
This article was posted on Intellipaat.
Hadoop is an open-source framework developed in Java, dedicated to store and analyze the large sets of unstructured data. It is a highly scalable platform which allows multiple concurrent tasks to run from single to thousands of servers without any delay.
It consists of a distributed file system that allows transferring data and files in split seconds between different nodes. Its ability to process efficiently even if a node fails makes it a reliable technology for companies which cannot afford to delay or stop their activities.
How did Hadoop evolve?
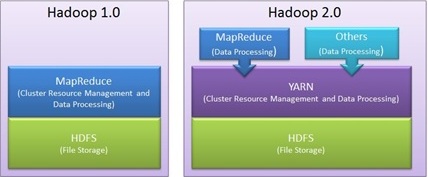
Inspired by Google’s MapReduce which splits an application into small fractions to run on different nodes, scientists Doug Cutting and Mike Cafarella created a platform called Hadoop 1.0 and launched it in the year 2006 to support distribution for Nutch search engine.
Hadoop was made available for public in November 2012 by Apache Software Foundation. Named after a yellow soft toy elephant of Doug Cutting’s kid, Hadoop has been continuously revised since its launch.
As part of its revision, it launched its second revised version Hadoop 2.3.0 on 20th Feb, 2014 with some major changes in the architecture.
What comprises of HADOOP architecture/Hadoop ecosystem?
The architecture/ecosystem of Hadoop can be broken down into two branches, i.e., core components and complementary/other components.
Core Components:
As per the latest version of Apache Hadoop framework, there are four basic or core components.

What you will find in the full article:
- Why should we use Hadoop?
- Scope of Hadoop
- Why do we need Hadoop?
- Who is the right audience to learn Hadoop?
- How Hadoop will help you in career growth?
To read the original article, click here.
Top DSC Resources
- Article: What is Data Science? 24 Fundamental Articles Answering This Question
- Article: Hitchhiker’s Guide to Data Science, Machine Learning, R, Python
- Tutorial: Data Science Cheat Sheet
- Tutorial: How to Become a Data Scientist – On Your Own
- Categories: Data Science – Machine Learning – AI – IoT – Deep Learning
- Tools: Hadoop – DataViZ – Python – R – SQL – Excel
- Techniques: Clustering – Regression – SVM – Neural Nets – Ensembles – Decision Trees
- Links: Cheat Sheets – Books – Events – Webinars – Tutorials – Training – News – Jobs
- Links: Announcements – Salary Surveys – Data Sets – Certification – RSS Feeds – About Us
- Newsletter: Sign-up – Past Editions – Members-Only Section – Content Search – For Bloggers
- DSC on: Ning – Twitter – LinkedIn – Facebook – GooglePlus
Follow us on Twitter: @DataScienceCtrl | @AnalyticBridge
{kind=link}