
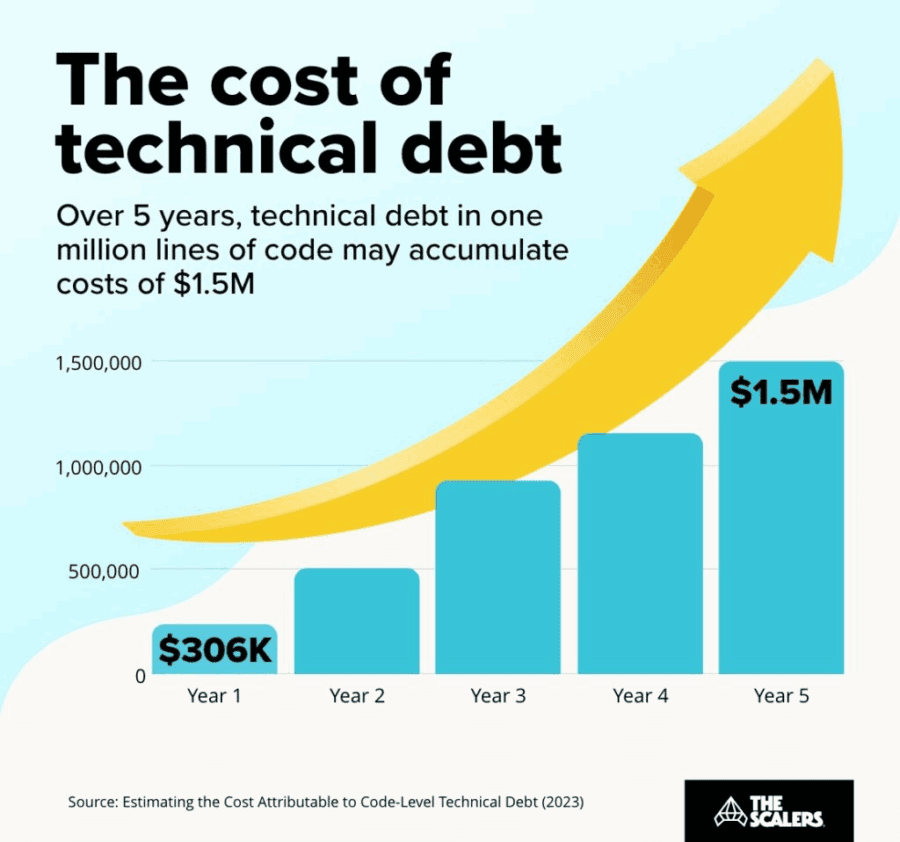
The cost of Technical Debt
Image Source: The Scalers (For illustrative purposes only)
Rudrendu Paul, Debjani Dhar and Ted Ghose co-authored this article.
In boardrooms across the globe, the conversation has shifted. It’s no longer a question of whether a company should adopt Artificial Intelligence, but rather how quickly it can be deployed to drive a competitive advantage. Yet, for many Chief Information and Financial Officers, a significant and costly obstacle stands in the way: the legacy Enterprise Data Warehouse (EDW).
For years, the decision to modernize has been framed by the cost of migration. But this perspective is dangerously incomplete. The real financial threat isn’t the price of moving to a modern data architecture; it’s the escalating, often hidden, cost of staying put. Leaders who delay this transformation are accumulating a form of technical debt so severe that it jeopardizes their ability to compete in the age of AI.
To make a sound financial decision, we need a new framework that calculates the Total Cost of Inaction. This model looks beyond simple maintenance fees to quantify the massive opportunity costs of being unprepared for an AI-driven future.
Data points
- The true cost of legacy data warehouses is not the maintenance fees, but the Total Cost of Inaction.
- This cost includes direct licensing, hidden operational inefficiencies, and the massive opportunity cost of being unable to launch AI initiatives.
- Legacy data architectures are fundamentally incompatible with the scalability and processing power required for modern AI and machine learning.
- We propose a new framework: TCI = (Direct Costs + Hidden Costs) + AI-Driven Opportunity Cost.
Reframing modernization as a strategic investment with a clear ROI, rather than a cost center, is essential for competitive survival in the age of AI.

Visible Cost vs Hidden Costs of Technical Debt in Businesses
Image Source: Nayeem Islam on Medium (For illustrative purposes only)
The visible costs: The tip of the iceberg
Any CFO can point to the direct costs associated with a legacy EDW. These are the familiar line items that appear in budget forecasts year after year.
