
While the natural language processing (NLP) field has been growing at an exponential rate for the last two years — thanks to the development of transfer-based models — their applications have been limited in scope for the job search field. LinkedIn, the leading company in job search and recruitment, is a good example. While I hold a Ph.D. in Material Science and a Master in Physics, I am receiving job recommendations such as Technical Program Manager at MongoDB and a Go Developer position at Toptal which are both web developing companies that are not relevant to my background. This feeling of irrelevancy is shared by many users and is a cause of big frustration.
Job seekers should have access to the best tools to help them find the perfect match to their profile without wasting time in irrelevant recommendations and manual searches…
In general, however, traditional job search engines are based on simple keyword and/or semantic similarities that are usually not well suited to providing good job recommendations since they don’t take into account the interlinks between entities. Furthermore, with the rise of Applicant Tracking Systems (ATS), it is of utmost importance to have field-relevant skills listed on your resume and to uncover which industry skills are becoming more pertinent. For instance, I might have extensive skills in Python programming, but the job description of interest requires knowledge in Django framework, which is essentially based on Python; a simple keyword search will miss that connection.
In order to train the NER and relation extraction model, we obtain the training data using the UBIAI tool and model training on google colab as described in my previous article.
In this tutorial, we will build a job recommendation and skill discovery script that will take unstructured text as input, and will then output job recommendations and skill suggestions based on entities such as skills, years of experience, diploma, and major. Building on my previous article , we will extract entities and relations from job descriptions using the BERT model and we will attempt to build a knowledge graph from skills and years of experience.
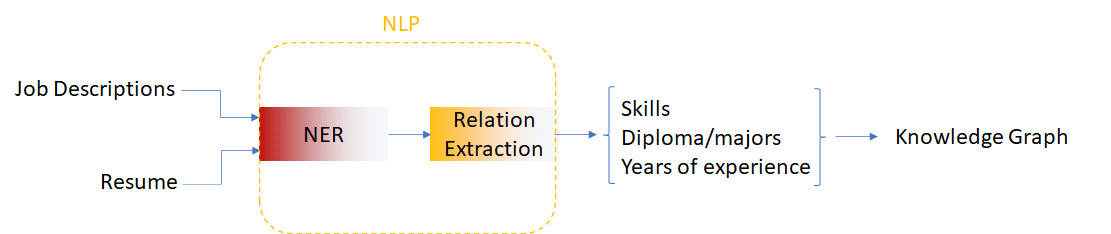
Job analysis pipeline
In order to train the NER and relation extraction model, we performed text annotation using the UBIAI text annotation tool where the annotated data was obtained by labeling entities and relations. Model training was done on google colab as described in my previous article.
Data Extraction:
For this tutorial, I have collected job descriptions related to software engineering, hardware engineering, and research from 5 major companies: Facebook, Google, Microsoft, IBM, and Intel. Data was stored in a csv file.
In order to extract the entities and relations from the job descriptions, I created a Named Entity Recognition (NER) and Relation extraction pipeline using previously trained transformer models (for more information, check out my previous article ). We will store the extracted entities in a JSON file for further analysis using the code below.
def analyze(text): experience_year=[]
experience_skills=[]
diploma=[]
diploma_major=[] for doc in nlp.pipe(text, disable=["tagger"]):
skills = [e.text for e in doc.ents if e.label_ == 'SKILLS']
for name, proc in nlp2.pipeline:
doc = proc(doc)
for value, rel_dict in doc._.rel.items():
for e in doc.ents:
for b in doc.ents:
if e.start == value[0] and b.start == value[1]:
if rel_dict['EXPERIENCE_IN'] >= 0.9:
experience_skills.append(b.text)
experience_year.append(e.text)
if rel_dict['DEGREE_IN'] >= 0.9:
diploma_major.append(b.text)
diploma.append(e.text)
return skills, experience_skills, experience_year, diploma, diploma_majordef analyze_jobs(item):
with open('./path_to_job_descriptions', 'w', encoding='utf-8') as file:
file.write('[')
for i,row in enumerate(item['Description']):
try:
skill, experience_skills, experience_year, diploma, diploma_major=analyze([row])
data=json.dumps({'Job ID':item['JOBID'[i],'Title':item['Title'[i],'Location':item['Location'][i],'Link':item['Link'][i],'Category':item['Category'[i],'document':row, 'skills':skill, 'experience skills':experience_skills, 'experience years': experience_year, 'diploma':diploma, 'diploma_major':diploma_major}, ensure_ascii=False)
file.write(data)
file.write(',')
except:
continue
file.write(']')analyze_jobs(path)
Data Exploration:
After extracting the entities from the job descriptions, we can now start exploring the data. First, I am interested to know the distribution of the required diploma across multiple fields. In the box plot below, we notice few things: the most sought out degree in the software engineering field is a Bachelors, followed by a Masters, and a PhD. For the research field on the other hand, PhD and Masters are more in demand as we would expect. For hardware engineering, the distribution is more homogenous. This might seem very intuitive but it is remarkable that we got this structured data automatically from purely unstructured text with just few lines of code!
