
The use of training, validation and test datasets is common but not easily understood.
In this post, I attempt to clarify this concept. The post is part of my forthcoming book on learning Artificial Intelligence, Machine Learning and Deep Learning based on high school maths. If you want to know more about the book, please follow me on Linkedin Ajit Jaokar
Background
Jason Brownlee provides a good explanation on the three-way data splits (training, test and validation)
– Training set: A set of examples used for learning, that is to fit the parameters of the classifier.
– Validation set: A set of examples used to tune the parameters of a classifier, for example to choose the number of hidden units in a neural network.
– Test set: A set of examples used only to assess the performance of a fully-specified classifier.
And then comes up with an important statement: Reference to a “validation dataset” disappears if the practitioner is choosing to tune model hyperparameters using k-fold cross-validation with the training dataset.
So, here, I try and explain these ideas in more detail from the source by Ricardo Gutierrez-Osuna Wright State University
Understanding model validation
Validation techniques are motivated by two fundamental problems in pattern recognition: model selection and performance estimation
Model selection: involves selecting optimal parameters or a model. Pattern recognition techniques have one or more free parameters – for example – the number of neighbours in a kNN classification and the network size, learning parameters and weights in MLPs. The selection of these hyperparameters determines the efficiency of the solution. Hyperparameters are set by the user. In contrast, the parameters of a model are learned from the data.
Performance estimation: Once we have chosen a model, we need to estimate its performance. If we had access to an unlimited set of samples (or the whole population) – it is easy to estimate the performance. However, in practise, we have access to a smaller sample of the population. If we use the entire dataset to train the model, the model is likely to overfit. Overfitting is essentially ‘learning the noise’ from the training data. Since our goal is to find the best model that can give optimal results on unseen data, overfitting is not a good option. We can address this problem by evaluating the error function using data which is independent of that used for training.
The first approach is to split the model into training and test dataset. This is the holdout method where you use the training dataset to train the classifier and the test dataset to estimate the error of the trained classifier. The holdout method has limitations: for example, it is not suitable for sparse datasets The limitations of the holdout can be overcome with a family of resampling methods such as Cross Validation.
Finally, the test dataset is a dataset used to provide an unbiased evaluation of a final model fit on the training dataset. The test dataset is used to obtain the performance characteristics such as accuracy, sensitivity, specificity, F-measure, and so on.
Putting it all together
The overall steps are:
- Divide the available data into training, validation and test set
- Select architecture and training parameters
- Train the model using the training set
- Evaluate the model using the validation set
- Repeat steps 2 through 4 using different architectures and training parameters
- Select the best model and train it using data from the training and validation set
- Assess this final model using the test set 1.
- This outline assumes a holdout method g If CV or Bootstrap are used, steps 3 and 4 have to be repeated for each of the K folds
- Steps 2 3 4 are part of hyperparameter tuning
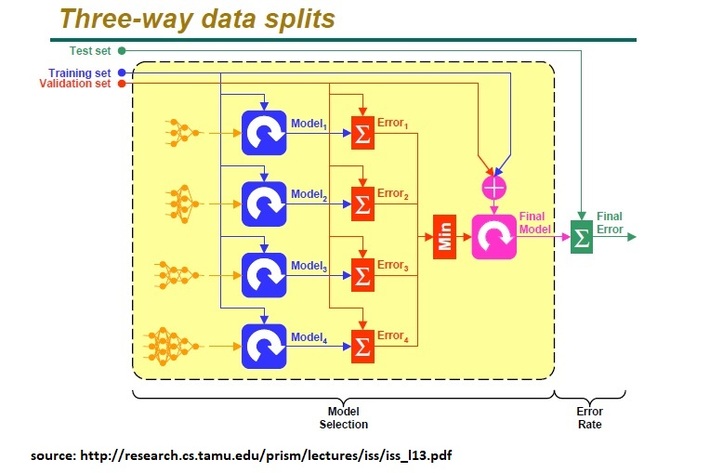
source for image and steps – source by Ricardo Gutierrez-Osuna Wright State University
I hope you found this useful. The post is part of my forthcoming book on learning Artificial Intelligence, Machine Learning and Deep Learning based on high school maths. If you want to know more about the book, please follow me on Linkedin Ajit Jaokar
%20for%20model%20selection%20and%20performance%20estimation){kind=link}