- Exorbitant licensing and maintenance: Legacy on-premise data warehouses are notorious for their expensive, multi-year licensing agreements and mandatory maintenance contracts. These fees are often inflexible and scale poorly, penalizing companies for their own data growth.
- Infrastructure overhead: On-premise systems require a significant capital investment in servers, storage, and networking hardware. Beyond the initial purchase, there are ongoing operational expenses, including power, cooling, and the physical space required for the data center itself.
- Specialized (and dwindling) talent: The talent pool for maintaining decades-old database technologies is shrinking and becoming increasingly expensive. A lack of available in-house talent often forces enterprises to push maintenance to remote offshore teams.
While remote teams may offer short-term cost savings, the legacy technology frequently becomes unmanageable and disconnected from core business needs. Ad-hoc, remote management leads to inefficient processes, redundant development, and multiple, out-of-sync copies of data. Ultimately, companies find themselves paying a premium to simply maintain a fractured operation, diverting funds that could be invested in hiring data scientists and AI engineers.
While significant, these direct costs are merely the surface of a much deeper financial drain.
The hidden costs: What your balance sheet isn’t telling you
The most insidious costs of legacy data architecture are not reflected in vendor invoices, but rather are buried in operational inefficiencies and productivity losses throughout the organization.
- Productivity drain: Data teams spend an inordinate amount of time on manual tasks, performance tuning, and patching systems that were not designed for today’s data velocity and volume. This is the time they are not spending on value-added activities, such as building predictive models or uncovering new business insights.
The predominantly manual nature of working with these systems results in slow and error-prone processes, leading to costly rework. - Integration gridlock: A legacy EDW acts like a technological anchor, making it incredibly difficult and expensive to connect to modern cloud-based applications, SaaS platforms, and AI/ML services. Every new integration becomes a complex, time-consuming project, stifling innovation and agility.
- Mounting security and compliance risks: Older systems often lack the sophisticated, granular security controls of modern cloud platforms. As data privacy regulations become increasingly stringent, these legacy architectures pose a growing compliance risk, with the potential for financially devastating data breaches and substantial fines.
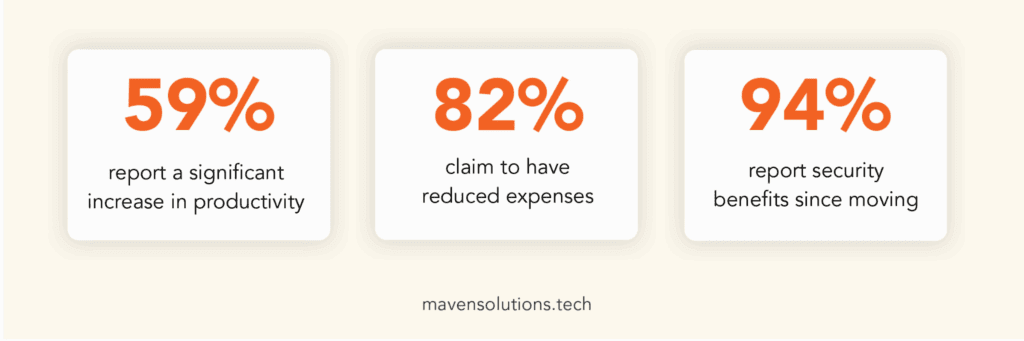
Opportunity Cost of Not Migrating Your Legacy Systems
Image Source: Maven Solutions Tech (For illustrative purposes only)
The opportunity cost: The massive price of being left behind
This is the most critical component of the Total Cost of Inaction and the one that legacy TCO models completely ignore. The inability to leverage AI isn’t a distant, abstract risk; it is a direct and immediate hit to the bottom line.
Legacy data warehouses are fundamentally incompatible with the demands of modern AI. They are often rigid, siloed, and lack the scalability and processing power required to train complex machine learning models on vast datasets. This technological mismatch translates into concrete business losses:
- Inability to launch AI initiatives: Companies struggle to develop AI-powered applications for dynamic pricing, supply chain optimization, predictive maintenance, and hyper-personalized customer experiences.
- Missed revenue streams: Without AI, businesses cannot effectively analyze customer behavior to identify upsell opportunities, reduce churn, or create new, data-driven products and services.
- Competitive erosion: While you are tethered to a legacy system, your competitors are using modern data platforms to make smarter decisions, operate more efficiently, and capture market share. The cost of inaction is the sum of every efficiency they gain and every customer they win, because their data infrastructure is AI-ready, while yours is not.
