
I started my career as an Oracle database developer and administrator back in 1998. Over the past 20+ years, it has been amazing to see how IT has been evolving to handle the ever growing amount of data, via technologies including relational OLTP (Online Transactional Processing) database, data warehouse, ETL (Extraction, Transformation and Loading) and OLAP (Online Analytical Processing) reporting, big data and now AI, Cloud and IoT. All these technologies were enabled by the rapid growth in computational power, particular in terms of processors, memory, storage, and networking speed. The objective of this article is to summarize, first, the underlying principles on how to handle large amounts of data and, second, a thought process that I hope can help you get a deeper understanding of any emerging technologies in the data space and come up with the right architecture when riding on current and future technology waves.
.
In a data pipeline, data normally go through 2 stages: Data Processing and Data Access. For any type of data, when it enters an organization (in most cases there are multiple data sources), it is most likely either not clean or not in the format that can be reported or analyzed directly by the eventual business users inside or outside of the organization. Data Processing is therefore needed first, which usually includes data cleansing, standardization, transformation and aggregation. The finalized data is then presented in the Data Access layer – ready to be reported and used for analytics in all aspects. Data Processing is sometimes also called Data Preparation, Data Integration or ETL; among these, ETL is probably the most popular name.
.
Data processing and data access have different goals, and therefore have been achieved by different technologies. Data Processing for big data emphasizes “scaling” from the beginning, meaning that whenever data volume increases, the processing time should still be within the expectation given the available hardware. The overall data processing time can range from minutes to hours to days, depending on the amount of data and the complexity of the logic in the processing. On the other hand, data access emphasizes “fast” response time on the order of seconds. On a high level, the scalability of data processing has been achieved mostly by parallel processing, while fast data access is achieved by optimization of data structure based on access patterns as well as increased amounts of memory available on the servers.
.
Data Processing
.
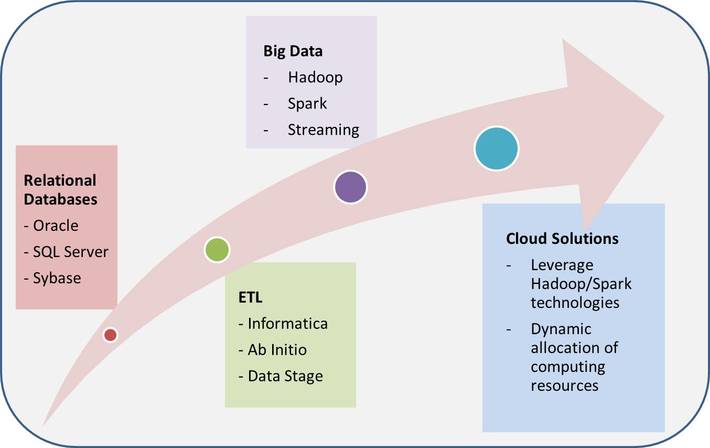
In order to clean, standardize and transform the data from different sources, data processing needs to touch every record in the coming data. Once a record is clean and finalized, the job is done. This is fundamentally different from data access – the latter leads to repetitive retrieval and access of the same information with different users and/or applications. When data volume is small, the speed of data processing is less of a challenge than compared to data access, and therefore usually happens inside the same database where the finalized data reside. As the data volume grows, it was found that data processing has to be handled outside of databases in order to bypass all the overhead and limitations caused by the database system which clearly was not designed for big data processing in the first place. This was when ETL and then Hadoop started to play a critical role in the data warehousing and big data eras respectively.
.
The challenge of big data processing is that the amount of data to be processed is always at the level of what hard disk can hold but much more than the amount of computing memory that is available at a given time. The fundamental way of efficient data processing is to break data into smaller pieces and process them in parallel. In another word, scalability is achieved by first enabling parallel processing in the programming such that when data volume increases, the number of parallel processes will increase, while each process continues to process similar amount of data as before; second by adding more servers with more processors, memory and disks as the number of parallel processes increases.
Parallel processing of big data was first realized by data partitioning technique in database systems and ETL tools.
.
Once a dataset is partitioned logically, each partition can be processed in parallel. Hadoop HDFS (Highly Distributed File Systems) adapts the same principle in the most scalable way. What HDFS does is partition the data into data blocks with each block of a constant size. The blocks are then distributed to different server nodes and recorded by the meta-data store in the so called Names node. When a data process kicks off, the number of processes is determined by the number of data blocks and available resources (e.g., processors and memory) on each server node. This means HDFS enables massive parallel processing as long as you have enough processors and memory from multiple servers.
.
