
In fact, the business plans of the next 10,000 startups are easy to forecast: Take X and add AI. Find something that can be made better by adding online smartness to it
– Kevin Kelly, The Inevitable: Understanding the 12 Technological Forces That Will Shape Our Future

Over the past few years, artificial intelligence continues to be one of the hottest topics. The best minds participate in AI research, the largest corporations allocate astronomical sums for the development of competencies in this area, and AI startups collect multibillion-dollar investments annually.
If you are engaged in business processes improvement or are looking for new ideas for your business, then you will most likely come across AI. And in order to work effectively with it, you need to understand its constituent parts.
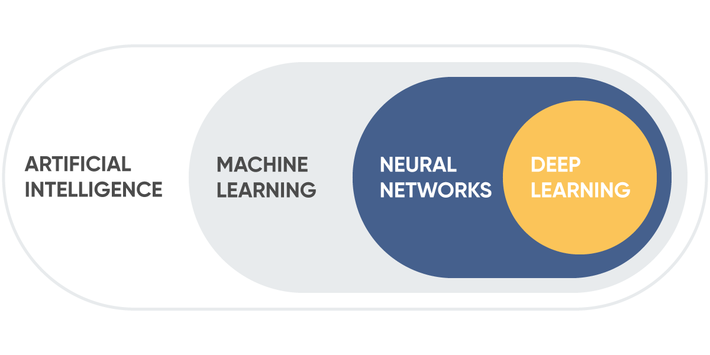
Artificial intelligence
Let’s find out what artificial intelligence is all about. A brief description is given by François Chollet in his book Deep Learning with Python: “the effort to automate intellectual tasks normally performed by humans. As such, AI is a general field that encompasses machine learning and deep learning, but also includes many more approaches that don’t involve any learning ”.
For example, the precursor to today’s chatbots, ELIZA, which was created in the MIT Artificial Intelligence Laboratory. This program could maintain a long dialogue with a person, but could not learn new words or correct its behavior during a dialogue. The behavior of ELIZA was to be specified explicitly using a special programming language.
The history of artificial intelligence in its modern sense begins in the 1950s, with the works of Alan Turing and the Dartmouth workshop, which brought together the first enthusiasts of this field and in which the basic principles of the science of AI were formulated. Further, this industry experienced several cycles of a surge of interest and subsequent recessions (the so-called “AI winters”), in order to become one of the key areas of world science today.
It is worth mentioning the hypothesis of strong and weak artificial intelligence. A strong AI can think and be aware of itself as a separate person. Weak AI is deprived of such abilities and simply performs a certain range of tasks (plays chess, recognizes cats in images or draws a picture for $432,500). All existing AIs are weak, do not worry.
Nowadays, it’s hard to imagine any type of activity without AI in use. Whether you drive a car, take selfies, pick up sneakers for yourself in an online store or plan a vacation, almost everywhere you are assisted by a small, weak, but already very useful artificial intelligence.
Machine learning
One of the key features of intelligence (artificial and not really artificial) is the ability to learn. For AI, a family of machine learning models is responsible for this ability. Their essence is simple: unlike classical algorithms, which are a clear set of instructions that convert incoming data into a result, machine learning based on examples of data and corresponding results finds patterns in data and produces an algorithm that turns arbitrary data into the desired result.
There are three main categories of machine learning:
-
Supervised learning – the system is trained on the basis of data examples with previously known results for each example. There are two most popular tasks for machine learning: the regression and the classification task. Regression is a prediction of a continuous outcome, such as the price of a house or the level of manufacturing emissions. Classification – a category (class) prediction, for example, whether an email is a spam or not, whether the book is a detective novel or an encyclopedia.
-
Unsupervised learning – the system finds internal relationships and patterns in the data. In this case, the results for each example are unknown.
-
Reinforcement learning is an approach in which the system is rewarded for correct actions and penalized for wrong ones. As a result, the system learns to develop an algorithm in which it receives the highest reward and the lowest penalty.
An ideal machine learning model can analyze any data, find all the patterns, and create an algorithm to achieve any desired result. But this ideal model has not yet been created. You can read about the path to its creation in Pedro Domingos’s “The Master Algorithm”.
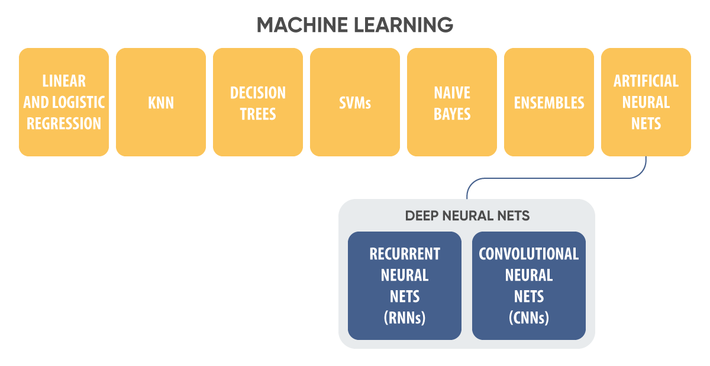
Today’s machine learning models specialize in certain tasks, they all have their strengths and weaknesses. Among these models are the following:
-
Linear regression is a classic model derived from statistics. As the name implies, it is designed for regression tasks, that is, predictions of continuous values. For example, how much lemonade will be sold depending on the weather.
