

I got this question in a recent webinar:
Is the marginal cost of reusing the data really zero, especially given how organizations are making duplicate copies of the same data that is redundantly stored in operational data stores, data lakes, data warehouses, data marts, analytic marts, and even spreadmarts?
Good question and the first question back is why are companies making duplicate copies of the same data and moving that data to new data repositories? If the data is duplicated and enhancements to the data are not shared across the organization, then you can’t reap the benefits of the Data Economic Multiplier Effect (Figure 1).

Figure 1: The Data Economic Multiplier Effect
The Data Economic Multiplier Effect is the accumulation of attributable and quantifiable financial and economic value from the reuse of the same data set against multiple use cases
As I wrote in my book “The Economics of Data, Analytics, and Digital Transformation”, data silos are the destroyer of the economic value of data because if I can’t share, reuse, and continuously refine the data, then the Data Economic Multiplier Effect doesn’t kick in. Duplicating data so that it cannot be shared and continuously refined negates the Marginal Propensity of Reuse (MPR), which states (Figure 2):
Marginal Propensity to Reuse (MPR) states that an increase in the reuse of a data set across multiple use cases drives an increase in the attributable value of that data set at marginal cost.

Figure 2: The Marginal Propensity to Reuse (MPR)
Duplicating and isolating data (data silos) is the great destroyer of the unique characteristics of data as an economic asset – an asset that not only never depletes, never wears out, and can be reused across an unlimited number of use cases, but also has the characteristic that any improvements in the data (quality, completeness, latency, granularity, enrichment) benefits every use case that uses that data set… at zero marginal cost.
Rube Goldberg Must Have Been a Data Architect
Rube Goldberg was an American cartoonist who satirized the American preoccupation with technology. His name is synonymous with any simple process made outlandishly complicated (Figure 3).

