
 In our previous articles, we have discussed the top Python libraries for data science. This time we will focus on Scala, which has recently become another prominent language for data scientists. It has gained popularity mostly due to the rise of Spark, a big data processing engine of choice, which is written in Scala and thus provides native API in Scala.
In our previous articles, we have discussed the top Python libraries for data science. This time we will focus on Scala, which has recently become another prominent language for data scientists. It has gained popularity mostly due to the rise of Spark, a big data processing engine of choice, which is written in Scala and thus provides native API in Scala.
We will not go into an in-depth comparison of Scala vs. Python here, but it’s important to note, that, unlike Python, Scala is a compiled language. Hence the code written in it gets executed much faster (comparing to pure Python, and not specialized libraries like NumPy).
In contrast to Java, writing in Scala is much more enjoyable, since the same logic can usually be expressed with the significantly smaller number of lines. Scala’s functionality is in no way inferior to that of Java and even has some properties that are more advanced. Java-old-timers could provide a lot of counter-arguments here, but there is no doubt that Scala is much better suited for data science tasks.
Currently, Python and R remain the leading languages for rapid data analysis, as well as building, exploring, and manipulating powerful models, while Scala is becoming the key language in the development of functional products that work with big data, as the latter need stability, flexibility, high speed, scalability, etc. Often, in a research phase, analysis and models are done in Python and then implemented in Scala during production.
For your convenience, we have prepared a comprehensive overview of the most important libraries used to perform machine learning and Data Science tasks in Scala. We will use analogies with the corresponding Python tools for better understanding of some important aspects. In fact, there is just one top-level comprehensive tool that forms the basis for the development of data science and big data solutions in Scala, known as Apache Spark, that is supplemented by a wide range of libraries and instruments written in both Scala and Java. Let’s take a closer look at it.
Data analysis and math
1. Breeze (Commits: 3316, Contributors: 84)
Breeze is known as the primary scientific computing library for Scala. It scoops up ideas from MATLAB’s data structures and the NumPy classes for Python. Breeze provides fast and efficient manipulations with data arrays, and enables the implementation of many other operations, including the following:
-
Matrix and vector operations for creating, transposing, filling with numbers, conducting element-wise operations, inversion, calculating determinants, and much more other options to meet almost every need.
-
Probability and statistic functions, that vary from statistical distributions and calculating descriptive statistics (such as mean, variance and standard deviation) to Markov chain models. The primary packages for statistics are
breeze.statsandbreeze.stats.distributions -
Optimization, which implies investigation of the function for a local or global minimum. Optimization methods are stored in the
breeze.optimize package. -
Linear algebra: all basic operations rely on the netlib-java library, making Breeze extremely fast for algebraic computations.
-
Signal processing operations, necessary for work with digital signals. The examples of important operations in Breeze are convolution and Fourier transformation, which decomposes the given function into a sum of sine and cosine components.
Breeze also provides plotting possibilities which we will discuss below.
2. Saddle (Commits: 184, Contributors: 10)
Another data manipulation toolkit for Scala is Saddle. It is a Scala analog of R and Python’s pandas library. Like the dataframes in pandas or R, Saddle is based on the Frame structure (2D indexed matrix).
In total, there are five major data structures, namely:
-
Vec (1D vector)

-
Mat (2D matrix)
-
Series (1D indexed matrix)
-
Frame (2D indexed matrix)
-
Index (hashmap-like)
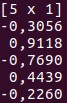
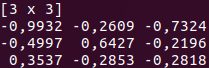
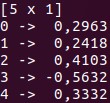
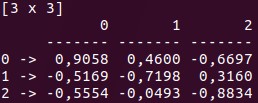
The Vec and Mat classes are at the base of Series and Frame. You can implement different manipulations on these data structures, and use them for basic data analysis. Another great thing about Saddle is its robustness to missing values. /span>
3. Scalalab (Commits: 23, Contributors: 1)
ScalaLab is a Scala’s interpretation of MATLAB computing functionality. Moreover, ScalaLab can directly call and access the results of MATLAB scripts.
