

“The too-much-of-a-good-thing (TMGT) effect occurs when an initially positive relation between an antecedent and a desirable outcome variable turns negative when the underlying ordinarily beneficial antecedent is taken too far, such that the overall relation becomes nonmonotonic.”
The ABC for Studying the Too-Much-of-a-Good-Thing Effect: A Competitive Mediation Framework Linking Antecedents, Benefits, and Costs; Christian Busse, Matthias D. Mahlendorf, Christoph Bode
The benefits of a system tend to improve in a linear fashion with increasing consumption of its features and resources. But there comes an inflection point after which overusing or abusing these benefits without careful consideration and observation of them leads to undesirable effects. This then leads to either wasted time and resources with no additional benefits, or worse, to bad outcomes. It is applicable in all aspects of life and we see it manifested daily in medicine, agriculture, management, and any environment that relies on systems and processes. This is known as the “too much of a good thing” (TMGT) effect, and it can have major consequences for organizations that don’t have systems for managing the data and resources within their environments.
We regularly see the TMGT effect with cloud data platforms. Data teams are extremely happy with the results that come from modern data platforms like Snowflake and Databricks, but they soon realize they’re flying blind and have little or no control and transparency over the spend, usage, and resource efficiency of these platforms. They have access to a lot of usage data, but they can’t make sense of it.
Cloud data platforms can make life so easy for users which explains the explosive adoption of them that we have seen in the last couple of years. However, it is critical to tackling the TMGT effect before it snowballs into a trillion-dollar paradox for your data team.
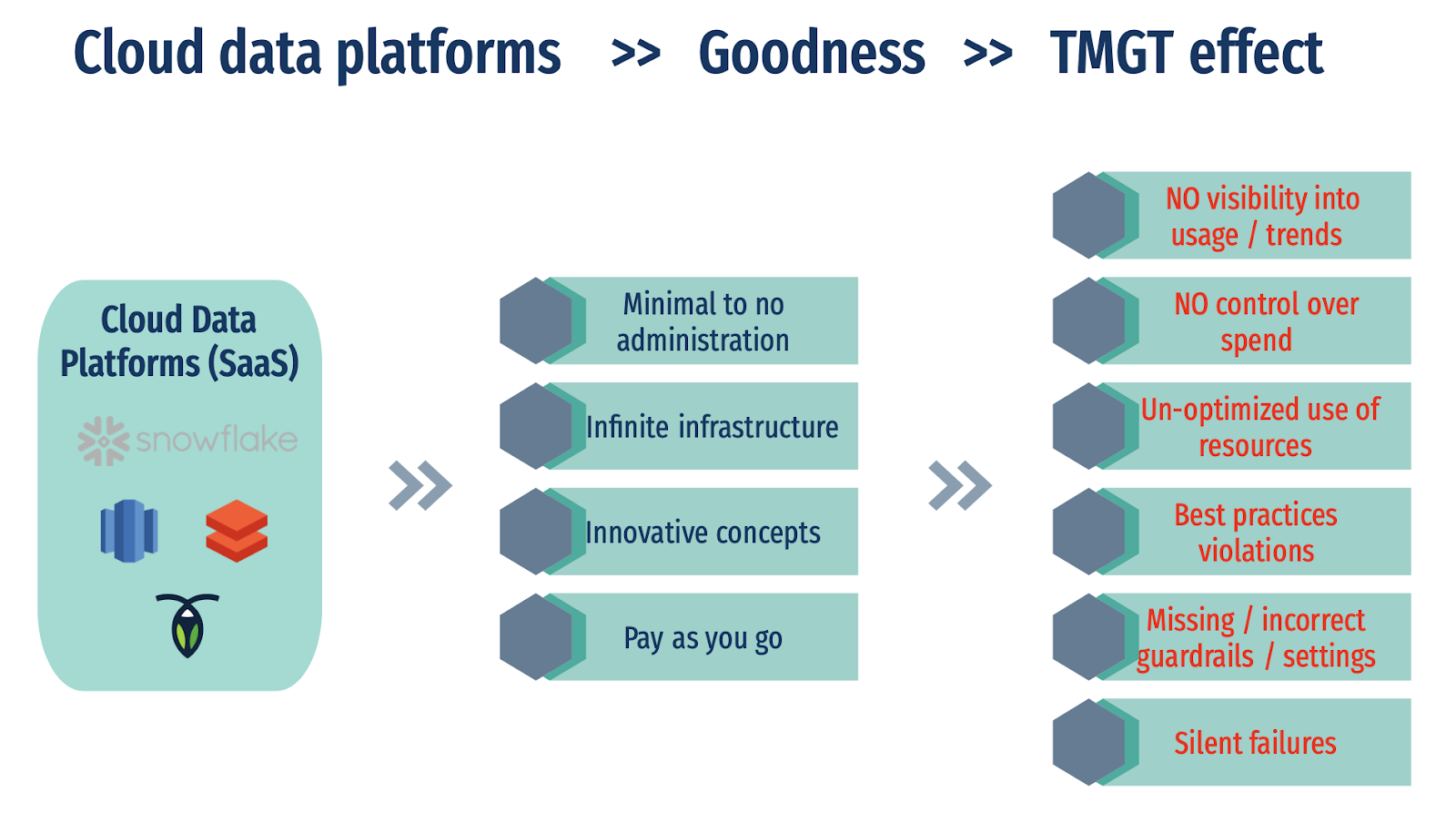
The Goodness Delivered By Cloud Data Platforms
Keeping systems healthy and operable is a major challenge for the teams building big data platforms using the Hadoop ecosystem or similar open-source components that are mostly deployed in on-premises environments. With the explosion in data and services needed to successfully run a data-driven organization, data engineering teams have to shift their focus from operational headaches to business logic and deliver value as fast as possible. They need a solution that addresses these issues; a cloud data platform provides them that solution because it offers the following:
High availability with near-zero administration. One of the most important reasons that big data teams are moving towards these cloud solutions is the service uptime and data durability guarantees they provide. All the major operational issues like installation, upgrade, and maintenance are taken care of. There is no longer a need for a separate team of operators, administrators, reliability engineers, and database administrators (DBAs), and most importantly there are no long system downtimes.