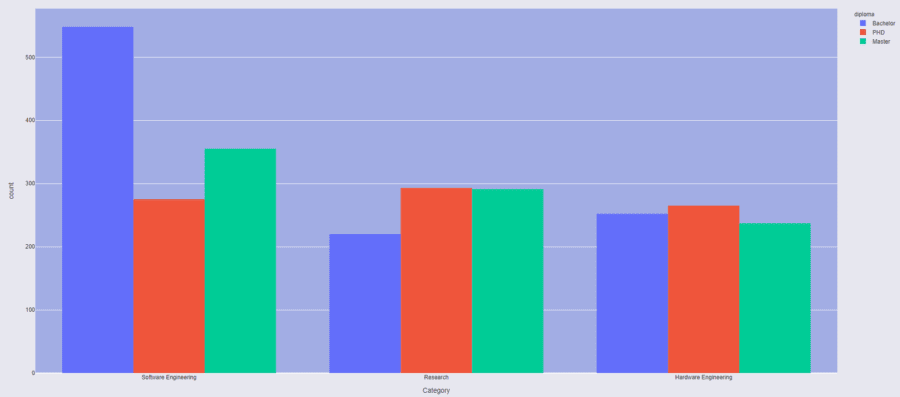
Diploma distribution across multiple fields
I am interested to know which company is looking for PhDs in Physics and Material Science since my background is in these two majors. We see that Google and Intel are leading the search for these types of PhDs. Facebook is looking for more PhDs in computer science and electrical engineering. Note that because of the small sample size of this dataset, this distribution might not be representative of the real distribution. Larger sample sizes will definitely lead to better results, but that’s outside the scope of this tutorial.
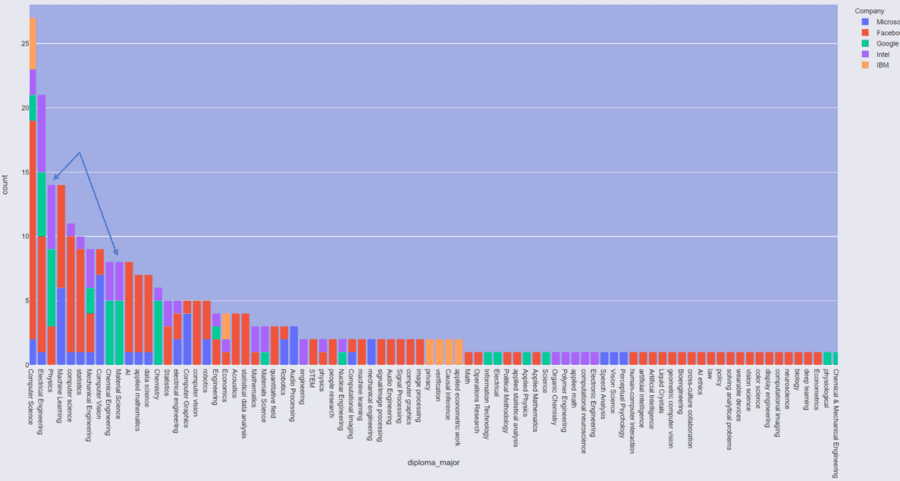
Diploma major distribution
Since this is a tutorial about NLP, lets look at which diploma and majors are required when “NLP” or “natural language processing” is mentioned:.
