
Summary: Autonomous vehicles (AUVs) and many other systems that need to accurately perceive the world around them will be much better off when image classification moves from 2D to 3D. Here we examine the two leading approaches to 3D classification, Point Clouds and Voxel Grids.
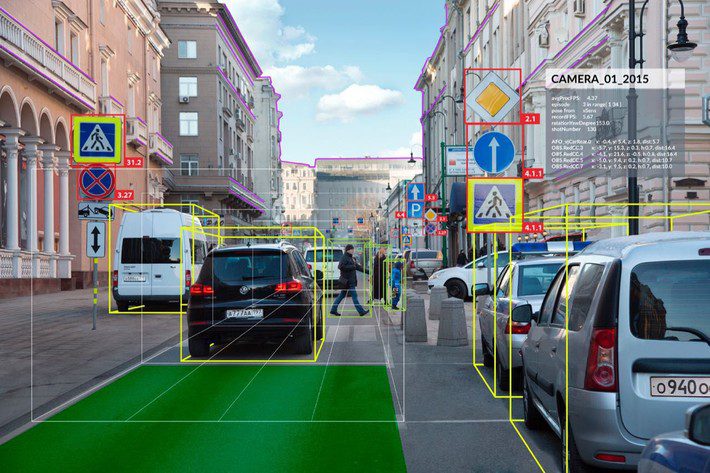 One of the well-known problems in CNN image classification is that because the CNN classifier sees only a 2D image of the object it won’t recognize that same object if it’s rotated. The solution thus far has been to train on many different orthogonal views of the same object and that vastly expands the problem of training data and training time.
One of the well-known problems in CNN image classification is that because the CNN classifier sees only a 2D image of the object it won’t recognize that same object if it’s rotated. The solution thus far has been to train on many different orthogonal views of the same object and that vastly expands the problem of training data and training time.
In the AUV world, simultaneous localization and mapping (SLAM) is the technical term for how the vehicle maintains awareness of its surroundings, both static (traffic lights) and moving (other cars and pedestrians). If the car could visualize itself in 3D space instead of a series of 2D snapshots then performance would be significantly better.
Sensors Already See in 3D
The two primary sensors on AUVs for this dynamic awareness are LIDARs and RGB-D cameras. RGB-D, also known a depth cameras capture not only the 2D RGB data but also depth based on ‘time of flight’, literally the time it takes the photons to reach the sensor. Not too many years ago this was enormously expensive and complex but sensor technology has made it reasonable to put these on lots of devices. Think Microsoft Kinect from 2010.
So by putting two RGB-D cameras on a car you have introduced stereoscopic vision and the ability to capture a full 3D dataset of all the objects surrounding the car.
But curiously, the 3D data from both LIDAR and RGB-D cameras has so far been analyzed only using our existing 2D CNN algorithms. Basically we’ve been throwing all that valuable 3D data away.
Storing the Data for Analysis
Deep learning is finally catching up with techniques for 3D CNNs. The techniques are relatively new but are rapidly approaching commercialization.
There are fundamentally two ways to store the 3D image data for 3D CNN image classification.
 Point Clouds (a) are simply collections of 3D points in space as might be collected from the rapidly rotating LIDAR beam on our AUV. They have an ‘xyz’ address in space and may also capture the ‘rgb’ data to better differentiate the object. This data is ‘per pixel’ converted to point clouds for processing.
Point Clouds (a) are simply collections of 3D points in space as might be collected from the rapidly rotating LIDAR beam on our AUV. They have an ‘xyz’ address in space and may also capture the ‘rgb’ data to better differentiate the object. This data is ‘per pixel’ converted to point clouds for processing.
Voxel grids (b) are 3D versions of pixels (a mash up of ‘volume’ and ‘pixel’). In our 2D CNN world we analyze only one ‘slice’ of pixels. In the Voxel world there are many different 2D slices that add up to the full 3D object. Resolution depends on the size of the pixel as well as the depth of the ‘slice’.
Point clouds can literally be an infinite number of points in space with coordinates that ‘float’ versus Voxel grids where each voxel has a discrete coordinate within a predefined space.
Point clouds are by definition unordered while Voxel grids are ordered data.
Both versions appear to have the same computational obstacle. Given the common 256 x 256 image size for 2D CNN classification, it would seem that taking a 3D layer would require 256^3 pixels and that would impose very high computational and memory costs. In fact, through experiment, 3D voxels of 32^3 or 64^3 yields accuracy similar to the larger 2D image. A 64^3 image has essentially the same requirement as a 512^2 image.
Performance Comparisons
Research is increasingly aided by a growing number of open source data bases for training. Notably:
- MODELNET10: 10 categories, 4,930 objects
- MODELNET40: 40 categories, 12,431 objects
- SHAPENET CORE V2: 55 categories, 51,191 objects.
The leading model packages so far are:
For Point-based: PointNet and PointNet++
For Voxel-base: Voxel ResNet and Voxel CNN
Although research continues along both fronts, a recent study published by Nvdia comparing traditional, point-based, and voxel-based systems shows the Voxel approach in the lead. 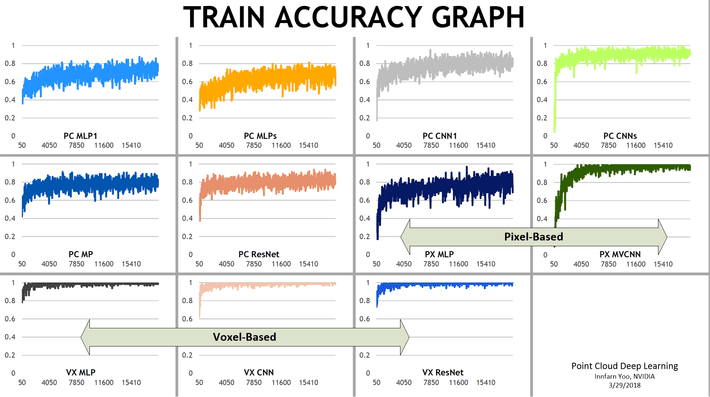
The Point cloud data could be used but the accuracy was lower and the computational cost higher than the Voxel approaches.
Voxelization converged faster making it preferable for real time object classification and in addition was more accurate.
For more background try these papers here and here or the original NVDIA study here.
Other articles by Bill Vorhies
About the author: Bill is Contributing Editor for Data Science Central. Bill is also President & Chief Data Scientist at Data-Magnum and has practiced as a data scientist since 2001. His articles have been read more than 2 million times.
He can be reached at:
{kind=link}