

Contributed by Kelly Mejia Breton. She graduated from the NYC Data Science Academy 12 week full time Data Science Bootcamp program taking place between April 11th to July 1st, 2016. This post is based on her final class project – Capstone, due on the 12th week of the program. The original article can be found here.
Have you ever seen a marketing ad for a movie and thought, wow I have to see that! Then you go see it, it’s a great film, the actor roles are amazing, in your book it’s won an Oscar, and it’s not even nominated? What makes viewers rank a movie in the top ten, is there an underlying marketing strategy within the details of the movie such length, genre, rating? Is there a good model fit to predicting if a top ten film, ranked by viewers, will win an Oscar?
My client is a fashion designer who provides clothing for celebrities and has hired me to answer these questions. This year for the academy awards they would like to only dress those who have a high likelihood of wining an Oscar given the film was ranked top 10 by viewers. Their goal is for their designs to live long after the red carpet, in the photos and video clips that follow for years to come when the award is mentioned.
The Dataset
The data is a combination of the Blockbuster Database and Oscar Demographics dataset provided by Open Data Soft. Containing the top ten annual films for the past 40 years ranked by IMDb (Internet Movie Database) viewers. Using the Oscar dataset to create a classification column to record whether the film or anyone or anything affiliated with the film won an Oscar. The original dataset contained 398 observations and 21 variables.
Exploratory Data Analysis
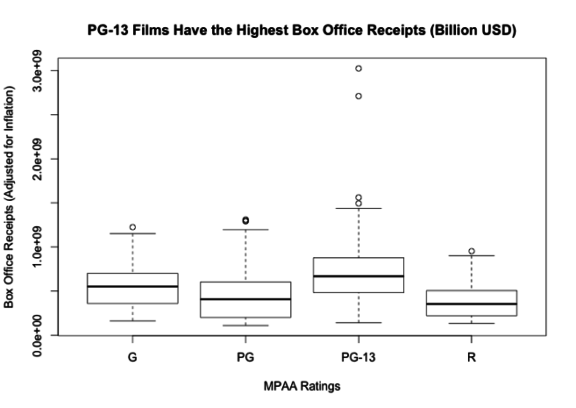
Exploring the distribution of the MPAA Ratings we see PG 13 films have the highest box office receipts, followed by General Audience films, then PG and final rated R films.
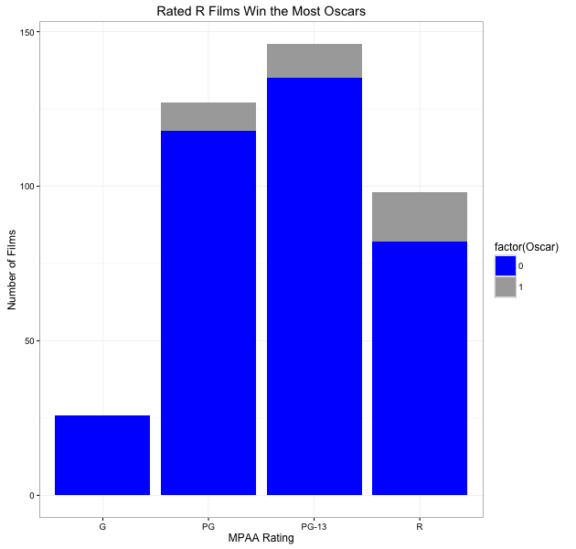
Now taking a look at the proportion of films who won Oscars by ratings. We see on the contrary those films rated R, have won the most Academy Awards, where films rated G for general audience have not won any Oscars in this dataset. Interesting, seems like there is a trade off with box tickets and Oscars.
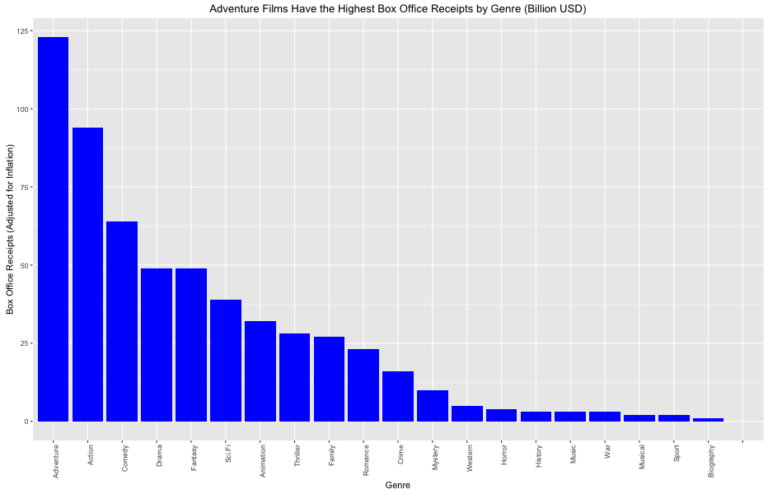
By Genre, box office sales are the highest for Adventure films followed by Action films.
