
An orrey or planetarium designed by George Adams showing relative positions of the planets in relation to the sun, 1799, https://www.loc.gov/pictures/item/2006691765.
Part I of II explored the concept of a metaverse or mirrorworld, and pointed out that even enthusiasts like Wired Co-Founder Kevin Kelly and Forbes contributor Charlie Fink believe that a mirrorworld–a dynamic digital skin that would usefully represent, monitor and shed insights on the interacting elements of our physical world–could well take 25 years or more to emerge.
Part I also concluded that the major obstacle to the creation and effective use of a metaverse or mirrorworld will be data (and knowledge, which is contextualized data with supporting relationship logic) management. More specifically, to be useful and accurate, interactive digital twins demand web-scale of interoperability–not just application scale.
The only way to achieve interoperability at scale will be by nurturing and enriching data and logic together more carefully and systematically than they have been with the help of system design innovation.
In other words, the more we generate and use data in new ways for more purposes, the more well have to be creative about how to manage it at scale. To use digital twins to manage physical assets at metaverse scale, well need to scale the management of data as an asset, by dynamically modeling those assets so that their interactions, not just the static views, are fully represented.
Part II explores what the metaverse/interactive digital twin data management challenges look like from a use case perspective. Lets take the utility industry as an example.
Utility industry digital twin data management challenges
The utility industry provides a good example of Internet of Things-scale data collection and digital twin-style simulation needs. The industry has to generate and distribute power broadly across continents, a very asset-intensive environment. These assets also often have to be in places threatened by various kinds of natural disasters.
Its an industry that must deal with a mixed bag of legacy central utility assets alongside contemporary, more decentralized, solar and wind power generation, storage and distribution. Stewards from many different public natural gas and electric organizations manage the mix of these assets.
Because the industry is so digital asset intensive, A utility can quickly find itself in possession of hundreds, or even thousands, of digital twins each being fed data from just as many systems and IoT devices. The complex task of accurately informing a single digital twin will continue to be amplified by integrating multiple digital twins in a network. The effects of bad data on such a system can easily be staggering, says Laura Callaway in Transmission & Distribution World.
New architecture and desiloed data and logic
The root cause of bad data is often poor architectural design, designs that are provincial in nature, outdated, not anticipating todays demanding scale or data connectivity requirements. Its been what weve fought ever since raw compute, networking and storage improved and big data processing became affordable.
When we’re creating an innovative architecture that meets todays needs, ideally were providing the means to a highly capable end with the help of system-level design. In the process, ideally, were anticipating plug-and-play connections between many other systems.
Interaction logic is critical to connections between systems, and you can imagine that digital twins each constitute a system, and the interaction between systems harnesses the plug-and-play connections between them.
In order for these digital twin representations to interact, reusable descriptions of people, places, things and ideas, and their behaviors need to be created that are logically and linguistically consistent, as well as both human and machine-readable.
Knowledge graphs are ideal for this purpose. At the heart of knowledge graphs are contextualized, dynamic models that allow data enrichment and reuse in the form of knowledge graphs, graphs of instance data, rules and facts that can be easily interconnected and scaled.
These knowledge graphs can make interoperability between larger and larger systems possible. Think of it this way: more and more logic is ending up in knowledge graphs, where it can be reused for interoperability purposes. Once you’ve done the hard work of making the graph consistent, graphs and subgraphs can be snapped together, and you can create data contexts, rather than just data monoliths.
Disambiguation, abstraction and rule-based interaction logic can all go into a knowledge graph
Human language, whether that language involves words, numbers or mathematical expressions, expresses logical constructs that machines need to understand and use to help us discover, preserve, manage and further articulate context thats often missing from typical enterprise instance data in tabular datasets.
The more architects and modelers unleash and contextualize descriptive and rule-based logic trapped in applications can be made reusable and placing these in much more accessible knowledge graphs that also contain the relevant instance data, the more useful and potentially interactive digital twins can become.
If we’re going to build digital twins and create pieces of this metaverse, well need blended data and logic resources to be discoverable, reusable, accessible and dynamic, in addition to being powerful analytical resources for data scientists. Blue Brain Nexus, a shared, dynamic knowledge graph resource based in Switzerland for the Blue Brain Project (which seeks to reverse engineer the brain), has already this level of sharing possible. In fact, they’ve built a Github site for users not familiar with knowledge graph technology to build a little knowledge graph and query its JSON-LD that semantically links different contexts together: https://bluebrain.github.io/nexus-bbp-domains/docs/bbptutorial/gett…
The above tutorial is a good way to get started with the Nexus data modeling best practices described here:
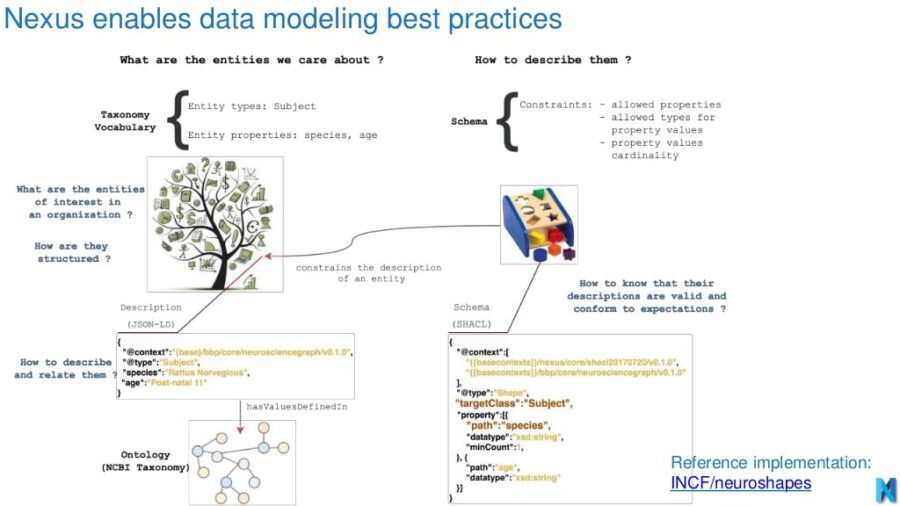
Bogdan Roman, “Blue Brain Nexus Technical Introduction”, slide deck, Slide 4, 2018, https://www.slideshare.net/BogdanRoman1/bluebrain-nexus-technical-i…
){kind=link}