
R-squared can help you answer the question “How does my model perform, compared to a naive model?”. However, r2 is far from a perfect tool. Probably the main issue is that every data set contains a certain amount of unexplainable data. R-squared can’t tell the difference between the explainable and the unexplainable , so it will go on, and on, trying to perfect its goal. If you keep on “perfecting” with r-squared by adding more predictors, you’ll end up with misleading results, and reduced precision.Some of the other issues include:
- R-squared is heavily dependent on the dataset you’re feeding into it. While in some cases it can be useful to take a look at what your data is doing, in many “real world” situations you want to know more than just what’s in your data; You want predictions, and r-squared is not a predictive tool.
- While r2 can be an excellent tool for comparing with a naive model, sometimes you might want to know how your model compares to a true model instead, and r-squared isn’t able to tell you that.
- R-squared tends to be a little bipolar; A high r2 might be preferred in some cases, while a low r2 might be preferred in other cases. This can obviously get confusing.
- Overfitting can be a huge issue. Overfitting is where too many predictors and higher order polynomials in a model lead to random noise being modeled, instead of the real trend.
- R-squared for a model can go down, even when it is becoming a better approximation to the true model.
Pluses and Minuses with R-Squared
In general, r-squared is often the “go to” because it’s easy to use and understand. Practically all statistical software includes it–even basic tools like Excel’s data analysis. You simply check a box, et voila! The software gives you the percent variation in y that your model explains.
One of the main drawbacks to r2 is that you can keep on adding terms to your model to increase it. Model not quite up to par? Add a few more terms and it will be. Add a few more, and any model–even the bad ones– could hit 99%. Basically, if you don’t know your data inside out (and for large sets of data, you probably won’t), then it can be challenging to know when to stop adding terms.
Alternatives
A perfect alternative to r-squared doesn’t exist: every choice has its pluses and minuses.
1. Adjusted R-Squared
Adjusted R-Squared is a correction for adding too many terms to the model. It will always be lower than R-squared, and tends to be a better alternative. However, it suffers from many of the same pitfalls of plain old r2. Perhaps the most important drawback is that it isn’t predictive, and simply deals with the data you feed into it.
2. Predicted R-Squared
Predicted R-squared (PRESS or predicted sum of squares) avoids the “it only deals with the data at hand” problem. It gauges how well a model accounts for new observations. As well as its predictive capabilities, a key plus is that it can help prevent overfitting; if there is a large difference between your r2 and predictive r2 values, that’s an indication you have too many terms in your model.
A big minus: it is not widely available. At the time of writing, Excel doesn’t include it, nor does SPSS (although they have published a workaround). A few options:
- Minitab added Predicted r2 to Minitab 17
- In R, some packages (like DAAG) include Predicted r2. PRESS can also be implemented as part of the leave-one-out cross validation process (see Theophano Mitsa’s post for more details).
3. Formula Tweaks
There are more more than a few formulas for r-squared (defining them all is beyond the scope of this article, but if you’re interested, see Kvalseth et. al, as cited in Alexander et. al). A simple, and common formula is shown below. Some alternatives to this particular formula include using the median instead of the summation (Rousseeuw), or absolute values of the residuals instead of the square (Seber).
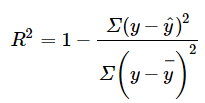
More formula tweaks deal specifically with the problem of outliers. Having them in your model could pose a problem: least squares r-squared for variable selection in a linear regression model is sensitive to outliers. According to Croux & Dehon, the addition of just one single outlier can have a drastic effect. An alternative, R2LTS, ( Saleh), uses least trimmed squares; The author reports that this method is not sensitive to outliers. Rousseeuw uses an M-estimator to achieve a similar effect.
4. Simply Report the Statistics
Sometimes, you just can’t avoid reporting r2, especially if you’re publishing a paper. If you can’t avoid r-squared, the alternative is to use it, but wisely. Alexander et al. suggest that you:
- Get the r-squared value from test data using the above equation, not from a regression of observed on predicted values, and
- “…simply report the R2 and RMSE or a similar statistic like the standard error of prediction for the test set, which readers are more likely to be able to interpret.”
References
Why I’m not a fan of R-squared
Can we do better than r-squared?
Multiple Regression Analysis: Use Adjusted R-Squared and Predicted …
Model selection via robust version of r-squared
Mitsa, T. Use PRESS, not R squared to judge predictive power of regression. Beware of R2: simple, unambiguous assessment of the prediction accu…
Kvalseth et. al. Cautionary note about R 2. The American Statistician, November, 1985
Rousseeuw PJ. Least Median of Squares Regression. J. Am. Stat. Assoc. 1984;79:871–880
Seber GAF. Linear Regression Analysis. John Wiley & Sons; NY: 1977. p. 465
){kind=link}