
By Hui Li, Principal Staff Scientist, Data Science, at SAS.
A typical question asked by a beginner, when facing a wide variety of machine learning algorithms, is “which algorithm should I use?” The answer to the question varies depending on many factors, including:
- The size, quality, and nature of data.
- The available computational time.
- The urgency of the task.
- What you want to do with the data.
Even an experienced data scientist cannot tell which algorithm will perform the best before trying different algorithms. We are not advocating a one and done approach, but we do hope to provide some guidance on which algorithms to try first depending on some clear factors.
The machine learning algorithm cheat sheet
Click on the picture below to zoom in.
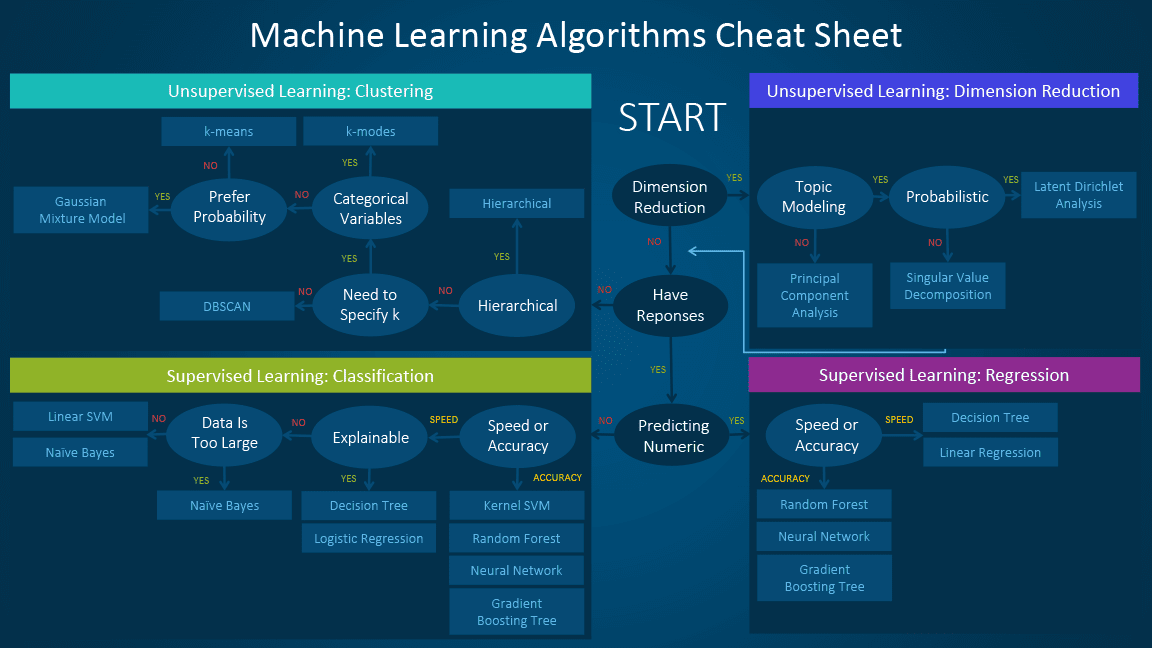
To read more, click here.
The article describes when using one of the following algorithms:
- Linear regression and Logistic regression
- Linear SVM and kernel SVM
- Trees and ensemble trees
- Neural networks and deep learning
- k-means/k-modes, GMM (Gaussian mixture model) clustering
- DBSCAN
- Hierarchical clustering
- PCA, SVD and LDA
DSC Resources
- Services: Hire a Data Scientist | Search DSC | Classifieds | Find a Job
- Contributors: Post a Blog | Ask a Question
- Follow us: @DataScienceCtrl | @AnalyticBridge
Popular Articles
{kind=link}