#Diploma
('Master', 54), ('PHD', 49),('Bachelor', 19)#Diploma major:
('Computer Science', 36),('engineering', 12), ('Machine Learning', 9),('Statistics', 8),('AI', 6)
Companies mentioning NLP, are seeking candidates with a Masters or PhD in computer science, engineering, machine learning or statistics. On the other hand, there is less demand for a Bachelor.
Knowledge Graph
With the skills and years of experience extracted, we can now build a knowledge graph where the source nodes are job description IDs, target nodes are the skills, and the strength of the connection is the year of experience. We use the python library pyvis and networkx to build our graph; we link job descriptions to their extracted skills using the years of experience as weights.
job_net = Network(height='1000px', width='100%', bgcolor='#222222', font_color='white')
job_net.barnes_hut()
sources = data_graph['Job ID']
targets = data_graph['skills']
values=data_graph['years skills']
sources_resume = data_graph_resume['document']
targets_resume = data_graph_resume['skills']
edge_data = zip(sources, targets, values )
resume_edge=zip(sources_resume, targets_resume)
for j,e in enumerate(edge_data):
src = e[0]
dst = e[1]
w = e[2]
job_net.add_node(src, src, color='#dd4b39', title=src)
job_net.add_node(dst, dst, title=dst)
if str(w).isdigit():
if w is None:
job_net.add_edge(src, dst, value=w, color='#00ff1e', label=w)
if 1<w<=5:
job_net.add_edge(src, dst, value=w, color='#FFFF00', label=w)
if w>5:
job_net.add_edge(src, dst, value=w, color='#dd4b39', label=w)
else:
job_net.add_edge(src, dst, value=0.1, dashes=True)for j,e in enumerate(resume_edge):
src = 'resume'
dst = e[1]
job_net.add_node(src, src, color='#dd4b39', title=src)
job_net.add_node(dst, dst, title=dst)
job_net.add_edge(src, dst, color='#00ff1e')neighbor_map = job_net.get_adj_list()for node in job_net.nodes:
node['title'] += ' Neighbors:<br>' + '<br>'.join(neighbor_map[node['id']])
node['value'] = len(neighbor_map[node['id']])# add neighbor data to node hover data
job_net.show_buttons(filter_=['physics'])
job_net.show('job_knolwedge_graph.html')
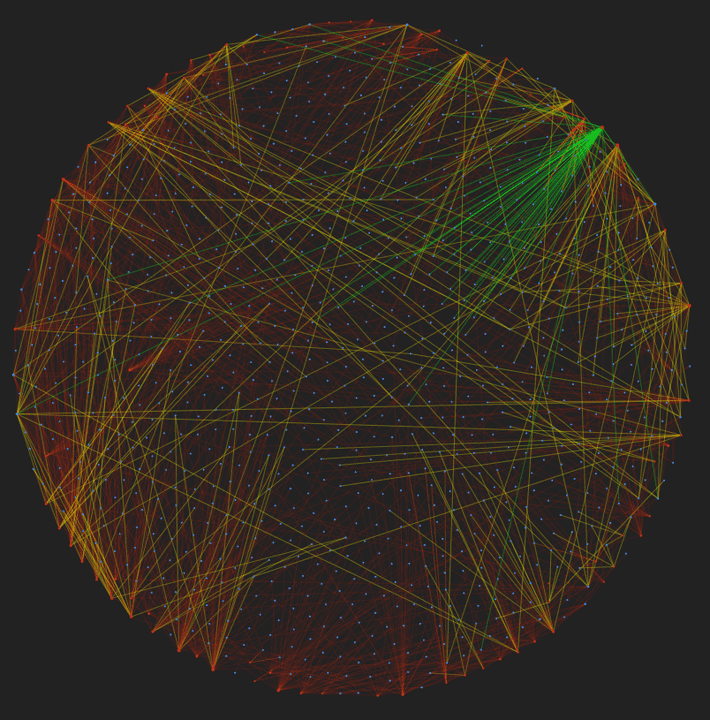
Let’s visualize our knowledge graph! For the sake of clarity, I have only displayed a few jobs in the knowledge graph. For this test, I am using a sample resume in the machine learning field.
The red nodes are the sources which can be job descriptions or a resume. The blue nodes are the skills. The color and label of the connection represent the years of experience required (yellow = 1–5 years; red = > 5 years; dashed = no experience). In the example below, Python is linking the resume to 4 jobs, all of which require 2 years of experience. For the machine learning connection, no experience is required. We can now begin to glean valuable insights from our unstructured texts!
