
We’ve all experienced the great data rush as companies push to use analytics to drive business decisions. After all, the proliferation of data and its intelligent analysis can change entire company trajectories. But to make the quintillions of data created each day truly useful, as well as all that has come before, it must be understandable to an artificial intelligence (AI) system.
Dealing with numbers is one thing, but human language is something else entirely. Making texts, comments, forum posts, tweets, web pages, blog posts, reviews and books digestible to a system that cannot draw on context is a whole other matter. There are many techniques that address this problem, but they usually generate very large data tables. Word2Vec, however, is a technique that offers a compact representation of a word and its context. Let’s take a look.
Developing the Tools to Understand Text
Taking a step back, word embedding, like document embedding, belongs to the text preprocessing phase — specifically the part that transforms text into a row of numbers. It is used to map meanings and help compare word similarity through vectors. It is most frequently done based on the presence or absence of a certain word in the original text. This is a simple method referred to as one-hot encoding. The process essentially converts categorical variables into numbers or symbols that could be used to help machine learning algorithms better predict.
There are two big problems with one-hot encoding, however. First, it produces a very large data table with the possibility of a large number of columns. Additionally, one-hot encoding produces a sparse data table with a high number of 0s. This can be problematic for training certain machine learning algorithms.
To address these issues, the Word2Vec technique has been proposed. Its aim is to reduce the size of the word embedding space and compress the most informative description for each word with the word representation; interpretability of the embedding space becomes secondary.
Word2Vec in Action
The best way to understand Word2Vec is through an example, but before diving in, it is important to note that the Word2Vec technique is based on a feed-forward, fully connected architecture. Now, for a simple illustration.
Looking at a basic sentence like “The sneaky white cat jumped over the sleeping dog,” consider the context word by word. “Cat” is surrounded by several other words that provide its context. If you use a forward context (the most common) of size 3, then the word “cat” depends on the context “the sneaky white.” The word “jumped” relies on “sneaky white cat,” and so on.
Alternatively, you could use a backward context of size 3. In this case, the word “cat” depends on the context “jumped over the,” while “jumped” is tied to “over the sleeping.” You could also try a central context of size 3, in which the context for “cat” is “sneaky white jumped,” while the “jumped” context is “white cat over” — you get the idea.
When given a context and word related to that context, two possible tasks exist. From the context, you can predict the target word, which is considered a continuous bag-of-words (CBOW) approach. You can also predict the context it came from using the skip-gram approach.
What It Looks Like
Again, in an attempt to keep it simple, let’s select a context size of C=1. If we use a fully connected neural network with one hidden layer, we end up with an architecture like this for both CBOW and skip-gram:
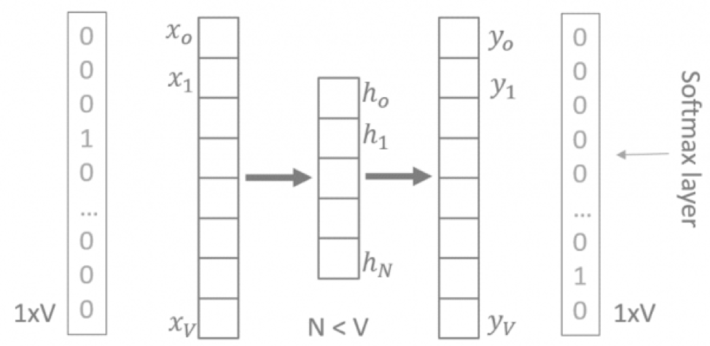
V-N-V neural architecture to predict a target word from a one-word context (CBOW) or a one-word context from a target word (skip-gram). Softmax activation functions in the output layer guarantee a probability compatible representation. Linear activation functions for the hidden neurons simplify the training computations.
Here, the input and output patterns are one-hot encoded vectors with dimension 1xV, where V is the vocabulary size. Using the CBOW strategy, the one-hot encoded context word feeds the input, and the one-hot encoded target word is predicted at the output layer. For skip-gram, the one-hot encoded target word feeds the input, while the output layer tries to reproduce the one-hot encoded one-word context. The number of hidden neurons is N, with N < V.
To guarantee a probability-based representation of the output word, a softmax activation function is used in the output layer, and the following error function Eis adopted during training:
![]()
where wois the output word andwiis theinput word. To reduce computational effort, a linear activation function is used for the hidden neurons, and the same weights are used to embed all inputs (CBOW) or all outputs (skip-gram).
Now, looking at the figure, notice that the input and output layers have both dimension 1xV, where V is the vocabulary size, since they both represent the one-hot encoding of a word. Additionally, the hidden layer has less units (N) than the input layer (V). So, if we represent the input word with the hidden neuron outputs rather than with the original one-hot encoding, we reduce the size of the word vector and hopefully maintain enough of the original information. The hidden neuron outputs provide the word embedding. This word representation, being much more compact than one-hot encoding, produces a much less sparse representation of the document space.
If we expand from this basic example, the network structure changes slightly with a bigger context. The word representation dimensionality still gets reduced, and the document space gets a more compact representation, which helps with upcoming machine learning algorithms — especially on large data sets and large vocabularies.
It is worth noting that as vocabulary sets become quite big, many words are used only a few times. To determine which to keep, you can execute a survival function that utilizes the word frequency and sampling rate. Typically, the smaller the sampling rate, the less likely the word will be kept. This survival function is most commonly used together with a hard-coded threshold to remove very infrequent words.
Getting Practical
As word embedding becomes common practice, solutions are emerging to help train neural networks with Word2Vec to implement a CBOW or skip-gram approach. Workflows can now run the network on all vocabulary words learned during training and output their embedding vectors.
The whole intuition behind the Word2Vec approach consists of projecting the word representation, including its context, on the space created by the hidden layer of a neural network with smaller dimensionality than the original one-hot encoding space. This means that words appearing in similar contexts will be similarly embedded, including synonyms, opposites and semantically equivalent concepts. It is not a flawless technique and is still an active research area. But, the importance of word embedding cannot be denied. Word2Vec is evolving and capable of handling increasingly complex word representations. As data scientists continue to test, refine and train the architecture, word embedding will improve, which will make word representation all the more accurate, compact and valuable.
To learn more, please see these three independent resources:
- Le Q., Mikolov T. (2014) “Distributed Representations of Sentences and Documents,” Proceedings of the 31stInternational Conference on Machine Learning, Beijing, China, 2014. JMLR: W&CP volume 32
- Analytics Vidhya (2017) “An Intuitive Understanding of Word Embeddings: From Count Vectors t…”
- McCormick, C. (2016 April 19) “Word2Vec Tutorial – The Skip-Gram Model”
{kind=link}