Figure 3: Professor Butts and the Self-Operating Napkin (1931)
It seems Rube Goldberg must have become a systems architect given the convoluted data architectures that I’ve seen over the years. While Figure 4 is not any specific organization’s actual data architecture, but there are ones out there even worse than this!
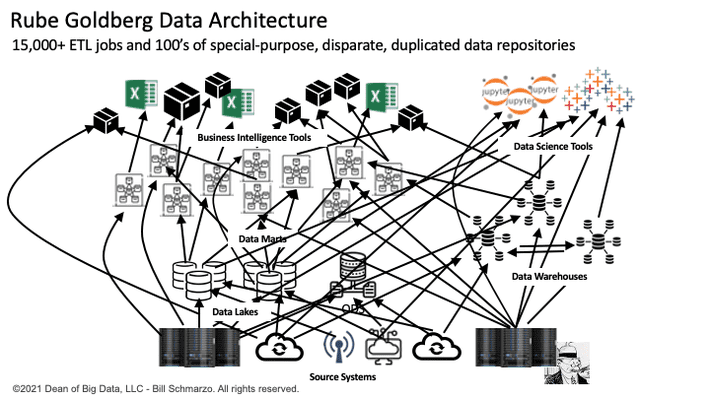
Figure 4: Somewhat Typical Spaghetti Data Architecture
One CIO with whom I had a conversation has a team of 500 data engineers managing over 15,000 ETL jobs that are responsible for acquiring, moving, aggregating, standardizing, and aligning data across the organization’s operational and customer-facing systems under ridiculously tight Service Level Agreements (SLAs) to support their growing number of diversity of data consumers.
It seems that any technology that can facilitate the seamless sharing of data across the organization – that can mitigate the duplication, proliferation, and mutation of the data across intermediary data marts, data warehouses, and data lakes – would be an instant winner. And is that instant winner the Data Mesh?
Understanding Data Mesh
The concept of a Data Mesh was developed by Zhamak Dehghani:
A data mesh supports distributed, domain-specific data consumers and views “data-as-a-product,” with each domain handling their own data pipelines. The tissue connecting these domains and their associated data assets is a universal interoperability layer that applies the same syntax and data standards (Figure 5).
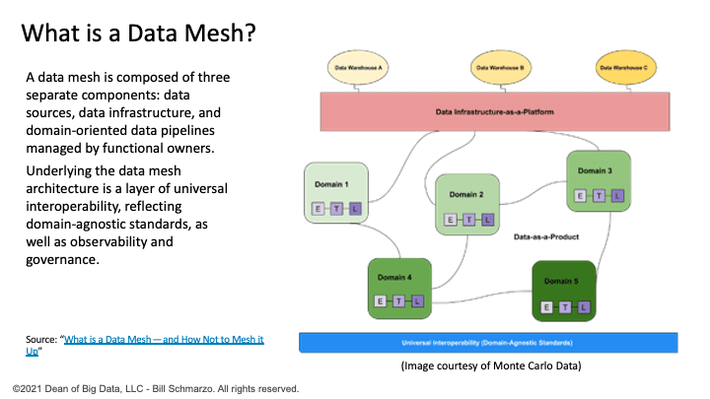
Figure 5: What is a Data Mesh?
The data mesh encourages distributed groups of teams to manage data as they see fit with common governance provisions. Per Dehghani, data transformation cannot be hardwired into the data by engineers, but instead should be a filter that is applied to data that’s then available to all users. So instead of building a complex Rube Goldberg system of ETL pipelines to move and transform data to specialized repositories, the data is retained in its original form and a series of domain-specific teams take ownership of that data[1].
While I am eager for any technology that can mitigate the unnecessary duplication and proliferation of the same data sets across a multitude of data repositories, it seems that a Data Mesh is not really a data architecture (like a Data Fabric) but is more of a governance model with respect to who has responsibility for the management and governance of data captured by different parts of the organization.
Data Meshes and the Economics of Data
One of my biggest issues with the Data Mesh concept is that it necessitates making everyone a data management and data governance expert. This places the success of the organization’s overall data management (data science, data monetization) strategy into the hands of people whose primary focus, priorities, and loyalty are to the business unit, not the enterprise. As a result, we could end up optimizing data management and data governance execution at the Business Unit level while sub-optimizing data management and data governance at the larger enterprise level.
With the Data Mesh, data management responsibilities remain with the organization that “created” the data. But what happens if another organization needs additional data to support its business KPIs? Do they negotiate with that organization to change their data capture processes to capture these new data elements?
For example, let’s say our Call Center captures the data necessary to manage and optimize the KPI’s against which the Call Center measures business and operational success. However, what happens if Marketing and Product Development need additional data elements to be captured during the call center interaction to optimize their KPIs? Do Marketing and Product Development have to “contract” to the Call Center operations for the capture and management of that data? Does every department that needs additional Call Center data elements also need to “contract” to Call Center operations for the capture and manage their specific data requests (Figure 6).
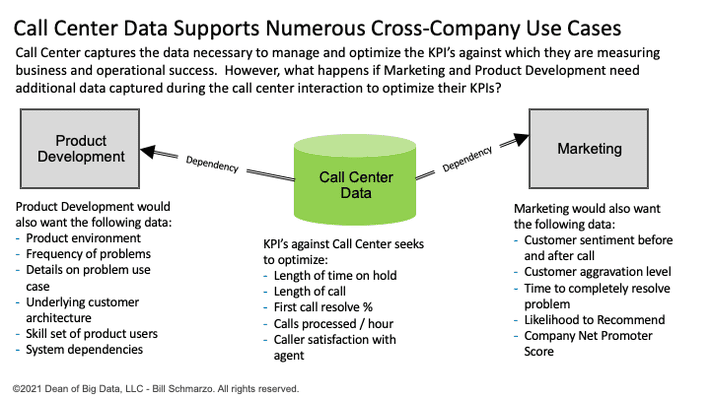
Figure 6: Business Unit versus Enterprise View of Data
I’m struggling with the domains that created that data then becoming the organization responsible for managing that data. The potential for disparate data and analytic efforts abounds (for example, each business unit creating their own Credit Risk Score and Customer Lifetime Value Score that only pertains to their specific business unit without consideration of the larger enterprise view).
Summary: Activating the Economics of Data
The seamless ability for the organization to easily share, reuse, and continuously refine the enterprise’s data and analytic assets is the key to the Data Economic Multiplier Effect and the Marginal Propensity to Reuse (MPR) that fuels the Economic Digital Asset Valuation Theorem (Figure 7).
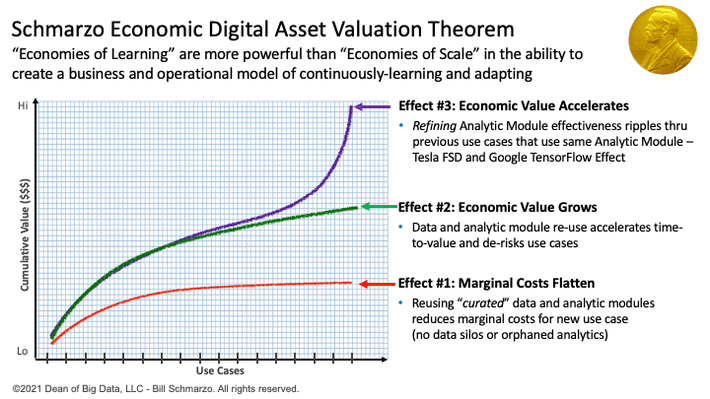
Figure 7: Economic Digital Asset Valuation Theorem
If organizations want to exploit the unique economic characteristics of data – an economic asset that not only never depletes, never wears out, and can be used across an unlimited number of use cases at zero marginal cost but can actually appreciate in value the more that it is used – the organizations must embrace a more holistic enterprise strategy for the capture, reuse, refinement, and monetization of their data and analytic economic assets.
[1] “Data Mesh Vs. Data Fabric: Understanding the Differences” by Alex Woodie
Source: https://www.datanami.com/2021/10/25/data-mesh-vs-data-fabric-unders…
{kind=link}