
One of our business units wants to target the competitors’ customers with personalized product/offer. To do that, Business needs to understand who are the prepaid/postpaid customer of the competitor to push the relevant and personalized product/offer and they don’t have this data. Now, this is a binary classification problem and we want to apply machine learning machine method to predict the likeliness of competitor customer to be prepaid or postpaid.
Steps in Data Science project: To solve the problem I followed following steps from data gathering to model selection
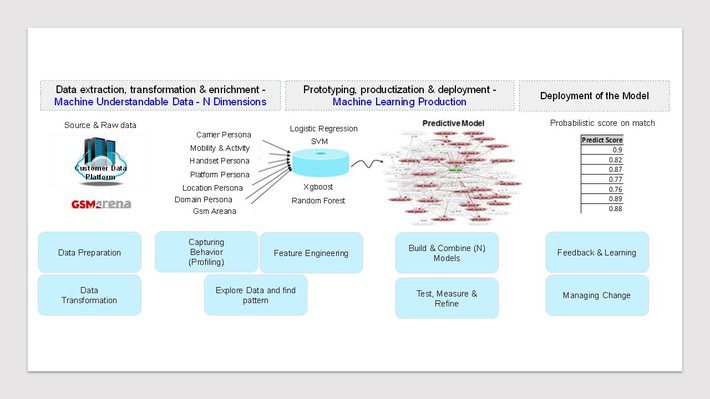
Gather Data: Business unit has 3rd party data from a vendor company where carrier wise each of internet transaction has been captures from the pixel implementation in the website and mobile app. It covers 20%-30% of internet transaction in market that includes all the self-owned properties e.g. own App, own website and other 3rd party data Agoda, travoloka etc. It also mapped with first party mobile number by encryption/decryption process. To train the model, I have used own customer as my truth set and its prepaid/postpaid customer for labeling the data.
Clean Data and Create Feature Variables: Working 3rd party internet data has lot of unstructured and unnecessary data points. So, I have to create a feature variable dataset from the URLs and major captured KPIs like carrier, device, platform, location.
Following persona and feature variables has been created using bigquery
- Activity: Activities segmented into different time features (weekend, monthly decile, and morning/evening)
- Carrier: Carrier breakdown by total number of transactions, average transactions, per day, per month, share of wallet for each carrier
- Device: Device breakdown by screen size, battery, camera pixel, top device,
- Mobility: Mobility profile based on location information (postcodes)
Explore Data and find pattern: After creating the feature variables, I have used google datastudio to visualize the data and see the partners. We have also done principal component analysis (PCA) to see the most significant variables along with key statistical parameters mean, median, standard deviation, max, percentile to see the pattern of truth set. Also see the correlation among the two groups.
Construct and fit Model: I have applied couple of approaches: Balanced, unbalanced, up sampling, down sampling to compare the result. To train the model for each of the approaches, I have run logistic regression, Random forest, XGboost and SVM algorithm to compare the result. I have used sklearn library to run the code.
However, for testing and validation, I also keep 20% as test base and a master validation base which is the representative of whole base.
To evaluate the performance of the developed models and compared the best-performing algorithms of each ML model with conventional logistic regression (CLR) by measuring the area under the receiver operating characteristic (ROC) curves (AUC) on the combined set, which includes the training and test sets. Comparisons of the ROC curves were done with the test set and master validation set. Average precision Recall (AP), F-score, accuracy score and confusion matrix has also been calculated for the test set and master validation set.
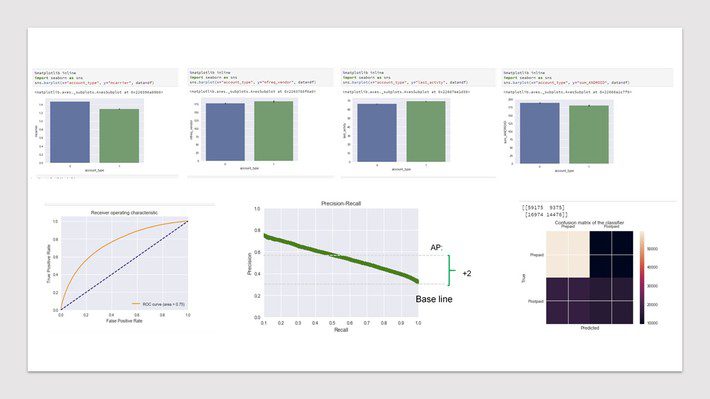
I have also run the cross validation to assurance that model has got most of the patterns from the data correct, and it’s not picking up too much on the noise, or in other words its low on bias and variance.
Feedback and learning:
Once model has been developed, it was presented to business team from layman perspective. Business accepted the outcome and had decided to test the model output in real life. I have extracted a sample output from the model with the highest probability and run a test campaign to see the actual result. An A/B test campaign was run with model output with regular audience for that campaign. Based on the test result, model has been handed over to technical team to deploy.
{kind=link}