

The previous post covered the problem of oversiloing. Systems thinking, I pointed out, can help reduce the practice of siloing when it’s not necessary.
In earlier posts, I’ve contrasted the difference between provincial IT and data-centric IT:
- Provincial IT is no longer necessary given the advances in compute, networking and storage we’ve seen over the last 30 years.
- In spite of this, most enterprises still unknowingly contribute to the complexity caused by obsolete provincial IT architecture by continuing to invest in legacy hindered application-centric systems.
- Data science as a discipline is therefore inhibited by the installed base of application-centric complexity that feeds on itself, with code and duplicated data silo sprawl that continually adds to the complexity. (Search on Dave McComb and Software Wasteland to find the book with his full argument and analysis regarding the waste of application centric systems).
In this post, I’ll focus on feedback loops best suited to take advantage of architecturally transformed data-centric systems. First I’ll consider how manual steps to create feedback loops have grown, by exploring an example from collaborative genealogy. Then I’ll elaborate on how systems design could eliminate manual work and upgrade the feedback loops we have.
Genealogy research: Relatedness is a bigger deal than we imagined
In a 2002 Atlantic article entitled “The Royal We”, Steve Olson made the following assertion:
“The mathematical study of genealogy indicates that everyone in the world is descended from Nefertiti and Confucius and everyone of European ancestry is descended from Muhammad and Charlemagne.”
Olson later on cited the work of Joseph Chang, a Statistician at Yale, as follows:
“Go back forty generations, or about a thousand years, and each of us theoretically has more than a trillion direct ancestors—a figure that far exceeds the total number of human beings who have ever lived.”
What Chang did was provide an informed estimate using math and facts about human ancestry.
The bottom line of the Olson’s article was that, if you go back far enough in history, every human ever born is related to everyone else. Math lets you know that even with low migration rates, if you go back to 5,000 BC, everyone ever born will share a common ancestor.
Genealogy and data science
Genealogy is one of many industries that could thrive with a data-centric architecture. That industry provides a helpful example of where online-only enterprises stand architecture-wise, what they’re doing well, and how they could improve.
Each genealogy service is essentially a giant feedback loop, or more accurately, a lot of little feedback loops, with humans and machines working together to add, correct and refine the data in each database.Ancestry.com is the best known of these subscription-only services, but there are many others.
One of the main problems these services have is the quality of the contributions and proof (in the form of documentation) provided. There’s a garbage-in-garbage-out threat that looms over each relationship in the shared family tree. You and your cousins who are contributing might have a very careful methodology for disambiguating and proving the facts behind particular family member records with documentation, but there are others who may not be as careful.
The result? Uncertainty, duplication of effort, and a lot of research that gets wasted when users follow false paths in what’s supposed to be their tree too.
All feedback loops aren’t created equal
Human-to-human feedback loops are ubiquitous. New workers learn from veteran co-workers. Children learn from parents. Younger siblings learn from older siblings and friends.
If this knowledge were more broadly shared with well-designed human-to-machine feedback loops, machines and many more people could both benefit.
There are three kinds of feedback loops:
- Virtuous: the kind that provides lasting benefits to the system and the users and other beneficiaries of the system.
- Neutral: the kind that doesn’t really have any lasting effect one way or the other.
- Degenerative: The kind that undermines the goals of maintaining the system or contributes to the breakdown of the system.
The best parts of the media ecosystem function as a means of information sharing and refinement–dynamic, evolving and virtuous feedback loops.
In a virtuous human-machine feedback loop, data improvement is the result. Remember that raw data is at the bottom of the knowledge pyramid. Humans inside the loop work with machines on a single or multiple domains to build a form of organically growing knowledge. Knowledge contains insights. At the top of the pyramid is actionable knowledge.
Revisiting the feedback loop: Second-order cybernetics
Back in 1976, Gregory Bateson, Margaret Mead and Stewart Brand got together to revisit Norbert Wiener’s feedback loop and discuss what they thought Wiener really meant. Brand later published an edited transcript of the conversation in his Co-Evolution Quarterly.
Initially, computer scientists after studying Wiener came up with a feedback loop design with the engineer outside the box. That’s how cybernetics was previously represented: a computer science-influenced input-output diagram with a single loop–the topmost diagram below.
Bateson suggested that Wiener intended that humans be represented in a second feedback loop. The bottommost diagram represents the dual-loop feedback the group in 1976 discussed.
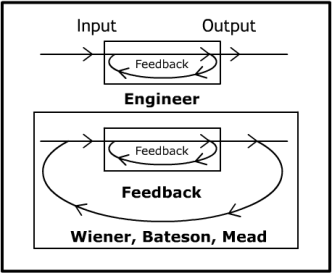
Bateson’s summary: “What Wiener says is that you work on the whole picture and its properties. Now, there may be boxes inside here, like this of all sorts, but essentially your ecosystem, your organism-plus-environment, is to be considered as a single circuit.”
What’s the takeaway? The old computer science-influenced cybernetics model ignores the larger ecosystem, reinforcing provincial IT. By contrast, the dual-loop model includes humans from the larger ecosystem. Genealogy services echo this dual-loop model.
But unlike the current genealogy services industry, a desiloed, data-centric architecture approach wouldn’t have services in silos competing with one another. And feedback shouldn’t be limited by provincial IT assumptions.
As things stand today, most data scientists, focusing on one project at a time, unwittingly perpetuate overly limited feedback, guaranteeing that the work they’ll do will need to be redone, time and again. And the results of their efforts in any case will likely not be generalizable. Dual-loop or second order cybernetics with a knowledge graph foundation is a way to move beyond these limitations.
){kind=link}