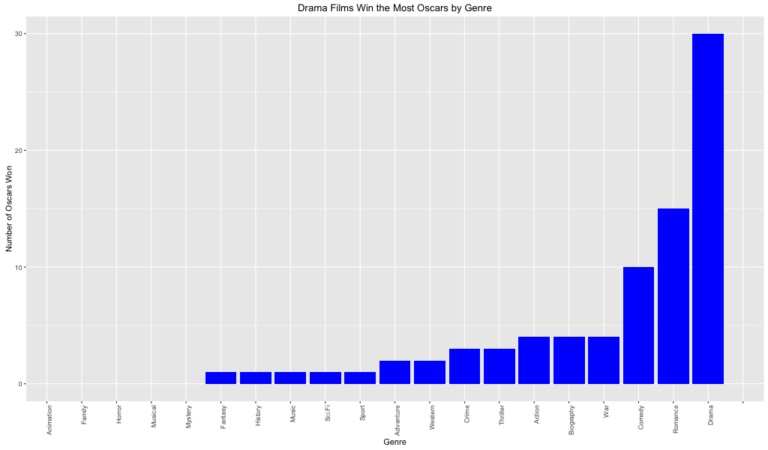
Oscar winners the highest are Drama followed by Romance. Just looking at some EDA charts I would advise my client as a general rule to pick a rated R film with a drama genre and their likelihood of winning the oscars would increase.
Unsupervised Learning: K-Means
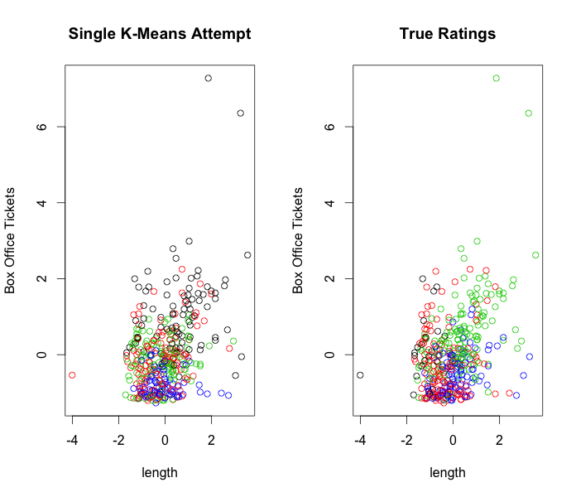
I wondering if there are groups within our dataset that tell us some additional information? KMeans with 4 clusters with the length of the movie and box office tickets alone we are unable to tell the rating of the movie, although if you look very closely you can see that there is a rating group that tends to have longer films with higher box office sales. But the other groups do not seem to be so defined. This could definitely be looked into further. Maybe help cut down some of data collection time.
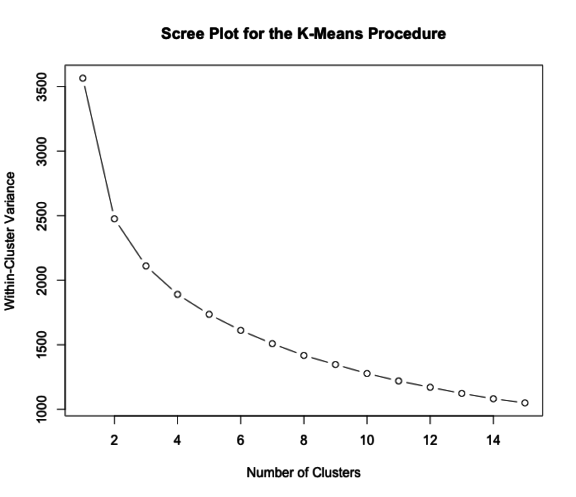
After fitting different clusters taking a look at a scree plot to help determine the number of clusters, we see that maybe kmeans is not a good option for the movies data since there isn’t a strong defined elbow, where the within-cluster variance no longer decreases.