Currently Spark has become one of the most popular fast engine for large-scale data processing in memory. Does it make sense? While memory has indeed become cheaper, it is still more expensive than hard drives. In the big data space, the amount of big data to be processed is always much bigger than the amount of memory available. So how does Spark solve it? First of all, Spark leverages the total amount of memory in a distributed environment with multiple data nodes. The amount of memory is, however, still not enough and can be costly if any organization tries to fit big data into a Spark cluster. Let’s consider what type of processing Spark is good for. Data processing always starts with reading data from disk to memory, and at the end writing the results to disks. If each record only needs to be processed once before writing to disk, which is the case for a typical batch processing, Spark won’t yield advantage compared to Hadoop. On the other hand, Spark can hold the data in memory for multiple steps for data transformation while Hadoop cannot. This means Spark offers advantages when processing iteratively on the same piece of data multiple times, which is exactly what’s needed in analytics and machine learning. Now consider the following: since there could be tens or hundreds of such analytics processes running at the same time, how to make your processing scale in a cost effective way? Clearly, simply relying on processing in memory cannot be the full answer, and distributed storage of big data, such as Hadoop, is still an indispensable part of the big data solution complementary to Spark computing.
.
Another hot topic in data processing area is Stream processing. It offers great advantage in reducing processing speed because at a given point of time it only needs to process small amount of data whenever the data arrives. However, it is not as versatile as batch processing in 2 aspects: the first is that the input data needs to come in a “stream” mode, and the second is that certain processing logic that requires aggregation across time periods still need to be processed in batch afterwards.
.
Lastly Cloud solutions provide the opportunity to scale the distributed processing system in a more dynamic fashion based on data volume, hence, the number of parallel processes. This is hard to achieve on premise within an enterprise because new servers need to be planned, budgeted and purchased. If the capacity is not planned well, the big data processing could be either limited by the amount of hardware, or extra purchase leads to wasted resources without being used. Processing on Cloud gains the big advantage of infrastructure elasticity which can give more guarantee to achieve the best scale in a more cost effective fashion.
Data Access
As compared to data processing, data access has very different characteristics, including:
-
The data structure highly depends on how applications or users need to retrieve the data
-
Data retrieval pattens need to be well understood because some data can be repetitively retrieved by large number of users or applications.
-
The amount of data retrieved each time should be targeted, and therefore should only contain a fraction of the available data.
Given the above principles, there have been several milestones in the past 2 decades that reflect how to access the ever increasing amount of data while still returning the requested data within seconds:
-
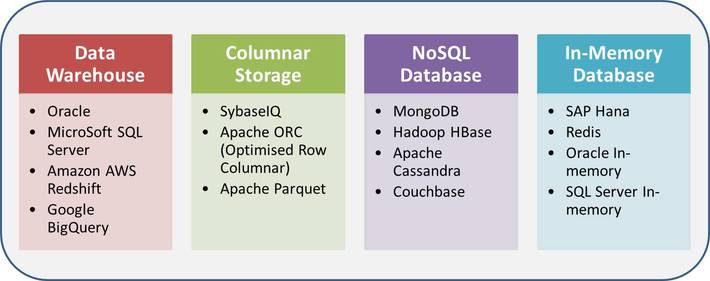
Data warehousing: avoids the table joins which can be very expensive when data volume is big. The concept of “fact table” appears here, in which all the columns are put together without the database normalization principles as in a relational database.
-
Columnar databases: each column is stored and indexed, and therefore, accessed separately. This gives faster response time than row-based access of conventional relational databases when a row has many columns whereas queries only retrieve few columns at a time.
-
NoSQL database: eliminates joins and relational structure all together and is tailored to fast data retrieval in a more specific way.
-
In-memory database: offers fast performance by holding the whole database or the whole table in memory.
Below table gives some popular examples of each database type, but not intent to give a full list. Note that a database may combine more than 1 technologies. For example, Redis is a NoSQL database as well as in memory. In addition, data retrieval from Data Warehouse and Columnar Storages leverages parallel processes to retrieve data whenever applicable. Because there could be many choices of different types of databases depending on data content, data structure and retrieval patterns by users and/or applications, Data Access is an area an organization needs to evolve quickly and constantly. It should be also common to have different types of databases or tools at the same time for different purposes.
Summary
As we can see, a big distinction between data processing and data access is that data access ultimately comes from customers’ and business’s needs, and choosing the right technology drives future new product developments and enhances users experience. On the other hand, data processing is the core asset of a company, and processing in scale and producing good quality of data is the essential enabler for a company to grow with its data. Many companies experience the stalking of their data processing system when data volume grows, and it is costly to rebuild a data processing platform from scratch. The principle of parallel data processing and scalability need to be carefully thought through and designed from the beginning. Data Processing also goes hand in hand with data management and data integration – all 3 are essential for the success of any data intensive organization. Furthermore, every organization’s IT is now facing many choices of big data solutions from both open source communities and third-party vendors. A clear understanding of the differences between data processing and data access can enable IT and business leaders to not only build a solid data architecture, but also make the right decisions to expand and modernize it at a steady pace.
{kind=link}