
This is our second post in this sub series “Machine Learning Types”. Our master series for this sub series is “Machine Learning Explained”.
Unsupervised Learning; is one of three types of machine learning i.e. Supervised Machine Learning, Unsupervised Machine Learning and Reinforcement Learning. This post is limited to Unsupervised Machine Learning to explorer its details.
Unsupervised Machine Learning
- A technique with the idea to explore hidden gems / patterns.
- To find some intrinsic structure in data.
- Something cant be seen with naked eye requires magnifier (UML)
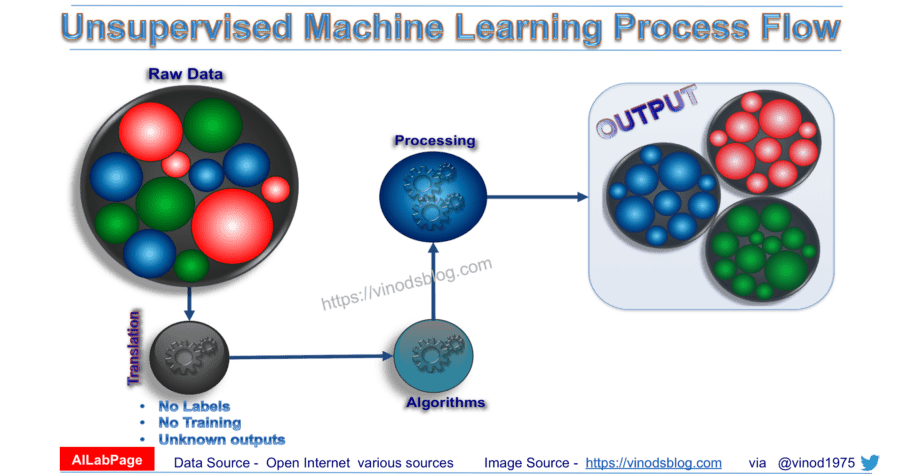
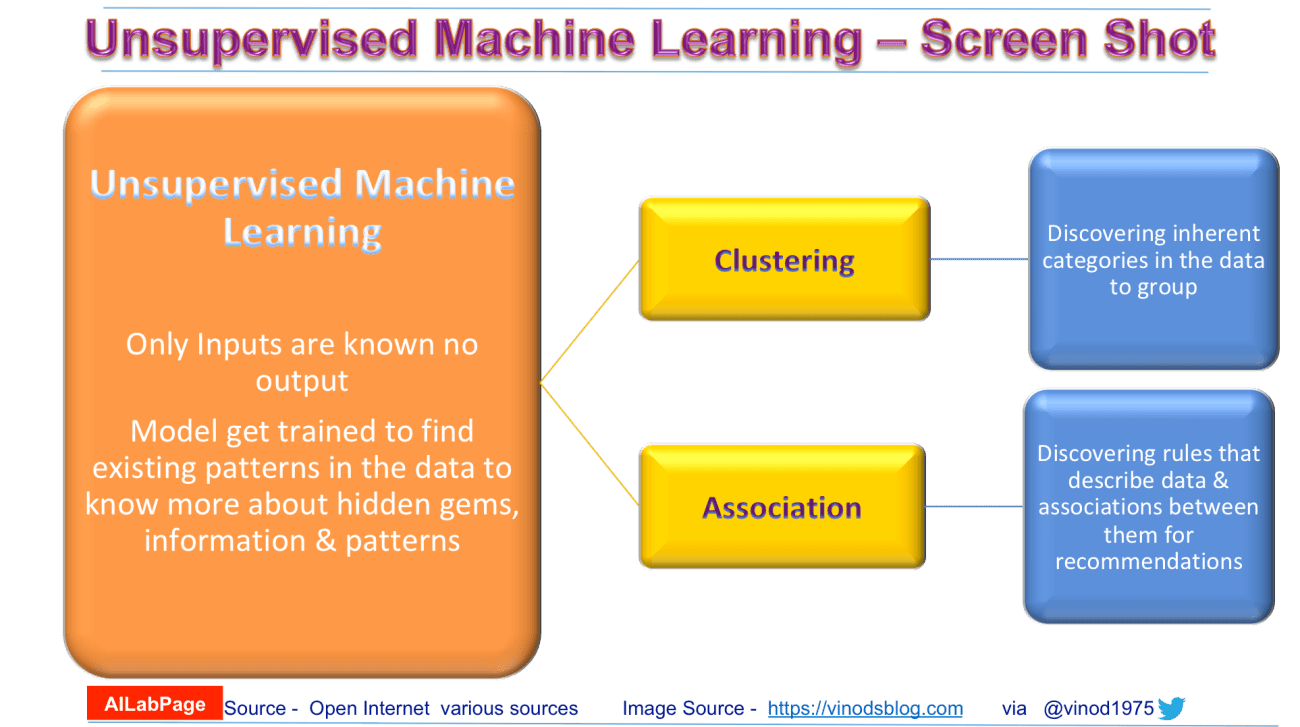
In Unsupervised Learning available data have no target attribute. Machine Learning Algorithm takes training examples as the set of attributes/features alone. The purpose of unsupervised learning is to attempt to find natural partitions in the training set. The most common unsupervised learning method is cluster analysis at the same time two general strategies in UML includes:
- Clustering – Partitions data into distinct clusters based on distance to the centroid of a cluster
- Hierarchical Clustering – Cluster tree is build with multilevel hierarchy of clusters. No assumptions on the number of clusters
- Agglomerative – In this technique its start with the points as individual clusters as it move forward; at each step, merge the closest pair of clusters until only one cluster left.
