drag and drop interface in Pentaho Data Integration (PDI), data engineers can create transformations that result in governed data sources that they can registerin an enterprise data catalog to promote reuse across data engineering and data science teams – fostering a more collaborative working relationship.
Data Scientists canaccess fresh production data rather than older test data for further model exploration and tuning to keep accuracy high. Once the data scientist is ready for their model to be operationalized in a production environment, the data engineer can make minor modifications to the pipelines created in a development environment to make them production ready.

Figure 1. Integrate PDI Transformations with Jupyter Notebooks
2) Orchestrating TensorFlow and Keras Models
While data engineers have in-depthknowledge of and expertise in data warehousing, SQL, NoSQL, andHadoop technologies, in most cases they do not have the Python or R coding skills. They most likely do not have the advanced math and statistics skills required to tune machine learning and deep learning models to getthe most accurate models into production faster. We recognized this, andhave now added an enterprise-gradetransformation step that helps data engineers embed deep learning ML models into data pipelines without coding knowledge.
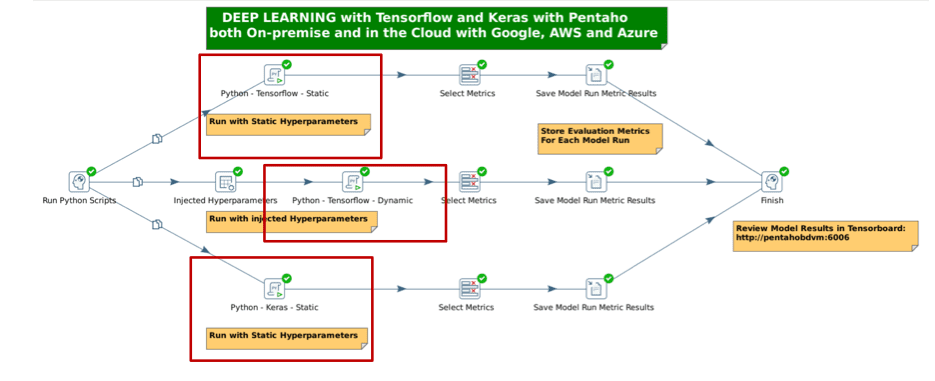
Figure 2. Using Python executor steps to orchestrateTensorFlow and Keras Models
3) Improved Model Management
Typically models degrade in accuracy as soon as they hit production data. With our new Python execution step, users can make updates to models using production data. Data Engineers can gain insight into model usage, run champion-challenger tests, review model accuracy statistics and easily swap in the models with the highest accuracy. By keeping the most accurate models in production, organizations will make better decisions and reduce risk.
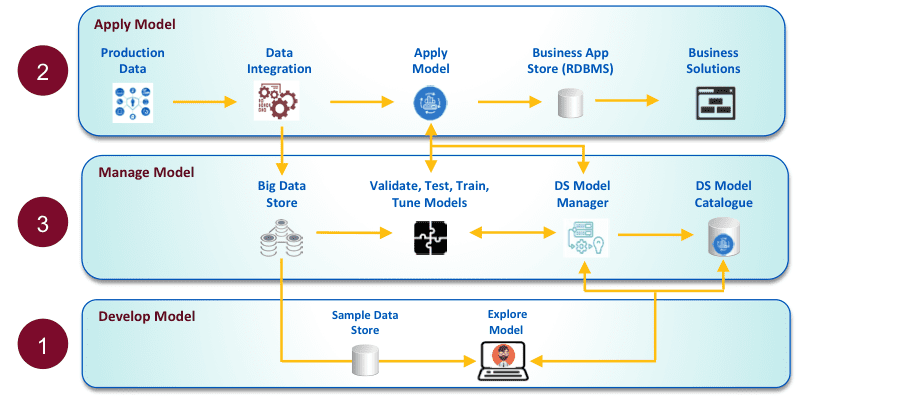 Figure 3. Model Management Reference Architecture
Figure 3. Model Management Reference Architecture
The reference architecture above in Figure3 outlines the steps involved to manage a model in an enterprise setting effectively. It begins with the data scientist looking for data to create the model and requesting the data engineer to provide him with a governed data source. The data engineer establishesthis source, makes minor adjustments to the pipeline and reuses it when it comes time to operationalize the model. Both data scientists and data engineers collaborate closely to manage and catalog champion and challenger models, creating enterprise assets that can be reused in the future.
Summary:
Analytics and data science are the monetization engines of the future. We all know that data-driven and increasingly, model-driven, firms will run the world. However, taking analytics mainstreamposes data operations challenges for data engineers.
Having a platform that drives collaboration between your data engineers, data scientists and business stakeholders is one of the keys to helping organizations become more effective at using data to drive innovation, strong business outcomes and entirely new business models.
Give the data engineers that they need to support the data science monetization efforts, and everyone will have the time of their lives!
{kind=link}