A framework for calculating the true cost of inaction
To gain a comprehensive understanding, leaders must adopt a holistic perspective. The formula is simple in concept but powerful in practice:
True Cost of Inaction (TCI) = (Direct Legacy Costs + Hidden Operational Costs) + AI-Driven Opportunity Cost
- Direct legacy costs: Sum of annual licensing, vendor maintenance, infrastructure hardware, energy, and specialized labor costs.
- Hidden operational costs: (Lost Productivity Hours of the Data Team for Manual Work) x (Fully-Loaded Hourly Cost) + (Estimated Financial Risk of a Data Breach).
- AI-driven opportunity cost: (Projected Revenue Lift from Top 2-3 AI Initiatives) + (Projected Cost Savings from AI-Driven Automation). This is the value of the future you are forgoing by not modernizing.
When calculated, this number is almost always far greater than the one-time cost of a migration project. It reframes modernization from a cost center into a strategic investment with a clear and compelling ROI, often realized in a matter of months, not years.
AI/ML-powered platform for Data Modernization Platform
Image Source: Microsoft Azure ML (For illustrative purposes only)
Addressing the enterprise data modernization gap
The primary reason this technical debt persists is that, historically, migration has been a high-risk, high-cost, and time-consuming endeavor. The industry’s response to this challenge has largely fallen into two categories, neither of which fully solves the core problem.
First are the large-scale, manual migration efforts, typically run by professional services firms. These projects rely on massive teams to manually convert complex business logic and code. The result is almost always a project that is slow, expensive, and prone to human error.
Second is the landscape of fragmented, point-solution tools. These tools may automate one piece of the puzzle, such as data migration, but they often fail to provide a comprehensive, end-to-end solution. This forces data teams to manually stitch together multiple tools and processes, reintroducing the very risk and inefficiency they were trying to avoid.
This hybrid approach is what makes leaders hesitate. The persistent industry gap has been the lack of a truly holistic automation platform that can manage the entire migration lifecycle from infrastructure and metadata to complex ETL re-engineering and data validation with provable, high fidelity.
Conclusion
The narrative of data warehouse modernization must change. It is not an infrastructure expense to be minimized, but a strategic imperative for survival and growth. By calculating the true cost of inaction, factoring in not just licensing and maintenance but the immense opportunity cost of being locked out of the AI revolution, the business case becomes clear.
Staying on a legacy platform is no longer a prudent financial decision; it’s an active acceptance of competitive disadvantage. The most expensive choice, by far, is to do nothing at all.
About the Authors

Rudrendu Paul https://www.linkedin.com/in/rudrendupaul/
Rudrendu Paul is an AI, marketing science, and growth marketing leader with over 15 years of experience building and scaling world-class applied AI and machine learning products for leading Fortune 50 companies. He specializes in leveraging generative AI and data-driven solutions to drive marketing-led growth and advertising monetization.
His work focuses on measurement science for marketing and advertising and driving growth in the retail media network (RMN) and e-commerce industries. He is a published author on AI with Springer Nature and Elsevier, and contributes to several leading AI and Analytics blogs and magazines.
Deb Dhar https://www.linkedin.com/in/debjanidhar/

Debjani (Deb) Dhar is a technology leader and entrepreneur who blends strategic delivery leadership and business development acumen with deep expertise in machine learning, data warehousing, and cloud architecture.
As the Co-founder of Novuz Inc., an AI- and ML-driven platform for end-to-end modernization and migration of enterprise data warehouses to the cloud, she is focused on enabling organizations to modernize their data ecosystems with speed and efficiency.
Before founding Novuz, Debjani served as a Delivery Executive at Accenture, where she led large-scale, multi-million-dollar modernization and transformation programs for global enterprises. At Novuz, she continues to bridge the gap between technology and business strategy—empowering enterprises to modernize legacy systems, accelerate data adoption, and unlock measurable business value.

Ted Ghose https://www.linkedin.com/in/ghose/
Ted Ghose is a visionary software architect and thought leader in designing distributed systems and scalable AI application infrastructure. He is known for transforming complex challenges into clear, maintainable systems that empower product growth and engineering velocity. With over 15 patents granted across cloud computing, data systems, and intelligent automation, he has a strong track record of delivering robust, reliable, and scalable software platforms.
{kind=link}