The main difference from the previous computation libraries is that ScalaLab uses its own domain-specific language called ScalaSci. Conveniently, Scalalab gets access to the variety of scientific Java and Scala libraries, so you can easily import your data and then use different methods to make manipulations and computations. Most of the techniques are similar to Breeze and Saddle. In addition, as in Breeze, there are plotting opportunities which allow further interpretation of the resulting data.
NLP
4. Epic (Commits: 1790, Contributors: 15) & 5. Puck (Commits: 536, Contributors: 1)
Scala has some great natural language processing libraries as a part of ScalaNLP, including Epic and Puck. These libraries are mostly used as text parsers, with Puck being more convenient if you need to parse thousands of sentences due to its high-speed and GPU usage. Also, Epic is known as a prediction framework which employs structured prediction for building complex systems.
Visualization
6. Breeze-viz (Commits: 29, Contributors: 3)
As the name suggests, Breeze-viz is the plotting library developed by Breeze for Scala. It is based on the prominent Java charting library JFreeChart and has a MATLAB-like syntax. Although Breeze-viz has much fewer opportunities than MATLAB, matplotlib in Python, or R, it is still very helpful in the process of developing and establishing new models.
7. Vegas (Commits: 210, Contributors: 14)
Another Scala lib for data visualization is Vegas. It is much more functional than Breeze-viz and allows to make some plotting specifications such as filtering, transformations, and aggregations. It is similar in structure to Python’s Bokeh and Plotly.
Vegas provides declarative visualization that allows you to focus mainly on specifying what needs to be done with the data and conducting further analysis of the visualizations, without having to worry about the code implementation.
Machine Learning
8. Smile (Commits: 1019, Contributors: 21)
Statistical Machine Intelligence and Learning Engine, or shortly Smile, is a promising modern machine learning system in some ways similar to Python’s scikit-learn. It is developed in Java and offers an API for Scala too. The library will amaze you with fast and extensive applications, efficient memory usage and a large set of machine learning algorithms for Classification, Regression, Nearest Neighbor Search, Feature Selection, etc.
9. Apache Spark MLlib & ML
Built on top of Spark, MLlib library provides a vast variety of machine learning algorithms. Being written in Scala, it also provides highly functional API for Java, Python, and R, but opportunities for Scala are more flexible. The library consists of two separate packages: MLlib and ML. Let’s look at them in more detail one by one.
-
MLlib is an RDD-based library that contains core machine learning algorithms for classification, clustering, unsupervised learning techniques supported by tools for implementing basic statistics such as correlations, hypothesis testing, and random data generation.
-
ML is a newer library which, unlike MLlib, operates on data frames and datasets. The main purpose of the library is to give the ability to construct pipelines of different transformations on your data. The pipeline can be considered as a sequence of stages, where each stage is either a Transformer, that transforms one data frame into another data frame or an Estimator, an algorithm that can fit on a data frame to produce a Transformer.
Each package has its pros and cons and, in practice, it often proves more effective to apply both.
10. DeepLearning.scala (Commits: 1647, Contributors: 14)
DeepLearning.scala is an alternative machine learning toolkit that provides efficient solutions for deep learning. It utilizes mathematical formulas to create complex dynamic neural networks through a combination of object-oriented and functional programming. The library uses a wide range of types, as well as applicative type classes. The latter allows commencing multiple calculations simultaneously, which we consider crucial to have in a data scientist’s disposal. It’s worth mentioning that the library’s neural networks are programs and support all of Scala features.
11. Summing Bird (Commits: 1772, Contributors: 31)
Summingbird is a domain-specific data processing framework which allows integration of batch and online MapReduce computations as well as the hybrid batch/online processing mode. The main catalyzer for designing the language came from Twitter developers who were often dealing with writing the same code twice: first for batch processing, then once more for online processing.
