
 Measuring the similarity between texts is a common task in many applications. It is useful in classic NLP fields like search, as well as in such far from NLP areas as medicine and genetics. There are many different approaches of how to compare two texts (strings of characters). Each has its own advantages and disadvantages and is good only for a range of specific use cases. To help you better understand the differences between the approaches we have prepared the following infographic.
Measuring the similarity between texts is a common task in many applications. It is useful in classic NLP fields like search, as well as in such far from NLP areas as medicine and genetics. There are many different approaches of how to compare two texts (strings of characters). Each has its own advantages and disadvantages and is good only for a range of specific use cases. To help you better understand the differences between the approaches we have prepared the following infographic.
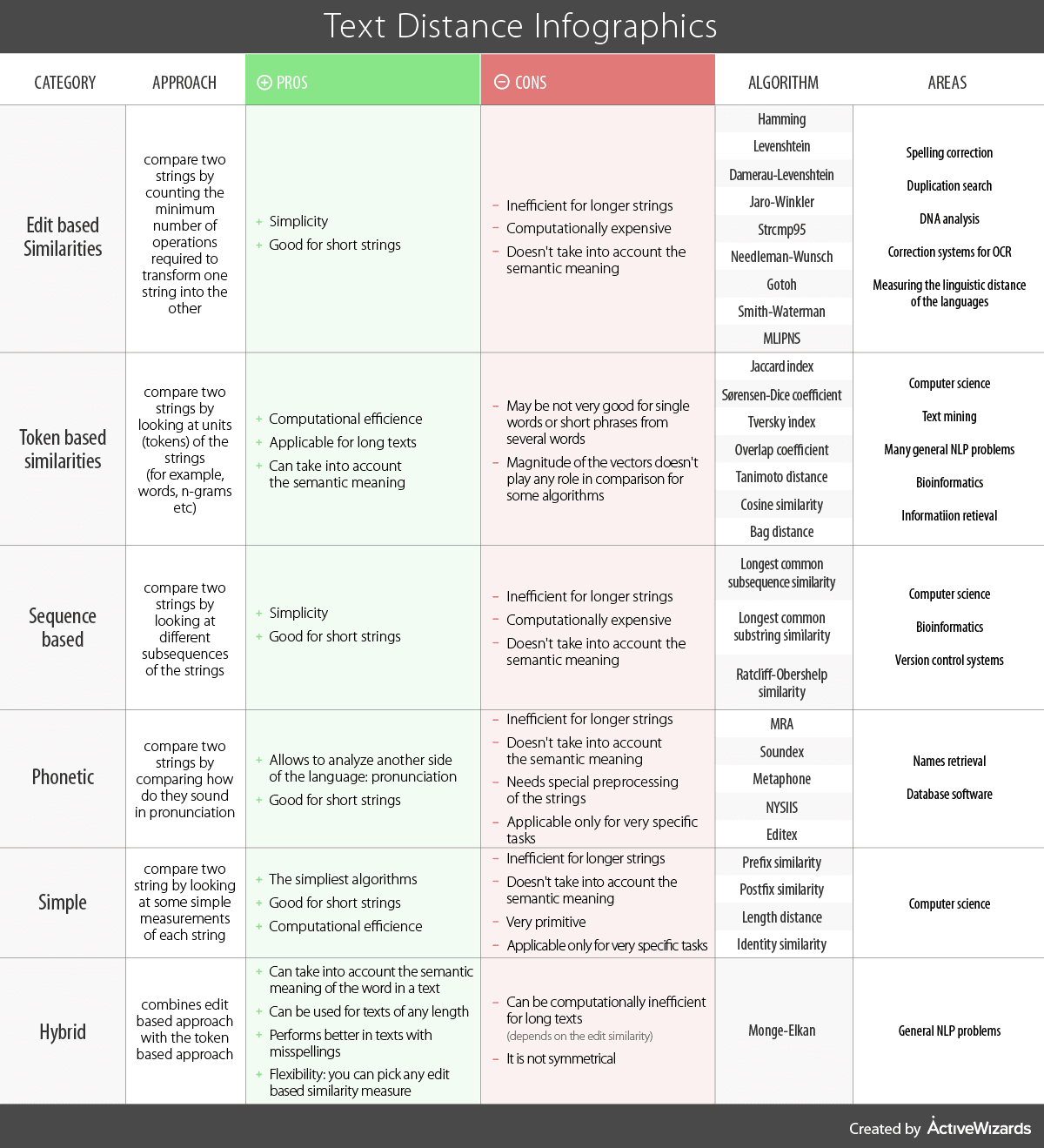
We highlight 6 large groups of text distance metrics: edit-based similarities, token-based similarities, sequence-based, phonetic, simple, and hybrid. The core features of each category are described in the infographic. Here, we just want to explain some nuances.