- Divisive – Here its start with one, all-inclusive cluster. At each step, split a cluster until each cluster contains a point.
System does self-discovery of patterns, regularities and features etc. from the input data and relations for the input data over output data. Discovering similarities and dissimilarities to forms clusters i.e. self-discovery is main target here. Since the examples given to the learner are unlabelled, there is no error or reward signal to evaluate a potential solution. This distinguishes unsupervised learning from supervised learning and reinforcement learning.
Unsupervised learning – Pros & Cons
Since no labels are given to the learning algorithm, leaving it on its own to find structure in its input. Unsupervised learning can be a challenging goal in itself. The training data consists of a set of input vectors x without any corresponding target values; hence known as learning / working without a supervisor.
- Pros
- It can detect what human eyes can not understand
- The potential of hidden patterns can be very powerful for the business or even detect extremely amazing facts, fraud detection etc.
- Output can determine the un explored territories and new ventures for businesses. Exploratory analytics can be applied to understand the financial, business and operational drivers behind what happened.
- Cons
- As seen in above explanation unsupervised learning is harder as compared to supervised learning.
- It can be a costly affair, as we might need external expert look at the results for some time.
- Usefulness of the results; are of any value or not is difficult to confirm since no answer labels are available.
Unsupervised Learning Categories
- Parametric Unsupervised Learning
- Non-parametric Unsupervised Learning
AILabPage’s – Machine Learning Series
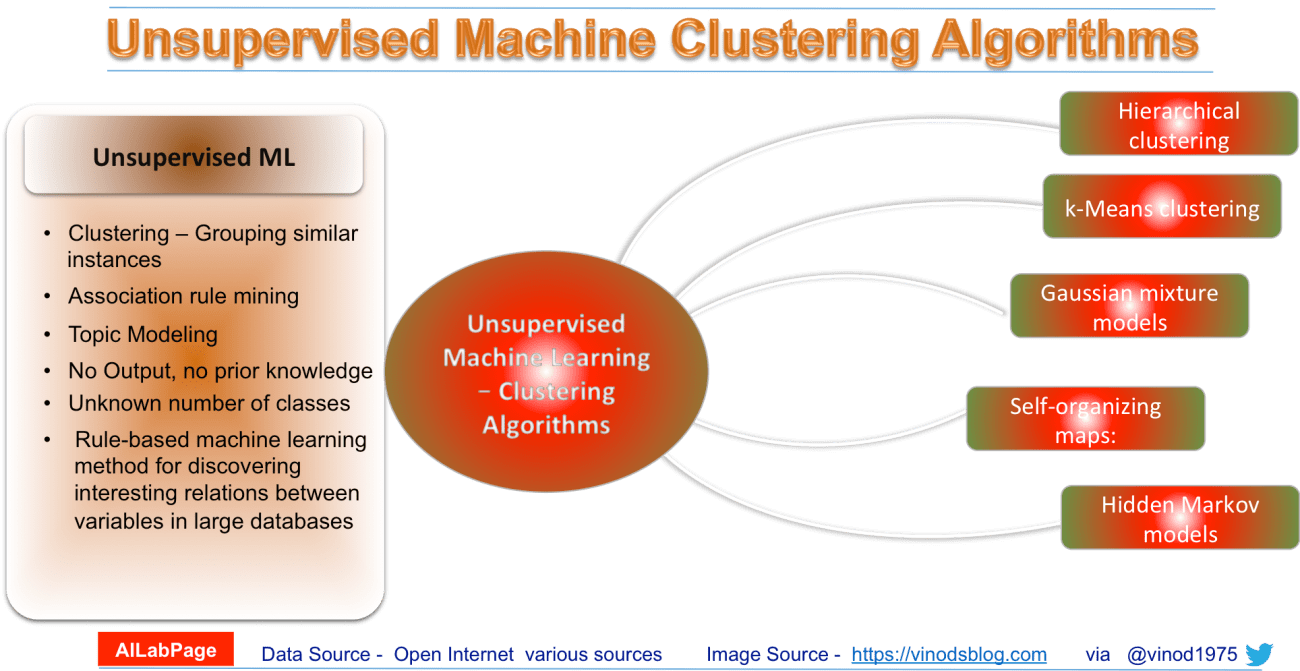
Frequently used algorithms in unsupervised machine learning
Common clustering algorithms include:
- Hierarchical clustering: In this technique the algorithm builds a multilevel hierarchy of clusters by creating a cluster tree
- k-Means clustering: Here data gets partitions into k distinct clusters based on distance to the centroid of a cluster
- Gaussian mixture models: Algorithms builds a model in which model clusters a mixture of multivariate normal density components
- Self-organizing maps: This one gets super simplified by using neural networks that learn the topology and distribution of the data
- Hidden Markov models: Simply uses observed data to recover the sequence of states
The number of cluster seekers can be chosen adaptively as a function of the distance between them and the sample variance of each cluster. The best use for unsupervised is around exploratory analytics to understand the financial, business and operational drivers behind what happened.
For original post, click here
============================ About the Author =======================
Read about Author at : About Me
Thank you all, for spending your time reading this post. Please share your feedback / comments / critics / agreements or disagreement. Remark for more details about posts, subjects and relevance please read the disclaimer.
FacebookPage ContactMe Twitter
{kind=link}
Though in parametric algorithms, despite having not required much data to train, it however does also cause overfitting. It is more common that parametric under fit and non-parametric overfit. Both types of algorithms can over and under fit data though.