
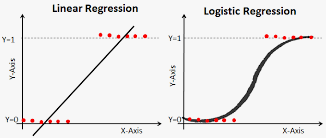
Logistic regression (LR) models estimate the probability of a binary response, based on one or more predictor variables. Unlike linear regression models, the dependent variables are categorical. LR has become very popular, perhaps because of the wide availability of the procedure in software. Although LR is a good choice for many situations, it doesn’t work well for all situations. For example:
- In propensity score analysis where there are many covariates, LR performs poorly.
- For classifications, LR usually requires more variables than to achieve the same (or better) misclassification rate than Support Vector Machines (SVM) for multivariate and mixture distributions.
In addition, LR is prone to issues like overfitting and multicollinearity.
A wide range of alternatives are available, from statistics-based procedures (e.g. log binomial, ordinary or modified Poisson regression and Cox regression) to those rooted more deeply in data science such as machine learning and neural network theory. Which one you choose depends largely on what tools you have available to you, what theory (e.g. statistics vs. neural networks) you want to work with, and what you’re trying to achieve with your data. For example, tree-based methods are a good alternative for assessing risk factors, while Neural Networks (NN) and Support Vector Machines (SVM) work well for propensity score estimation and Categorization/Classification.
There are literally hundreds of viable alternatives to logistic regression, so it isn’t possible to discuss them all within the confines of a single blog post. What follows is an outline of some of the more popular choices.
Read the full article, here.
{kind=link}