

Most ML developers today are not familiar with causal models.
Current ML models are based on co-relation.
In contrast, causal models deal with cause and effect. Furthermore, correlation-based models have limited explainability, do not handle novel situations well, and need a lot more data.
Causal models overcome many of these limitations.
Causal models can answer what-if (counterfactual) questions.
We can see the range of strategies below
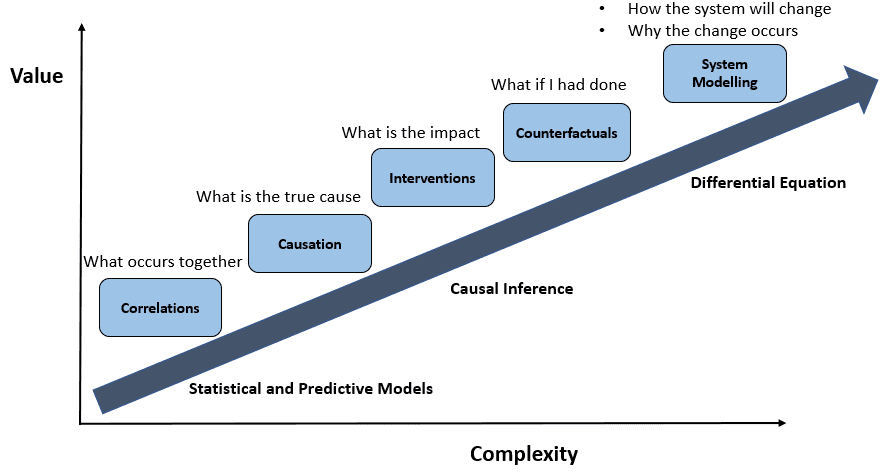
Randomized Control Trials come closest to this approach but these strategies are expensive and time-consuming. They are mostly used in medical fields where they are mandated and involve risks to the participants.
Causal models are becoming more popular for example the recently announced pywhy library as a collaboration with Microsoft Research and AWS
Its easier to explain causal modes with practical examples
- Churn reduction: While conventional AI systems can predict likely churners, they don’t recommend a course of action to prevent churn.
- Counterfactual questions: ‘what would happen if investment were to increase by 4%?’
- Use with Alternate data – forecasting retail sales with footfall data
MiKinsey also recently released a new causal library called CausalNex
Using CausalNex, data scientists can ask “what if this underlying variable was different?”, and observe the size of the impact. This can help tease out the highest-value features which can then be used to effect change.
I see this trend continuing as Causal ML gets more mainstream
References: https://www.causalens.com/reports/
Image source: https://towardsdatascience.com/causal-ai-enabling-data-driven-decisions-d162f2a2f15e
{kind=link}