Edit based similarities are simple to understand. The more atomic operations you should perform to convert one string into another, the larger distance between them is observed. For example, the distance between words “hat” and “cat” is 1, and the distance between “map” and “cat” is 2. It is obvious that this approach is applicable only for words and short phrases but useless for longer texts. Also, this approach cannot take into account the semantic meaning of the words, because it compares only the characters. In the same time, we understand, that semantic distance between “lemon” and “apple” is less than between “lemon” and “moon” despite the fact that edit distance between “lemon” and “apple” may be greater than the distance between “lemon” and “moon”. That’s why edit based distances are used in the applications, where semantic meaning is not such important as similarity in writing. It is also worth to say that the most prominent edit based algorithm is the Levenshtein algorithm. Very often people think about edit based distances as about Levenshtein similarity.
Token-based similarities are a little bit more complex. Those analyze text as a set of tokens (words). This allows to take into account the semantic meaning of the words and to process large texts. Semantic meaning plays a role here because you can use word vector representations (word2vec) to describe each word in the text and then compare vectors. Also, using a bag of words approach and TF-IDF method allows comparing the semantic similarity between entire texts (although not between independent words). Token-based similarities are very widely used in different areas. Probably, it is the most well-known approach to work with texts. Nevertheless, it is not applicable to a range of use cases.
The next group of distance is sequence based distances. It is somewhat similar to edit based distances, but not completely the same. You may be guessing what is the difference between comparing strings on the basis of the longest common subsequence and the longest common substring. Longest common subsequence doesn’t take into account if there are some letters between characters from subsequence. For example, consider sets of letters “aebcdnlp” and “taybcrd”. The longest common subsequence between these words is “abcd”, while the longest common substring is only “bc”. The fields of application for these approaches are slightly different from edit based approaches, but the pros and cons are almost the same.
Phonetic algorithms form a separate group of methods for string comparison. In this case, it is not even string comparison but rather an audio comparison. These algorithms compare words based on how they are pronounced. It is hard to compare long texts in this way. The short sentences or phrases are the maximum threshold for these algorithms. Also, they cannot take into account the semantic meaning. Nevertheless, there are situations when these methods are indispensable.
The next several algorithms we want to mention are very simple to understand and use, so they form a group of methods which can be called as “Simple”. These methods can compare strings based on the similar prefixes or postfixes. Also, there are algorithms called “length distance” and “identity similarity”. The first ones compare strings by counting the number of characters in each of them and the second algorithms simply check if these strings are completely the same or not. As you can see, all these algorithms are very primitive and can be used only in very specific situations.
The last group we want to describe is hybrid algorithms. There is only one method: Monge-Elkan. It is a mix of edit based and token based distance. You can choose any edit based algorithm. The Monge-Elkan method compares each word in one text with each word in another text (so it is token-based), but when comparing words it uses some of the edit based methods (so it is edit-based at the same time). Then, distances between words are aggregated to derive a single value of the distance between the two texts. One important thing here is that this method is not symmetrical. This means that the result of comparison depends on what string you take as the first string and what as the second one. We describe this situation in the cons section of our infographic, but actually, it is not a problem for all applications. In other words, there are many use cases where symmetry is not important.
Conclusion
In this article, we have briefly described some interesting and important notes about different approaches to strings comparison. To understand and remember all these things better, please explore our infographics. There are no good or bad approaches, all of them appeared due to the need of using in particular cases. So, when you need to compare two strings, firstly think about what is the final result you expect to have, and then choose the right metric. Use our infographics as a cheat sheet!
{kind=link}