

Here’s a hypothesis: Smart data (enriched with metadata that makes it connectable with other data, Tinker Toy style) might be fungible in ways that dumb data isn’t.
For exchange and reuse purposes, can data be “fungible” at all? Consider this excerpt from an explainer on the Cointelegraph.com site:
“Fungible tokens or assets are divisible and non-unique. For instance, fiat currencies like the dollar are fungible: A $1 bill in New York City has the same value as a $1 bill in Miami. A fungible token can also be a cryptocurrency like Bitcoin: 1 BTC is worth 1 BTC, no matter where it is issued.
“Non-fungible assets, on the other hand, are unique and non-divisible. They should be considered as a type of deed or title of ownership of a unique, non-replicable item. For example, a flight ticket is non fungible because there cannot be another of the same kind due to its specific data. A house, a boat or a car are non-fungible physical assets because they are one-of-a-kind.”
Part of the problem with this definition of fungibility is its tight association with currency. Imagine you have a flow of data. Unique, fungible assets could conceivably be part of that data stream.
In other words, exchangeable, unique assets could be blended in with other non-unique data, in the same data stream. Why would you even want to do this kind of blending? Maybe you want to encourage consumption of that data stream. Say an advertiser wants to display an ad, or a pitchman deliver a pitch. Maybe the consumer would be promised an NFT in exchange for listening to the pitch and providing some feedback.
Data assets and behavior
At a minimum, data, unless it’s just exhaust that’s not reused, is clearly an asset.
Art Kleiner and Juliette Powell have just finished a book called the AI Dilemma that’s slated for release in August 2023. It’s a book written for business executives.
I gave an interview for the book, and we’ve had some email exchanges during the course of the book writing and production process on AI and data trends. Most recently, Art, whom I know from his days as the Editor-in-Chief at Strategy & Business, made these observations:
I keep thinking of Juliette’s line “you are what you reveal.” That increasingly translates to: “anything you do is data about you.”
If I’m correct in my interpretation (which I may not be), you’re saying that a data-centric architecture would imply, “all data are assets, and need to be tagged as assets. You automatically own what you reveal.” Whether you monetize it or not, in a world that recognizes data as assets, the data is linked back to you.
This would start companies managing their data as the decision point (the new unified data-first IT replacing the old fragmented algorithm-first IT), but it wouldn’t stop at corporate boundaries. As data moved along supply chains and through transactions, data holders would feel compelled to adopt the standard, to become interoperable.
Art and Juliette’s observations made me realize that businesspeople can guide technologists in more ways than they know, particularly when it comes to data.
Data as an organic, growing, and flowing resource
To use a materials metaphor, “data” is silica to many data scientists. It’s inert and inorganic. You have to add metal and heat to make electrically active silicon wafers out of it. Otherwise, it’s just sand, and not a renewable resource in any case.
What more intelligence in the data makes possible is the organic, dynamic, interactive representation of the living world.
This representation is what Wired Co-Founder Kevin Kelly calls the Mirrorworld. Twitter, LinkedIn and other social networks have been a starting point for that sort of interactive, growing, farming and harvesting environment.
The Mirrorworld is a misnomer in some ways. Data doesn’t just mirror what it represents. It serves as a lifeblood for the digital environment.
These folks are wrapping the world in an evolving, multi-use operating and resource sharing environment using web principles. Data is the evolving resource that informs this operating and resource sharing environment.
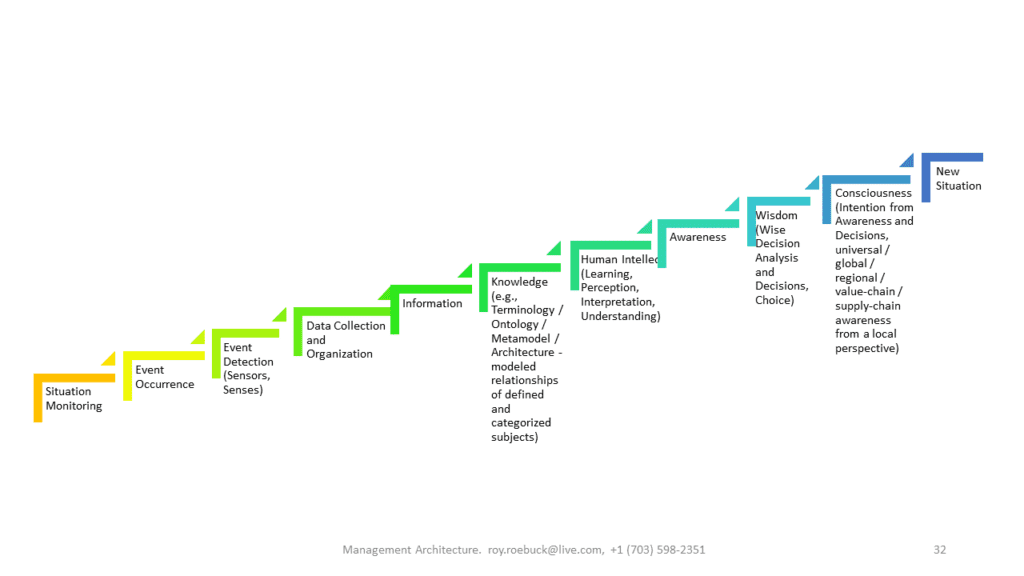
Independent knowledge graph consultant Roy Roebuck describes the data evolution challenge that enterprises face as one with multiple layers. “Data with added context or meta provides information. Each layer of this consciousness progression is built by assigning context to the previous layer. Beyond the knowledge layer is where humans, and potentially A.I. constructs, would build their consciousness.”
Building blocks of recorded intelligence
Instead of thinking in terms of how to automate business functions by handing them off to machines and third parties, it’s best to think in terms of a pervasive, machine assisted human-in–the-loop scenario.
The question becomes, how can we empower humans and take advantage of machine-based effectiveness and efficiency at the same time?
Fleshing out the data asset
Data can express its own utility, contextual relevance and parameters monetization and exchange, as well as other attributes. Agents and humans together can be the actors who nurture the data and put it to use.
The intelligence, relevance and interoperation details can reside in the data, with the functions enabled by agents brokering interactions between machine and human actors, after all. The ideal situation from an efficiency perspective is to create intelligent data executing agents designed to live and thrive in the web environment, harnessing the functionality of the larger environment.
The web in its first and third incarnations (a.k.a., the “webby way” David Weinberger, et al. described in 2001’s The Cluetrain Manifesto, and so called “web3” or the decentralized web of today—see One Big Graph and the Interorganization (https://www.datasciencecentral.com/one-big-graph-and-the-interorganization/) are examples of how collaboration can be less siloed.
Design and create once, use everywhere helps all participants in the ecosystem. So why not have one ecosystem, or one virtualized model of what exists so that we can quantify and manage each of its component parts for efficiency, effectiveness and net impact on the living world?
{kind=link}