-
Logistic regression is used for classification tasks. It predicts the probability that the given sample belongs to a particular class.
-
Decision tree is a method often used for classification tasks. In this method, the class of a given object is defined as a series of questions, each of which usually involves the answer Yes or No.
-
K-Nearest Neighbors is a simple and fast method mostly used for classification. In this method, the data point class is determined by k (k could be any number) most similar to data point examples.
-
Naive Bayes is a popular classification method that takes advantage of probability theory and Bayes’ theorem to determine the likelihood of a certain event (the email is spam) under the given conditions (the phrase “free loan” is found 20 times in the email).
-
SVM is a supervised machine learning algorithm, that is often used for classification tasks. It is able to effectively separate objects of different classes, even if each object has many interrelated features.
-
Ensembles combine many machine learning models and determine the class of an object based on voting or averaging the responses of each of the models.
-
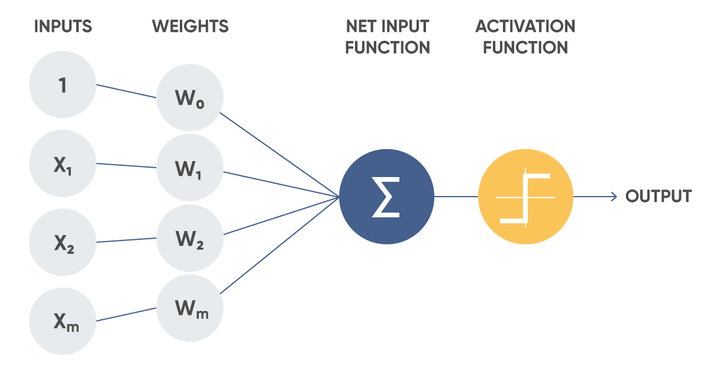
Neural networks are based on the principles of the human brain. A neural network consists of many neurons and connections between them. A neuron can be represented as a function with several inputs and one output. Each neuron takes parameters from inputs (each input may have a different weight, which determines its importance), performs a specific function on them and gives the result to the output. The output of one neuron can be the input for another. Thus, multi-layer neural networks are formed, which are the subject of deep learning. We will talk about this in more detail.
Neuron structure diagram:
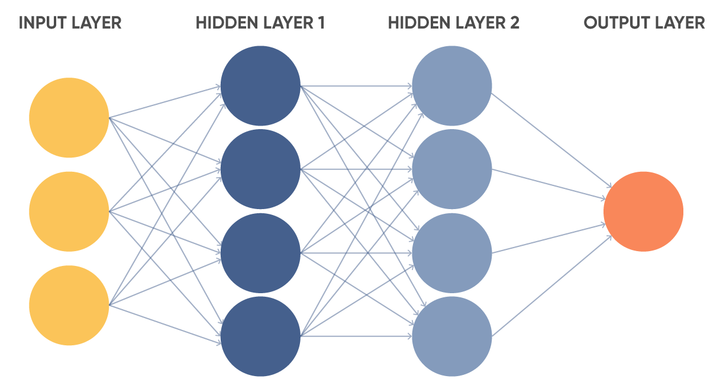
Artificial neural network with two hidden layers:
Studying given examples, the neural network adjusts the weights between the neurons so as to give the greatest weight to the neurons that make the most impact on getting the desired result. For example, if an animal is striped, fluffy and meowing, then it is probably a cat. At the same time, we assign the maximum weight to the meow parameter. So if the animal is not striped and not fluffy, but meows – it is still likely a cat.
Deep learning
Deep learning deals with deep neural networks. Opinions regarding the deepness may vary. Some experts believe that the network can be considered deep if it has more than one hidden layer, while others recognize the network as deep only if it has many hidden layers.
There are several types of neural networks that are now actively used. The most popular among them are the following:
-
Long short-term memory (LSTM) – used for text classification and generation, speech recognition, musical compositions generation, and time series prediction.
-
Convolutional neural networks (CNN) – used for image recognition, video analysis, and Natural language processing tasks.
Conclusion
So what is the difference between AI, machine learning and deep learning? We hope, having read this article, you already know the answer to this question. Artificial intelligence is a general area of automation of intellectual tasks (such as reading, playing Go, image recognition, and creating self-driving cars). Machine learning is a set of artificial intelligence methods that are responsible for the ability of an AI to learn. Deep learning is a subclass of machine learning methods that study multi-layer neural networks.
{kind=link}