Infinite infrastructure deployed instantly. The cloud delivers a seemingly infinite set of resources and all can be deployed instantly. No more procuring hardware, deploying it in a data center, installing and scaling the clusters – all of that happens as services that do not require active management. This agility is mandatory for the ever-increasing and continuously changing needs of each business organization.
Innovative orientation. Cloud data platforms are not just an extension of on-premises software. They are either built cloud natively or re-written significantly to take advantage of the cloud constructs available and also take into account the future needs of customers. For example, Snowflake’s architecture decouples storage and compute, data sharing, data pruning, auto-clustering, secure views, and has other attributes that have enabled customers to solve complex problems with extreme ease.
Pay as you go. Cloud billing scales with usage and encourages customers to onboard quickly and experiment or deploy at no huge upfront costs. You pay for what you need and only when you use it.
However, all the goodness of cloud data platforms triggers a TMGT effect in an unobserved environment.
As data teams start adopting or migrating to cloud data platforms, it results in a change in infrastructure ownership. The IT department which had been responsible and had strict practices implemented for infrastructure approvals, security, spending and resources deployed in the data center, no longer has control over any of these processes. Instead, the business units/organizations directly sign up for the cloud data platform accounts and follow their own set of practices often led by their engineers, DevOps, or operations team.
In such an uncontrolled and unobserved environment, the same set of features that enabled deploying infinite resources instantly and easy opt-in for powerful innovative features can start having a negative effect i.e. the goodness of cloud data platforms leading to a TMGT effect.
Infinite resources translate into infinite costs. The same feature that provides instant deployment and elasticity, when tuned without proper understanding, can lead to huge bills.
No transparency into spending. Once a team starts consuming the features of a cloud data platform, there are resources deployed in the background for which they get charged. One needs to have complete transparency with what the features are costing them and if the spend is justified.
Un-optimized use of resources. With powerful features and unlimited resources at your disposal, it’s very easy to start consuming a data platform inefficiently or implement bad practices within your team. Teams are under pressure to deliver constantly and without any understanding or observability with tools at their disposal. The easiest way to work around any issues is to allocate more resources or use any feature that satisfies requirements. These bad practices are how inefficiency creeps into the platform and manifests for a long time.
Inability to detect and address anomalous surges immediately. As with any complex software, there are anomalies and spikes in usage. These are often caused by unintentional side effects of actions performed by the data team. The detection of such spikes or anomalies can sometimes take weeks or even months to identify, and it can result in huge, unnecessary expenses.
Best practices violations. Modern cloud data platforms deliver innovative concepts and hence a new set of best practices along with them. Best practices that apply to legacy databases or data warehouses are no longer viable in cloud environments. It is common for novices to try old approaches without understanding the concepts unique to a specific cloud data platform and then implement it. The security for the data platform needs a drastically different and stricter control approach. Data teams cannot assume anymore that anything within a VPN perimeter is safe. The problem for data teams is that all these best practices are buried deep inside documentation, blogs, or community forums and it’s not an efficient way for teams to stay on top of a fast, ever-changing environment and sets of options.
Missing guardrails. Guardrails are so important with any cloud service. The spikes and the resources need to be protected for the reasons of cost and security. The features that guard any customer account are available but they need to be configured properly to make them useful. These actions are mostly taken reactively after the team has been burned.
Silent failures. As more and more workloads are being onboarded and data democratization is encouraged within the organization, there is always the potential for silent failures. Things fail and are only noticed and addressed after users complain. These mistakes are often easy to fix but can cause a huge pain because of the backfilling and the propagation of the data within the dependency mesh.
While the cloud data platform clearly delivers on its promise in the data team’s journey, the TMGT effect poses a huge problem – both economically and operationally. Hence the need of the hour is to tackle this issue by creating a culture of observability within your data ops team.
{kind=link}