

Vendors, consultants, and their clients have been talking in data fabric terms for close to a decade now, if not longer. If “big data” was the problem to solve, then a data fabric suggested a ready solution. John Mashey, then chief scientist at Silicon Graphics, used the term “big data” to describe the wave of large, less structured datasets and its impact on infrastructure in a slide deck in 1998. Apache Hadoop gained popularity after an engineer at the New York Times wrote a blog post in 2009 about automating a PDF integration task using Hadoop.
The term “data lake” came into vogue in the early 2010s to describe an informal means of making data of various kinds accessible to analyst teams. The early data lakes involved a Hadoop-oriented distributed repository (a la Yahoo’s 10,000 node cluster, inspired by Google’s earlier internal distributed commodity clusters and its File System) for simple analytics.
When enterprises often seemed to neglect their data lakes, critics were quick to label them “data swamps”. But adoption of data lakes continued unabated, in part because data warehouses often weren’t being managed all that well either.
Data fabrics
By 2014, SAP was using “in-memory data fabric” to describe a virtual data warehouse, a key element of its HANA “360-degree customer view” product line. Gartner for its part uses the term “data fabric” to this day as an all-encompassing means of heterogeneous data integration. From a 2021 post on data fabric architecture:
“[Data fabric] is a design concept that serves as an integrated layer (fabric) of data and connecting processes. A data fabric utilizes continuous analytics over existing, discoverable, and inferenced metadata assets to support the design, deployment, and use of integrated and reusable data across all environments, including hybrid and multi-cloud platforms.
“Data fabric leverages both human and machine capabilities to access data in place or support its consolidation where appropriate. It continuously identifies and connects data from disparate applications to discover unique, business-relevant relationships between the available data points.”
Gartner publishes reports on “AI-enabled” data management and how the data management landscape is changing. “Data fabric” thus becomes shorthand for newer, more capable data management techniques.

Data meshes
Director of Emerging Tech Zhamak Dehghani at Thoughtworks and her team came up with the concept of a “data mesh” as a distributed, domain-articulated alternative to data warehouses and data lakes. The highest-level metaphor Thoughtworks uses involves two data planes–one operational, and the other analytical. A (mostly extract>load) data pipeline connects the two planes. Means of reporting and visualization, including SQL and dashboarding, are in turn connected to the analytical plane.
Thoughtworks’ data mesh concept concentrates on a domain-oriented rather than monolithic approach to analytical architecture. Domain data owners become responsible for delivering their data as a product to users. “Data as a product” signifies that the data offered has the necessary quality, integrity, availability, etc. for users to be able to depend on it.
A data product is an “architectural quantum”, according to this view. Such a product is the smallest unit of architecture that can function cohesively on its own. Each product for this reason includes its own code, data, metadata, and infrastructure.
An overarching goal of a data mesh platform composed of these domain-specific quanta is scalable self-service analytics. Each platform contains three planes: one for infrastructure provisioning, a second for developer experience, and a third for supervision. In addition to the supervision plane in each platform. Thoughtworks also envisions an elaborate federated governance umbrella to institute and manage policies across platforms.
The data mesh concept is still in its early stages. Enterprises who’ve explored data meshes say that a data mesh is not a destination, but a journey. Much of the initial effort goes into finding, determining the best use of, and allocating the resources a data mesh demands. Tareq Abedrabbo, Principal Core Data Engineer at trading platform provider CMC Markets when interviewed by InfoQ described the data discovery challenges CMC faced for its data mesh. For example, the concept anticipated decentralized data, but query methods such as SQL require centralization.
Knowledge graphs
The term knowledge graph started to gain popularity ever since Google coined the term in 2012. Over the course of the past decade, more than 90 percent of the world’s tech sector giants have built and used knowledge graphs. Leaders in pharma, government, financial services, manufacturing, and online retail all use knowledge graphs.
The classic and most prominent implementations of knowledge graphs use evolutions of the semantic web stack, which has developed and matured over two decades. Tim Berners-Lee’s original inspiration for semantic web was a “web of data”, with content, ontologies, and relational data all described in the same entity + relationship or subject-predicate-object articulated manner.
There are many other conceptualizations of knowledge graphs, too many to list in a short blog post. Quite a few of these alternatives envision full automation via standalone statistical NLP and related methods that haven’t been proven to stand on their own.
The main difference between the three approaches I’ve described above has to do with the origins and objectives of each approach:
A Google Trends analysis of search popularity for the three terms over the past year ranks knowledge graphs first, data meshes second, and data fabrics third.
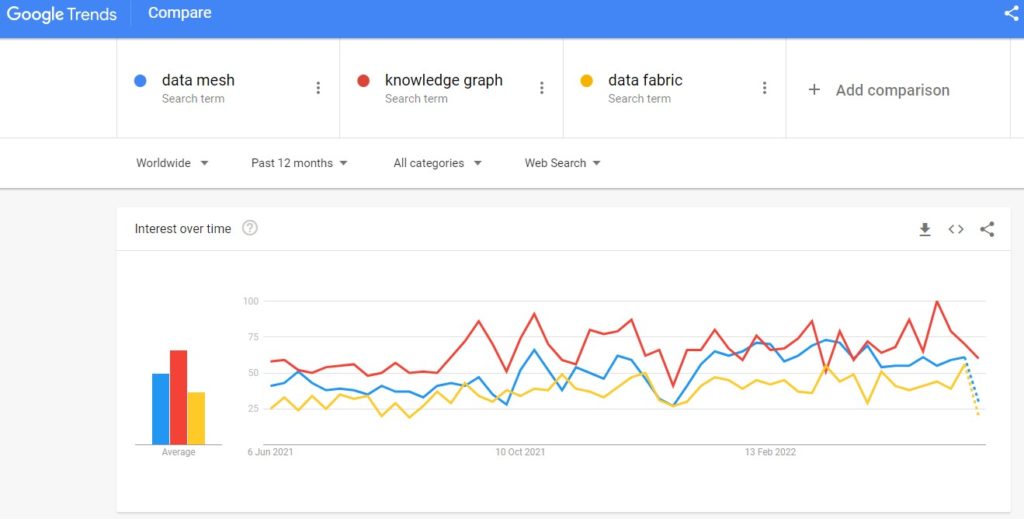
None of these approaches is easy to adopt. A data fabric involves the least organizational change and offers the least bang for the buck. A data mesh gives the most consideration to developers and the way they currently work. Knowledge graphs have their heritage in knowledge representation and logic programming, not the most familiar topics to traditional IT staff.
The KM shop in an enterprise would offer as many in-house skills as the IT engineering staff when it comes to talent. Graphs require more of the art of persuasion and the ability to find a receptive audience with the budget to risk, but the benefits of a solid implementation can be substantial. Much depends on cultivating an appreciation of these benefits and a nuanced understanding of them.
{kind=link}