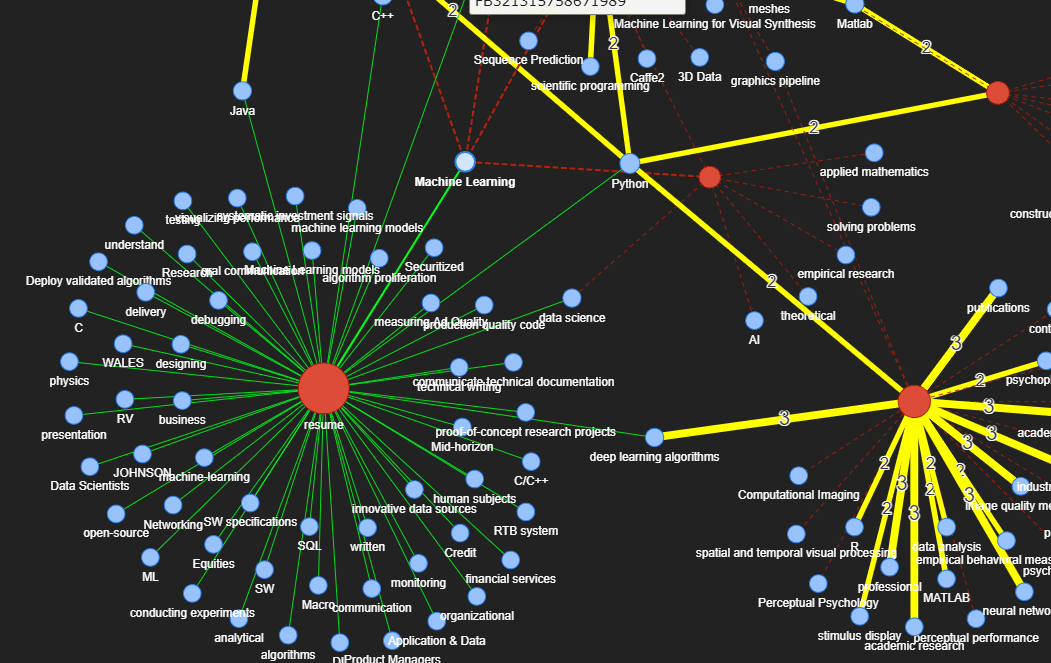
Knowledge graph
Let’s find out which jobs have the highest connections to the resume:
# JOB ID #Connections
GO4919194241794048 7
GO5957370192396288 7
GO5859529717907456 7
GO5266284713148416 7
FB189313482022978 7
FB386661248778231 7
Now let’s look at the knowledge graph network containing few of the highest matches:
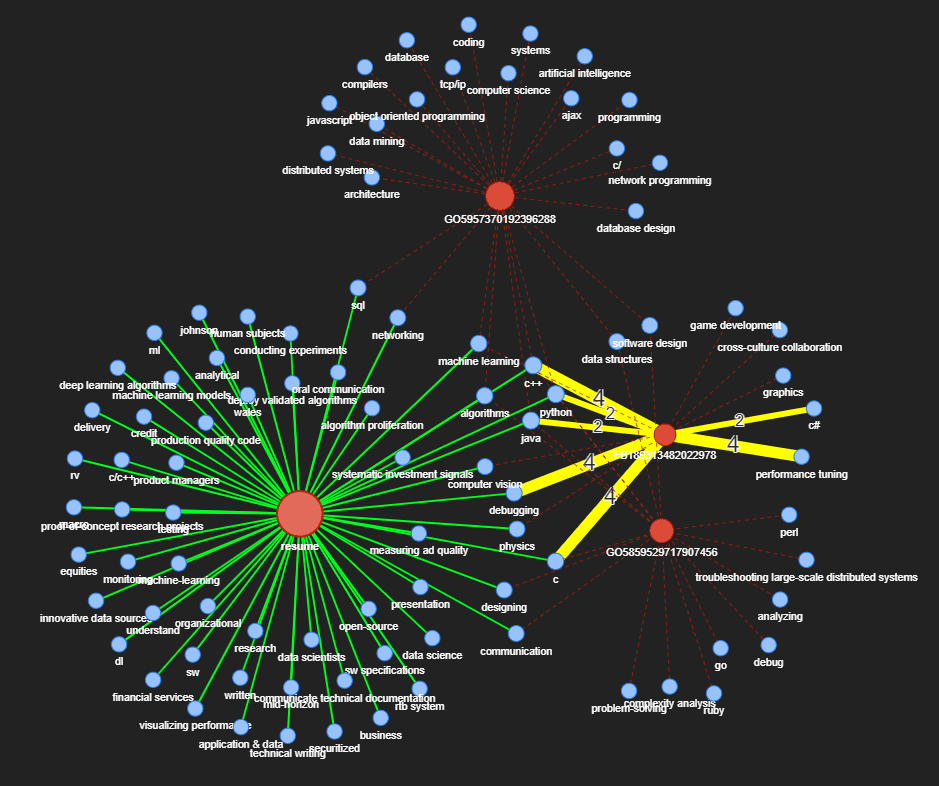
Knowledge graph of the highest job matches
Notice the importance of co-reference resolution in this case (which has not been done in this tutorial). The skills machine-learning, machine learning models and machine learning were counted as different skills but they are obviously the same skill and should be counted as one. This can make our matching algorithm inaccurate and highlights the importance of co-reference resolution when doing NER extraction.
That being said, with the knowledge graph we can directly see that both GO5957370192396288 and GO5859529717907456 are a good match since they don’t require extensive experience whereas FB189313482022978 requires 2–4 years of experience in various skills. Et voila!
Skills Augmentation
Now that we have identified the connections between the resume and job descriptions, the goal is to discover relevant skills that might not be in the resume but are important to the field we are analyzing. For this purpose, we filter the job descriptions by field — namely software engineering, hardware engineering, and research. Next, we query all neighboring jobs connected to resume skills and for each job found, extract the associated skills. For clear visual rendering, I have plotted word frequency as a word cloud. Let’s look at the field of software engineering:
