

In his book Outliers, Malcom Gladwell unveils the “10,000-Hour Rule” which postulates that the key to achieving world-class mastery of a skill is a matter of 10,000 hours of practice or learning. And while there may be disagreement on the actual number of hours (though I did hear my basketball coaches yell that at me about 10,000 times), lets say that we can accept that it requires roughly 10,000 hours of practice and learning exploring, trying, failing, learning, exploring again, trying again, failing again, learning again for one to master a skill.
If that is truly the case, then dang, us humans are doomed.
10,000 hours of learning is a rounding error for some of todays AI models. Think about 1,000,000 Tesla cars with its Fully Self Driving (FSD) autonomous driving module practicing and learning every hour that it is driving. In a single hour of the day, Teslas FSD driving module is learning 100x more than what Malcom Gladwell postulates is necessary to master a task. And over a year, the Tesla FSD module is going to have amassed 8.69 billion hours of learning 869,000 times more hours than Gladwell postulated was needed to master a skill!
AI models are the masters of learning. Or as Matthew Broderick yells at the WOPR AI war simulation module in the movie Wargames: Learn, goddamn it! (See Figure 1).

Figure 1: Learn, goddamn it!
AI models have numerous ways in which it can learn. Here are just a few of them:
Machine Learning learns by using algorithms to analyze and draw inferences from patterns in data, correlating patterns between inputs and outcomes. There are two categories of Machine Learning:
- Supervised Machine Learning uses labeled datasets (known outcomes) to train algorithms that can predict expected outcomes. As labeled input data is fed into the model, the model adjusts its weights across the model variables until the model has been fitted appropriately using an optimization routine to minimize the loss or error function. Regression modeling is a common Supervised Machine Learning algorithm.
- Unsupervised Machine Learning learns trends, patterns, and relationships from unlabeled data (unknown outcomes). Unsupervised Machine Learning algorithms discover trends, patterns, and relationships buried in the data. Clustering is a common Unsupervised Machine Learning algorithm.
Automated Machine Learning, or AutoML, eliminates the need for skilled data scientists to analyze and test the multitude of different machine learning algorithms by automagically applying all of them to a data set to see which ones are most effective. AutoML can also optimize the machine learning hyperparameters of the best models to train an even better model (see Figure 2).
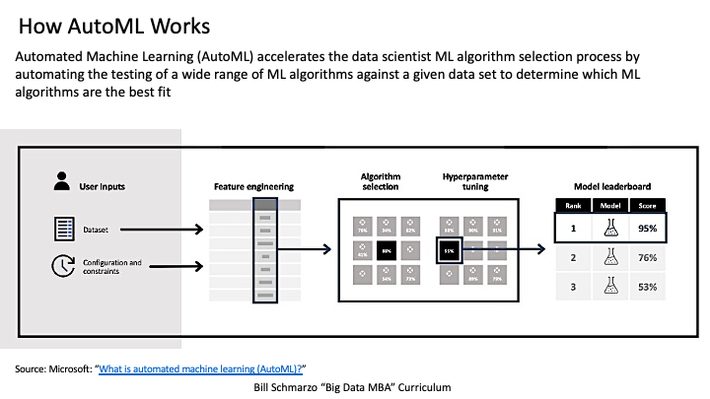
Figure 2: Source: Microsoft: What is automated machine learning (AutoML)?
Deep Learning uses neural networks to imitate the workings of the human brain in processing data and identifying patterns in unstructured data sets (audio, images, text, speech, video, waves). Deep learning learns to classify patterns and relationships using extremely large training data sets (Big Data) and a deep hierarchy of layers, with each layer solving different pieces of a complex problem.
Reinforcement Learning uses intelligent agents to take actions in a known environment to maximize cumulative reward. Reinforcement Learning learns by replaying a certain situation (a specific game, vacuuming the house, driving a car) millions or billions (using simulators) of times. The program is rewarded when it makes a good decision and given no reward (or punished) when it loses or makes a bad decision. This system of rewards and punishments strengthens the connections to eventually make the right moves without programmers explicitly programming the rules into the game.
Active Learning is a special type of machine learning algorithm that leverages human subject matter experts to assist in labeling the input data. Since the key to an effective machine learnings model is access to labeled data, Active Learning prioritizes the inputs that it cannot decipher so that human experts can help (see Figure 3).
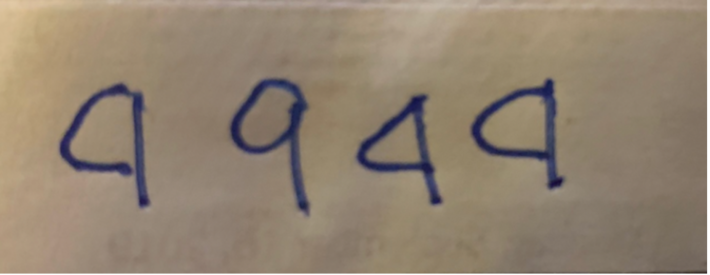
Figure 3: Human Subject Matter Expert to distinguish a 4 from a 9
Transfer Learning is a technique whereby a neural network is first trained on one type of problem and then the neural network model is reapplied to another, similar problem with only minimal training. Transfer learning re-applies the Neural Network knowledge (weights and biases) gained while solving one problem to a different but related problem with minimal re-training. For example, knowledge gained while learning to recognize cars could apply when trying to recognize trucks or tanks or trains.
Federated Learning trains an algorithm across multiple decentralized remote or edge devices using local data samples. All the training data remains on your remote device. Federated Learning works like this: the remote device downloads the current analytic model, improves it by learning from data on the remote or edge device, and then summarizes the changes as a small, focused update that is sent to the cloud where it is aggregated with other updates to improve the analytic model.
Meta-learning is teaching machines to learn how to learn by designing algorithmic models that can learn new skills or adapt to new environments without requiring massive test data sets. There are three common Meta-learning approaches: 1) learn an efficient distance metric (metric-based); 2) use a (recurrent) neural network with external or internal memory (model-based); 3) optimize the model parameters explicitly for fast learning (optimization-based)
Generative Adversarial Networks (GANs) are deep neural net architectures comprised of two neural nets a Generator and a Discriminator that are pitted one against the other to accelerate the training of the deep learning models. The Generator neural network manufactures new data based upon an understanding of the current data set, and the Discriminator neural network tries to discriminate real data from manufactured data. This accelerates the training of deep learning models by providing even more data against which to train the deep learning models.
Human versus Machine Learning Challenge Summary
Given how rapidly AI / ML models can learn (think accelerated learning that quickly builds upon itself with minimal human oversight that can quickly spiral out-of-control), the real AI challenge to humanity is this:
You give AI a goal and the way that AI achieves that goal turns out to be at odds with what you really intended
It can be dangerous when goals don’t align, and while every organization knows that’s a given, that misalignment of goals could become catastrophic when you engage an engine that is continuously learning and adapting a billion times faster speed than us humans.
So, are us humans really doomed? To learn more, youll have to wait for Part 2 of this series (and hint: Tom Hanks to the rescue!).
{kind=link}