
 In the last post, we discussed an outline of AI powered cyber attacks and their defence strategies. In this post, we will discuss a specific type of attack which is called adversarial attack.
In the last post, we discussed an outline of AI powered cyber attacks and their defence strategies. In this post, we will discuss a specific type of attack which is called adversarial attack.
Adversarial attacks are not common now because there are not many deep learning systems in production. But soon, we expect that they will increase. Adversarial attacks are easy to describe. In In 2014, a group of researchers found that by adding a small amount of carefully constructed noise, it was possible to fool CNN/ computer vision. For example, as below, we start with an image of a panda, which is correctly recognised as a panda with 57.7% confidence. But by adding the noise, the same image is recognised as a gibbon with 99.3% confidence. For the human eye, both images look the same but for the neural network, the result is entirely different. This type of an attack is called an adversarial attack and it has implications for self driving cars where traffic signs could be spoofed.
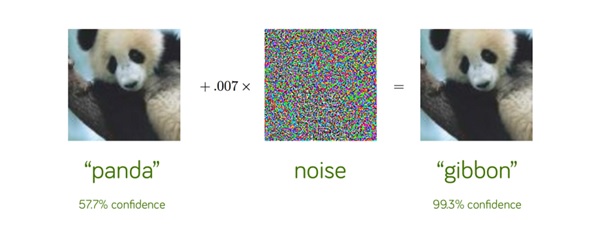
Source: Explaining and Harnessing Adversarial Examples, Goodfellow et al, ICLR 2015.
There are three scenarios for this type of attack:
- Evasion attack: this is the most prevalent sort of attack. During the testing phase, the adversary tries to circumvent the system by altering harmful samples. This option assumes that the training data is unaffected.
- Poisoning assault: This form of attack, also known as contamination of the training data, occurs during the machine learning model’s training phase. An opponent attempts to poison the system by injecting expertly produced samples, so jeopardizing the entire learning process.
- Exploratory attack: Exploratory attacks have no effect on the training dataset. Given Blackbox access to the model, they aim to learn as much as they can about the underlying system’s learning algorithm and patterns in the training data so as to subsequently undertake a poisoning or an evasion type of attack
The majority of attacks including the above mentioned takes place in the training phase are carried out by directly altering the dataset to learn, influence, or corrupt the model. Based on the adversarial capabilities, attack tactics are divided into the following categories:
- Data injection: The adversary does not have access to the training data or the learning algorithm, but he does have the capacity to supplement the training set with new data. By injecting adversarial samples into the training dataset, he can distort the target model.
- Data manipulation: The adversary has full access to the training data but no access to the learning method. He directly poisons the training data by altering it before it is used to train the target model.
- Corruption of logic: The adversary has the ability to tamper with the learning algorithm. It appears that devising a counter strategy against attackers who can change the logic of the learning algorithm, so manipulating the model, becomes extremely tough.
During testing, adversarial attacks do not interact with the intended model, but rather push it to provide inaccurate results. The quantity of knowledge about the model available to the opponent determines the effectiveness of an assault. These assaults are classified as either Whitebox or Blackbox attacks. We present a formal specification of a training procedure for a machine learning model before considering these assaults.
White-Box Attacks
An adversary in a Whitebox assault on a machine learning model has complete knowledge of the model used (for example, the type of neural network and the number of layers). The attacker knows what algorithm was used in training (for example, gradient descent optimization) and has access to the training data distribution. He also understands the whole trained model architecture’s parameters . This information is used by the adversary to analyze the feature space in which the model may be vulnerable, i.e., where the model has a high mistake rate. The model is then exploited by modifying an input utilizing the adversarial example creation method, which we’ll go through later. A Whitebox assault that has access to internal model weights is equivalent to a very strong adversarial attack.
Black Box Attacks
A Blackbox attack assumes no prior knowledge of the model and exploits it using information about the settings and prior inputs. In an oracle attack, for example, the adversary investigates a model by supplying a series of carefully constructed inputs and observing outputs.
Adversarial learning poses a serious danger to machine learning applications in the real world. Although there are certain countermeasures, none of them can be a one-size-fits-all solution to all problems. The machine learning community still hasn’t come up with a sufficiently robust design to counter these adversarial attacks.
References:
{kind=link}