
Scaling AI with Dynamic Inference Paths in Neural Networks
Introduction
IBM Research, with the help of the University of Texas Austin and the University of Maryland, has tried to expedite the performance of neural networks by creating technology, called BlockDrop. Behind the design of this technology lies the objective and promise of speeding up convolutional neural network operations without any loss of fidelity, which can offer a great savings of cost to the ML community.
This could “further enhance and expedite the application and use as well as boost the performance of neural nets, leading to particularly in places and on cloud/edge servers with limited computing capability and power limitations”.
An increase in accuracy level have been accompanied by increasingly complex and deep network architectures. This presents a problem for domains where fast inference is essential, particularly in delay-sensitive and realtime scenarios such as autonomous driving, robotic navigation, or user-interactive applications on mobile devices.
Further research results show regularization techniques for fully connected layers, is less effective for convolutional layers, as activation units in these layers are spatially correlated and information can still flow through convolutional networks despite dropout.
BlockDrop method introduced by IBM Research is a “complementary method to existing model compression techniques, as this form of structured NEURAL NETWORK based dropout, drops spatially correlated information, resulting in compressed representations. The residual blocks of a neural network can be kept for evaluation, and can be further pruned for greater speed”.
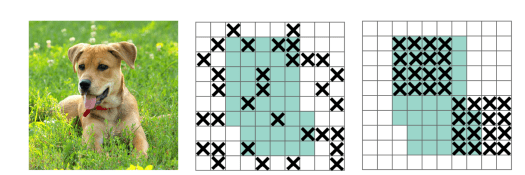
The below figure illustrates blockdrop mechanism for a given image input to the convolution network. The green regions in the 2 right side figures include the activation units which contain semantic information in the input image. The activations dropped at random is not effective in removing semantic information.
For a NN with iteration at each step, there are nearby activations contain closely related information. The best strategy employed in spatial compression algorithms is to drop continuous regions that represent similar region and context either by color or shape. By this it helps to remove certain semantic information (e.g., head or feet), propelling remaining units to learn detailed features for classifying input image.
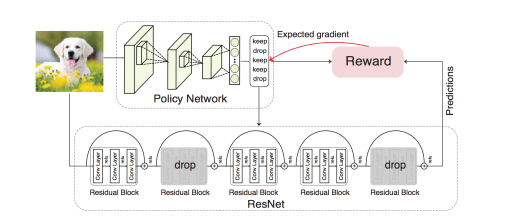
Policy Network for Dynamic Inference Paths
BlockDrop mechanism learns to dynamically choose which layers of a deep network to execute during inference so as to best reduce total computation without degrading prediction accuracy. It exploits the robustness of Residual Networks (ResNets) by dropping layers that aren’t necessary to compute to achieve the desired level of accuracy, resulting in the dynamic selection of residual blocks for a given novel image. Thus it aids in:
- Allocating system resources in a more efficient manner with the objective of saving cost.
- Facilitating further insights into ResNets, e.g., whether and how different blocks encode information about objects and understanding the dynamics behind encoding object-level features.
- Achieving minimal block usage through more compressed representations by emphasizing decisions at an image pixel level. These image-specific decisions (with features) undertaken at different layers of hidden neurons, helps to optimally drop blocks.
For example, given a pre-trained ResNet, a policy network is trained into an “associative reinforcement learning setting for the dual reward of utilizing a minimal number of blocks while preserving recognition accuracy”.
Experiments on CIFAR and ImageNet reveal learned policies not only accelerate inference but also encode meaningful visual information. A ResNet-101 model, with this method, achieves a speedup of 20% on average, going as high as 36% for some images, while maintaining the same 76.4% top-1 accuracy on ImageNet.
BlockDrop strategy learns a model, referred to as the policy network, that, given a novel input image, outputs the posterior probabilities of all the binary decisions for dropping or keeping each block in a pre-trained ResNet.
The policy network is trained using curriculum learning to maximize a reward that incentivizes the use of as few blocks as possible while preserving the prediction accuracy.
In addition, the pre-trained ResNet is further jointly fine-tuned with the policy network to produce feature transformations targeted for block dropping behavior. The method represents an instantiation of associative reinforcement learning where all the decisions are taken in a single step given the context (i.e., the input instance). This results in lightweight policy execution and scalable to very deep networks.
Deep Learning Neural networks like a recurrent model (LSTM) could also serve as the policy network, however, research findings reveal a CNN to be more efficient with similar performance.
The below Figure represents a conceptual overview of BlockDrop, that learns a policy to select the minimal configuration of blocks needed to correctly classify a given input image. The resulting instance-specific paths in the network not only reflect the image’s difficulty, where easier samples have been known to use fewer blocks. It has also been possible to encode meaningful visual information with patterns of blocks, that correspond to clusters of visual features.
