
Summary: Computational Synthetic Biology (CSB) is likely to be both the next big thing and perhaps most important field to exploit data science. As the name implies, this lies at the intersection of data science and biological research. Big advancements and big investments are already starting to occur here. Data scientists with deep learning skills will want to check this out.
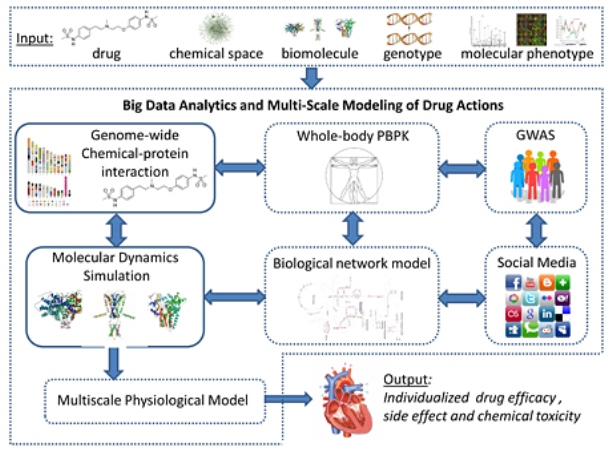 And the next big thing in data science is (wait for it) – biology! Actually Computational Synthetic Biology (CSB) sometimes referred to as ‘computational systems biology’ or simply ‘synthetic biology’.
And the next big thing in data science is (wait for it) – biology! Actually Computational Synthetic Biology (CSB) sometimes referred to as ‘computational systems biology’ or simply ‘synthetic biology’.
From the biological researcher’s perspective CSB broadly refers to the design and fabrication of biological components and systems that don’t already exist in the natural world or to the redesign and fabrication of existing biological system.
To the data scientist and particularly the start-up world CSB is a newly emerging field that will capitalize on advances in deep learning.
Depending on your personal sense of priority, CSB will remarkably accelerate cures to some of mankind’s most intractable diseases or be the foundation for the next generation of unicorns in the time frame of 5 to 7 years.
Perhaps the better way to frame this is which would you rather be working on, facial recognition to label your friends faces in Facebook, creating chatbots for that travel platform, or working to cure cancer and extend quality human lifetimes.
Isn’t This Just Bioinformatics?
Like most important innovations CSB wasn’t born yesterday. The discovery and use of restriction enzymes in 1978 is sometimes cited as the first use of engineering concepts in biology.
Just as deep learning has had to wait for MPP and the use of GPUs to sufficiently accelerate compute, CSB remained mostly a concept through the decoding of the human genome in 2003 followed by the explosion of genomic data in the ensuing 15 years.
Early bioinformatics attempted to solve problems appropriate for the beginning stages of our understanding of genomics. For example how to assemble a full genome model or mark specific areas of DNA using SNPs (single nucleotide polymorphism) of which there are about 10 million in the human genome.
CSB is Not Bioinformatics Business as Usual.
 Starting with the explosion in deep learning capabilities just two or three years ago, the first visionary biologist/data scientist teams began to explore how to exploit these new synergies in seemingly unrelated disciplines.
Starting with the explosion in deep learning capabilities just two or three years ago, the first visionary biologist/data scientist teams began to explore how to exploit these new synergies in seemingly unrelated disciplines.
To give you a sense of how new and wide open this field is, the website Angel.co which tracks the formation and investment in startups lists a little over 4 Million startups, the great majority of which are related to tech. A little over 5,000 are targeting ‘Big Data’ and another 5,000 are categorized as ‘Analytics’. Only 222 are identified as bioinformatics and only a portion of these are pursuing CSB.
This feels like the age of deep learning in about 2010, still three years out from having image classification or speech recognition hit the 95% accuracy rate that ushered in 10,000 new AI startups and applications.
Some Examples
Needless to say, in materials published so far the innovators in this field have been shy about saying much about their proprietary algorithms other than that are based on deep learning. Here are a few snapshots of what’s underway.