Machine Learning – Logistic Regression
| Coefficients: | |||||
| Estimate | Std. Error | z value | Pr(>|z|) | ||
| Box Office Tickets | -2.26E-09 | 1.34E-09 | -1.688 | 0.09139 | . |
| IMDb Rating | 2.83E+00 | 9.52E-01 | 2.975 | 0.00293 | ** |
| Rank in Year | -2.80E-01 | 1.37E-01 | -2.044 | 0.04093 | * |
| Romance | 2.43E+00 | 8.36E-01 | 2.908 | 0.00364 | ** |
| Drama | 1.56E+00 | 7.97E-01 | 1.962 | 0.04972 | * |
| Adventure | -3.35E+00 | 1.36E+00 | -2.466 | 0.01366 | * |
| Western | 2.64E+00 | 1.30E+00 | 2.029 | 0.04241 | * |
| Signif. Codes: | 0 ‘** | *’ 0.001 ‘* | *’ 0.01 | ‘*’ 0.05 | ‘.’ 0.1 ‘ ’ 1 |
I fit a logistic regression and received a significant coefficients for Box office tickets, IMDb Rating, Rank in Year, Romance, Drama, Adventure, Western. Returning a true negative of 98.63% and true positive of 81.48%
Not bad. After fitting a reduced model with only the significant coefficients I increased my type II error, and reduced my true positives rate by over 30% to 47%.
Machine Learning – Random Forest
Let’s try fitting a Random Forest
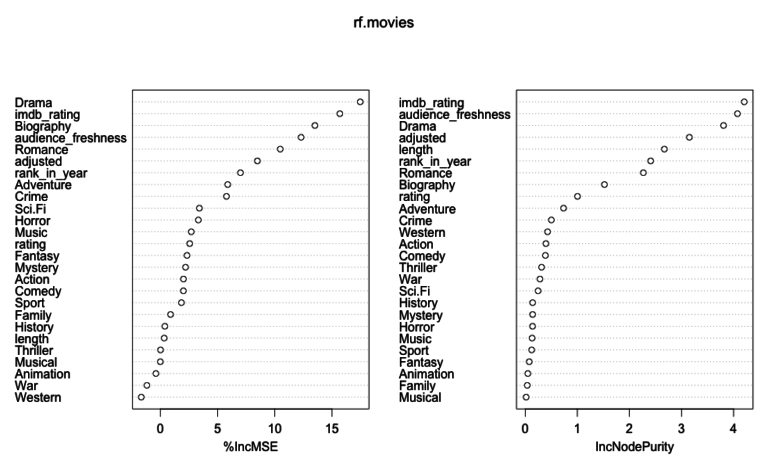
with 8 variables selected at random and and 500 trees, the train set returned a true negative rate of 70% and a true positive rate of 55% the test set returned a true negative of 97.14% slightly lower than the training set as expected and a true positive of 33%.
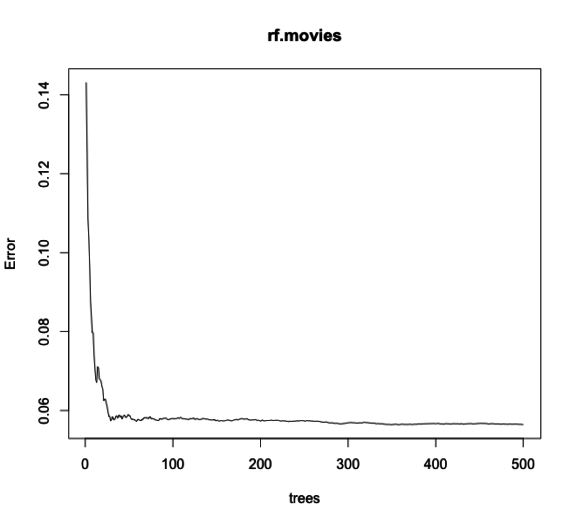
I took a look at the number of trees by errors, see if I can tune the number of trees. I tried lower number of tree which increased % of variance explained which is great but ultimately lowered my true positive and true negative percentage.
Next Steps
Gathering more data on the movies that win Oscars, to improve the algorithm
Research if there is a pattern within movie titles? Do the titles tend to have positive, negative, or neutral words?
Looking at the production studios to see if certain studios tend to receive more Oscar awards? If so add it to the model
Look at the area under the curve, adjust my threshold to have better sensitivity and specificity.
Finalize my shiny app.
{kind=link}