Source -IBM
The above figure depicts policy network architecture of Blockdrop. On any given new image, the policy network outputs dropping and keeping decisions for each block in a pre-trained ResNet. This final active blocks retained are used for evaluating prediction.
Each and every both block usage and prediction accuracy, have been known to cumulatively account for Policy rewards. The policy network is further trained to optimize the expected reward with a curriculum learning strategy, which helps to provide a generic algorithm for global optimization of non-convex functions.
In order to attain this objective the policy network is jointly fine-tuned with the ResNet.

Source -IBM
The above figure illustrates samples from ImageNet. The top row contains images that are classified with high accuracy with the least number of blocks by removing redundancy, while samples in the bottom row utilize the most blocks and take in more space.
Samples using fewer blocks are indeed easier to identify since they contain single frontal view objects positioned in the center, while several objects, occlusion, or cluttered background occur in samples that require more blocks.
This is based on the hypothesis “that block usage is a function of instance difficulty where BlockDrop automatically learns “sorting” images into easy or hard cases”.
Usage (Reference https://github.com/Tushar-N/blockdrop.git)
Library and Usage
git clone https://github.com/Tushar-N/blockdrop.git
pip install -r requirements.txt wget -O blockdrop-checkpoints.tar.gz
https://www.cs.utexas.edu/~tushar/blockdrop/blockdrop-checkpoints.t...
tar -zxvf blockdrop-checkpoints.tar.gz
#Train a model on CIFAR 10 built upon a ResNet-110 python cl_training.py --model R110_C10 --cv_dir cv/R110_C10_cl/ --lr 1e-3 --batch_size 2048 --max_epochs 5000 #Train a model on ImageNet built upon a ResNet-101 python cl_training.py --model R101_ImgNet --cv_dir cv/R101_ImgNet_cl/ --lr 1e-3 --batch_size 2048 --max_epochs 45 --data_dir data/imagenet/ # Finetune a ResNet-110 on CIFAR 10 using the checkpoint from cl_training python finetune.py --model R110_C10 --lr 1e-4 --penalty -10 --pretrained cv/cl_training/R110_C10/ckpt_E_5300_A_0.754_R_2.22E-01_S_20.10_#_7787.t7 --batch_size 256 --max_epochs 2000 --cv_dir cv/R110_C10_ft_-10/ # Finetune a ResNet-101 on ImageNet using the checkpoint from cl_training python finetune.py --model R101_ImgNet --lr 1e-4 --penalty -5 --pretrained cv/cl_training/R101_ImgNet/ckpt_E_4_A_0.746_R_-3.70E-01_S_29.79_#_484.t7 --data_dir data/imagenet/ --batch_size 320 --max_epochs 10 --cv_dir cv/R101_ImgNet_ft_-5/ python test.py --model R110_C10 --load cv/finetuned/R110_C10_gamma_10/ckpt_E_2000_A_0.936_R_1.95E-01_S_16.93_#_469.t7 python test.py --model R101_ImgNet --load cv/finetuned/R101_ImgNet_gamma_5/ckpt_E_10_A_0.764_R_-8.46E-01_S_24.77_#_10.t7 R110_C10 Model Output Accuracy: 0.936 Block Usage: 16.933 ± 3.717 FLOPs/img: 1.81E+08 ± 3.43E+07 Unique Policies: 469 Imagenet Model Output Accuracy: 0.764 Block Usage: 24.770 ± 0.980F LOPs/img: 1.25E+10 ± 4.28E+08Unique Policies: 10Conclusion
In this blog, we have discussed the BlockDrop strategy aimed to speed up the training of neural networks. It has the following characteristics:
- Speed AI-based computer vision operations and save the running time of servers.
- Approximately takes 200 times less power per pixel than comparable systems using traditional hardware.
- Facilitates the deployment of top-performing deep neural network models on mobile devices by effectively reducing the storage and computational costs of such networks.
- Determines the minimal configuration of layers, or blocks, needed to correctly classify a given input image. The simplicity of images helps to remove more layers and save more time.
- Application has been extended to ResNets for faster inference by selectively choosing residual blocks to evaluate in a learned and optimized manner conditioned on inputs.
- Extensive experiments conducted on CIFAR and ImageNet show considerable gains over existing methods in terms of the efficiency and accuracy trade-off.
References
- BlockDrop: Dynamic Inference Paths in Residual Networks https://arxiv.org/pdf/1711.08393.pdf
- https://www.ibm.com/blogs/research/2018/12/ai-year-review/
{kind=link}