

Abstraction: some succinct definitions.
“Abstraction is the technique of hiding implementation by providing a layer over the functionality.
Abstraction, as a process, denotes the extracting of the essential details about an item, or a group of items, while ignoring the inessential details
Abstraction Its main goal is to handle complexity by hiding unnecessary details from the user”
Abstraction as a concept and implementation in software engineering is good. But when extended to Data Science and overdone, becomes dangerous.
Recently, the issue of sklearns default L2 penalty in its logistic regression algorithm came up again.
This issue was first discovered in 2019 by Zachary Lipton.

On the same issue, an excellent blog titled Scikit-learns Defaults are wrong was written by W.D. Here is the link to that article.
This article IMHO is a must read for any serious Data Scientist.
While the author of the article has excellently captured the design pattern flaws, I would just like to build on it and add the problem of Too much abstraction.
In one of my previous article, I had highlighted how abstracting away GLM in sklearns logistic regression makes large number of people believe that Regression in Logistic Regression is merely a misnomer and it has nothing to do with Regression!!
Below is an image from that article highlighting the issue.

So, why is Too much abstraction a problem in Data Science?
I took the liberty of modifying Francois chollets famous diagram on difference between traditional programming and ML to drive home some important points regarding too much abstraction.
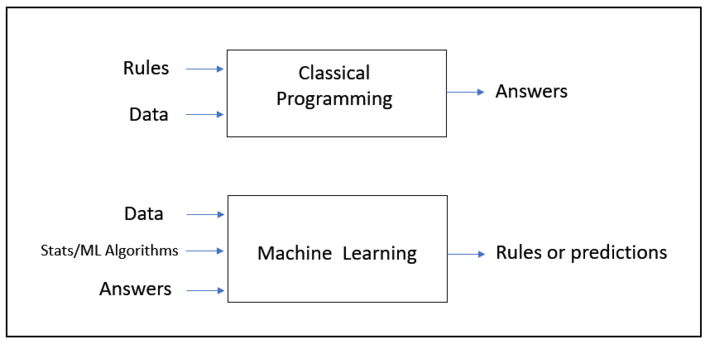
Firstly, in normal programming, if you do abstraction, you just abstract away the fixed rules. This works out fine in software development realm as you dont want certain people to tinker around fixed rules or they simply dont care how things work under the hood.
But in Data science, if you do too much abstraction, you are also abstracting away the intuition of how the algorithm works and most importantly you are hiding away the knobs and levers necessary to tweak the model.
Lets not forget that the role of data scientist is to develop intuition of how the algorithms works and then tweak the relevant knobs/ levers to make the model a right fit to solve business problem.
Taking this away from Data Scientists is just counter intuitive.
These aside, there are other pertinent questions on too much abstraction.
Lets revisit one of the Abstraction definitions from above: Abstraction Its main goal is to handle complexity by hiding unnecessary details from the user.
When it comes to data science libraries or low code solutions, the question arises who decides what is unnecessary? Who decides which knobs and levers a user can or cant see and tweak?
Are the people making these decisions well trained in Statistics and machine learning concepts? or are they coming from a purely programming background?
In this regard I cant help but loan some apt excerpts from W.D s article One of the more common concerns youll hearnot only from formally trained statisticians, but also DS and ML practitionersis that many people being churned through boot camps and other CS/DS programs respect neither statistics nor general good practices for data management.
On the user side in Data Science, here are the perils of using libraries or low code solutions with too much abstraction.
- Nobody knows the statistical/ML knowledge level of the user or the training they may or may not have had.
- At the hands of a person with poor stats/ML knowledge these are just execute the lines with closed eyes and see the magic happen.
The dangers of doing Data Science wrongly just becomes that much exacerbated. Not to mention You dont need math for ML and Try all models kind of articles encouraging people to do data science without much diligence. Any guesses for what could go wrong ?
Data science is not some poem that it can be interpreted in any which way. There is a definitive right and wrong way to do data science and implement data science solutions.
Also, Data Science is just not about predictions. How these predictions are made and what ingredients led to those predictions also matter a lot. Too much abstraction abstracts out these important parts too.
Read the Documentation
Coming to defense of these too much abstracted libraries and solutions, some remark the user should Read the documentation carefully and in detail.
Well not many have the time and most importantly some low code solutions and libraries are sold on the idea of Perform ML in 23 lines of code or Do modelling faster.
So again, referencing W.D, read the doc is a cop-out. Especially if it comes from low code solution providers.
A Bigger Problem to Ponder Upon
Having said all this, Sklearn is still by and large a good library for Machine Learning. The problem of L2 default might be one of the very few flaws.
However, I would urge the readers to ponder over this:
If abstracting away some details in one ML algorithm could cause so much issues, imagine what abstracting away details from dozen or so ML algorithms in a single line of code could result in. Some low code libraries do exactly that.
I am not against abstraction or automation per say. My concern is only with too much abstraction . And I dont have a concrete answer for how to tackle too much abstraction in data science libraries. One can only wonder if there is even a middle ground.
But one thing is very clear. The issues of too much abstraction in Data Science are real.
The more one abstracts away, the more is the chance of doing data science wrongly.
Perhaps all we can do is, be wary of low code solutions and libraries. Caveat emptor.
{kind=link}