Hexagon Bio: Some three-quarters of antibiotics and half of anticancer compounds, including penicillin and statins came from naturally occurring fungi (you know, mushrooms and molds). But discovery of new compounds has been largely haphazard and based on researcher’s intuition.
Hexagon mines the fungal genome of over 2,000 species of mushrooms and molds to predict which gene clusters are most likely to produce useful compounds. They then fit their test microorganisms with custom-printed DNA parts to produce likely compounds that might, for example, attack cancer cells. They currently have roughly 22 compounds that show clinical promise.
In addition to their proprietary algorithms Hexagon has moved to utilize the most efficient tools of the trade like DNA sequencing and automated workstations. It’s also using a technology making it much faster to synthesize DNA by essentially downloading and printing copies of gene clusters. These can be used to redesign a yeast with the press of a button.
In the last 18 months they’ve raised $8 Million from private investors.
The fungal drug discovery field is particularly hot with competitors differentiating on how quickly and accurately their algorithms can spot potentially useful sections of DNA. Others playing in this field include:
LifeMine Therapeutics: A startup co-founded by Harvard University chemical biologist landed a $55 million Series A round from a large group of investors including WuXi Healthcare Ventures, Google and Merck’s venture arm.
Lodo Therapeutics Corp. signed a genome-mining deal with a unit of Roche for $969 million in May.
Adapsyn Bioscience Inc. received $162 Million from Pfizer in January for microbe mining.
Not All CSB Involves Wet Lab Work
BenevolentAI is pursuing the discovery of new solutions to the diseases of inflammation, neurodegeneration, orphan diseases, and rare cancers. As a group these don’t offer the blockbuster market size necessary to attract research dollars from the major pharma companies. BenevolentAI believes the answers to many of these may already exist in the untapped research created by pharma R&D organization.
Their approach is to develop an advanced artificial intelligence platform which they label a deep judgement system. This platform, a kind of advanced Watson QAM, learns and reasons from the interaction between human judgement and data.
Using vast amounts of unstructured data in scientific papers, patents, clinical trial information and from a large number of structured data sets the platform attempts to identify previously hidden scientific knowledge and deduces what ‘should’ be known based on what ‘is’ already known.
Generative Models May Be the Cutting Edge
Harvard chemistry professor Alan Aspuru-Guzik has harnessed generative DNN architecture to suggest molecular architectures that might replicate the combined properties of two different drugs, for example aspirin with ibuprofen. Combinations of effective drugs and combinations of effective protocols would greatly accelerate our ability to cure more diseases effectively and cost efficiently.
We more often think of using generative DNNs (RNNs, LSTMs) in applications like Google’s Smart Reply feature that suggests responses to emails. But use potential molecular architectures as the input and the AI is able to suggest potential combinations that would both physically fit together and potentially have the combined therapeutic effect.
In December 2017 Aspuru-Guzik and colleagues at Harvard, the University of Toronto, and Cambridge published promising results of the generative model trained on 250,000 drug-like molecules.
What Sorts of Data Scientists are These Companies Looking For?
For those of you who might be interested in making the switch, your deep learning skills in CNNs, RNNs, LSTMs, and Watson style QAMs will serve you well, depending on the company. The job descriptions we looked at called out Python and R but not much else specific to bioinformatics.
The exception is that the descriptions we saw asked for more than a passing familiarity with biological research. Our guess is that there aren’t enough data scientist with parallel degrees in biology to go around and that these companies will begin to favor strong data science over biology.
On the other hand, if we were advising our children what to study as they approach high school and college the combination of data science and biology looks strong.
Our guess is that this field is just getting underway and that to become as mature as tech AI is today will take another 7 to 10 years. That could be a good long career run for young data scientists today, or a good entry point for new data scientists graduating from school in 10 years.
Where we are today with CSB is roughly equivalent to Henry Ford’s hand built Model A. Between advances in data science and automation in this field, we could be routinely designing or editing genomes on computer screens in the not too distant future.
George Church, a genome scientist at Harvard Medical Schools says “I think this could be bigger than the space revolution or the computer revolution”. We think so too.
Other articles by Bill Vorhies.
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist since 2001. He can be reached at:
{kind=link}