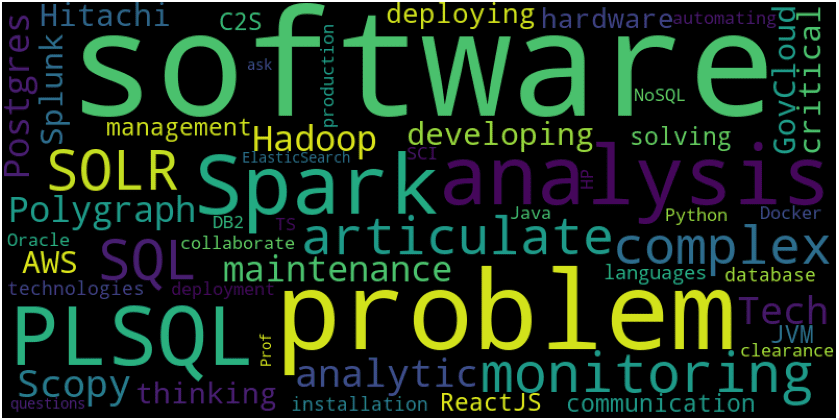
Word cloud of skills in software engineering
Notice that Spark, SOLR, and PLSQL are mentioned frequently in jobs having connection to the resume and might be important to the field.
On the other hand, for hardware engineering:

Word cloud of skills in hardware engineering
Design, RF, and RFIC are definite needs here.
And for the research field:

Word cloud of skills in research
Popular skills include machine learning, signal processing, tensorflow, PyTorch, model analyzing , etc…
With just a few lines of code, we have transformed unstructured data into structured information and extracted valuable insights!
Conclusion:
With the recent breakthroughs in the NLP field — whether it be named entity recognition, relation classification, question answering, or text classification — it is becoming a necessity for companies to apply NLP in their businesses to remain competitive.
In this tutorial, we have built a job recommendation and skill discovery app using NER and relation extraction model (using BERT transformer). We achieved this by building a knowledge graph linking jobs and skills together.
Knowledge graphs combined with NLP provide a powerful tool for data mining and discovery. Please feel free to share your use case demonstrating how NLP can be applied to different fields. If you have any questions or want to create custom models for your specific case, leave a note below or send us an email at [email protected]
{kind=link}