
The diverse fields in which machine learning has proven its worth is nothing short of amazing. At the heart of machine learning are the various algorithms it employs to classify data and predict outcomes. This article highlights two greedy classifiers that, albeit simple, can be extremely powerful in their own right.
This article is an excerpt from the book Machine Learning with R, Third Edition, written by Brett Lantz. This book provides a hands-on, readable guide to applying machine learning to real-world problems. Whether you are an experience R user or new to the language, Brett Lantz teaches you everything you need to uncover key insights, make new predictions, and visualize your findings.
Machine learning, at its core, is concerned with transforming data into actionable knowledge. Use the powerful combination of machine learning and R to make complex decisions simple.
Decision trees and rule learners are known as greedy learners because they use data on a first-come, first-served basis. Both the divide and conquer heuristic used by decision trees and the separate and conquer heuristic used by rule learners attempt to make partitions one at a time, finding the most homogeneous partition first, followed by the next best, and so on, until all examples have been classified.
The downside to the greedy approach is that greedy algorithms are not guaranteed to generate the optimal, most accurate, or smallest number of rules for a particular dataset. By taking the low-hanging fruit early, a greedy learner may quickly find a single rule that is accurate for one subset of data; however, in doing so, the learner may miss the opportunity to develop a more nuanced set of rules with better overall accuracy on the entire set of data. However, without using the greedy approach to rule learning, it is likely that for all but the smallest of datasets, rule learning would be computationally infeasible.

Figure 1: Both decision trees and classification rule learners are greedy algorithms
Though both trees and rules employ greedy learning heuristics, there are subtle differences in how they build rules. Perhaps the best way to distinguish them is to note that once divide and conquer splits on a feature, the partitions created by the split may not be re-conquered, only further subdivided. In this way, a tree is permanently limited by its history of past decisions. In contrast, once separate and conquer finds a rule, any examples not covered by all of the rule’s conditions may be re-conquered.
To illustrate this contrast, consider a case in which you are tasked with creating rules to identify whether or not an animal is a mammal. You could depict the set of all animals as a large space.
The rule learner identified three rules that perfectly classify the example animals:
- Animals that walk on land and have tails are mammals (bears, cats, dogs, elephants, pigs, rabbits, rats, and rhinos)
- If the animal does not have fur, it is not a mammal (birds, eels, fish, frogs, insects, and sharks)
- Otherwise, the animal is a mammal (bats)
In contrast, a decision tree built on the same data might have come up with four rules to achieve the same perfect classification:
- If an animal walks on land and has a tail, then it is a mammal (bears, cats, dogs, elephants, pigs, rabbits, rats, and rhinos)
- If an animal walks on land and does not have a tail, then it is not a mammal (frogs)
- If the animal does not walk on land and has fur, then it is a mammal (bats)
- If the animal does not walk on land and does not have fur, then it is not a mammal (birds, insects, sharks, fish, and eels)
The different result across these two approaches has to do with what happens to the frogs after they are separated by the “walk on land” decision. Where the rule learner allows frogs to be re-conquered by the “do not have fur” decision, the decision tree cannot modify the existing partitions and therefore must place the frog into its own rule.
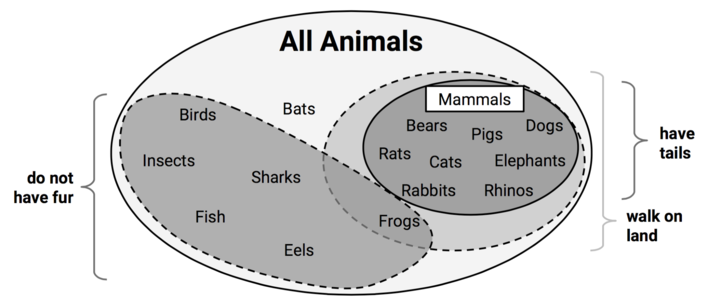
Figure 2: The handling of frogs distinguishes divide and the conquer and separate and conquer heuristics.
The latter approach allows the frogs to be re-conquered by later rules. On the one hand, because rule learners can reexamine cases that were considered but ultimately not covered as part of prior rules, rule learners often find a more parsimonious set of rules than those generated from decision trees. On the other hand, this reuse of data means that the computational cost of rule learners may be somewhat higher than for decision trees.
In this article, we looked at how trees and rules “greedily” partition data into interesting segments. A simple example was shown to demonstrate the subtle differences between how how rule learners and decision trees classify data. While the greedy approach may not produce the most nuanced and overall accurate results, it’s substantially lower computational cost makes it an extremely viable candidate for large datasets.
If you liked this article, then you’ll most certainly like Machine Learning with R, Third Edition. R, if you’re unaware of it, has quickly become an indispensable tool in a data scientist’s kit due to the ease of use and convenience it provides through it’s packages.The book covers a lot of ground in machine learning, while keeping the information approachable even for beginners.
About the author
Brett Lantz is a DataCamp instructor and a frequent speaker at machine learning conferences and workshops around the world. A sociologist by training, Brett was first captivated by machine learning during research on a large database of social network profiles.
{kind=link}