Summingbird consumes and generates two types of data: streams (infinite sequences of tuples), and snapshots regarded as the complete state of a dataset at some point in time. Finally, Summingbird provides platform implementations for Storm, Scalding, and an in-memory execution engine for testing purposes.
12. PredictionIO (Commits: 4343, Contributors: 125)
Of course, we can not ignore a machine learning server for constructing and deploying predictive engines called PredictionIO. It is built on Apache Spark, MLlib, and HBase and was even ranked on Github as the most popular Apache Spark-based machine learning product. It enables you to easily and efficiently build, evaluate and deploy engines, implement your own machine learning models, and incorporate them into your engine.
Additional
13. Akka (Commits: 21430, Contributors: 467)
Developed by the Scala’s creator company, Akka is a concurrent framework for building distributed applications on a JVM. It uses an actor-based model, where an actor represents an object that receives messages and takes appropriate actions. Akka replaces the functionality of the Actor class that was available in the previous Scala versions.
The main difference, also considered as the most significant improvement, is the additional layer between the actors and the underlying system which only requires the actors to process messages, while the framework handles all other complications. All actors are hierarchically arranged, thus creating an Actor System which helps actors to interact with each other more efficiently and solve complex problems by dividing them into smaller tasks.
14. Spray (Commits: 2663, Contributors: 74)
Now let’s take a look at Spray – a suite of Scala libraries for constructing REST/HTTP web services built on top of Akka. It assures asynchronous, non-blocking actor-based high-performance request processing, while the internal Scala DSL provides a defining web service behavior, as well as efficient and convenient testing capabilities.
UPD: Spray is no longer maintained and has been suspended by Akka HTTP. While most of the library functionality remains, there were some changes and improvements in streaming, module structure, routing DSL, etc. connected to this displacement. The Migration Guide will help you find out about all of the developments.
15. Slick (Commits: 1940, Contributors: 92)
Last but not least on our list is Slick, which stands for Scala Language-Integrated Connection Kit. It is a library for creating and executing database queries that offer a variety of supported databases such as H2, MySQL, PostgreSQL, etc. Some databases are available via slick-extensions.
To build queries, Slick provides a powerful DSL, which makes the code look as if you were using the Scala collections. Slick supports both simple SQL queries, and strongly-typed joins of several tables. Moreover, simple subqueries can be used to construct more complex ones.
Conclusion
In this article, we have outlined some of the Scala libraries that can be very useful while performing major data scientific tasks. They have proved to be highly helpful and effective for achieving the best results. You can also view the activity statistics taken from GitHub on every provided library below.
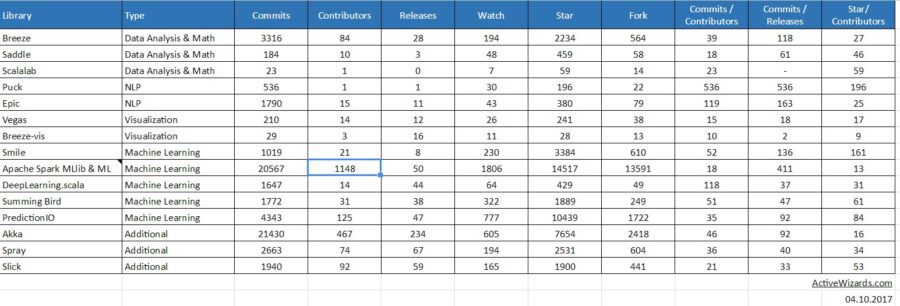
Source: Google Spreadsheet
Please note, that the list mentioned above is not comprehensive, and a lot of other tools suitable for different use cases are available on the market. If you have some positive experience with any other useful Scala libraries or frameworks that are worth adding to this list, please feel free to share them in the comment section below.
Thank you very much for your attention and cooperation!
{kind=link}