

Data observability is an exploding category, and it seems like tools are getting invented, announced, and funded on a weekly basis. Poke around, though, and you’ll notice that many of them claim to do the same thing: end-to-end data observability. But what does that really mean?
Having total coverage means different things for different organizations. For companies that are heavily skewed towards analytics engineering, complexity arises around the warehouse and downstream from it. Therefore, shifting your data observability “right” makes more sense for these organizations.
The story is a lot more complicated for other organizations that are more heavily skewed towards data engineering. If you’re a team that works with a lot of data sources, you need to be really attentive to what’s coming into your system. Especially if they are data sources you don’t control; external data sources.
For them, that isn’t end-to-end data observability. That’s “The End” data observability. Meaning: this level of observability only gives visibility into the very end of the data’s lifecycle. Shifting right is important, but it’s a second-order problem compared to shift left data observability. It’s critical for these organizations to shift data observability left of the warehouse. It’s the best way to move your data operations out of a reactive data quality management framework, to a proactive one.
What is the Data Value Chain?
When people think of data, they often think of it as a static object; a point on a chart, a number in a dashboard, or a value in a table. But the truth is data is constantly moving and transforming throughout its lifecycle. And that means what you define as “good data quality” is different for each stage of that lifecycle.
“Good” data quality in a warehouse might be defined by its uptime. Going to the preceding stage in the life cycle, that definition changes. Data quality might be defined by its freshness, its completeness, or format. Therefore, your data’s quality isn’t some static binary. It’s highly dependent on whether things went as expected in the preceding step of its lifecycle.
From the time data is ingested, it’s moving and transforming. So, only looking at the data tables in your warehouse or your data’s source, or only looking at your data pipelines, it just doesn’t make a lot of sense. Looking only at one of those, you don’t have any context.
You need to look at the data’s entire journey. The thing is, when you’re a data-intensive company that’s using lots of external APIs and data sources, that’s a large part of the journey. The more external sources you have, the more vulnerable you are to changes you can’t predict or control. Covering the hard ground first, at the data’s extraction, makes it easier to catch and resolve problems faster since everything downstream depends on those deliveries.
The question of whether data will drive value for your business is defined by a series of operations:
- If data has been ingested correctly from our data sources, then our data will be delivered to our lake as expected.
- If data is delivered & grouped in our lake as expected, then our data will be able to be aggregated & delivered to our data warehouse as expected.
- If data is aggregated & delivered to our data warehouse as expected, then the data in our warehouse can be transformed.
- If data in our warehouse can be transformed correctly, then our data will be able to be queried and will provide value for the business.
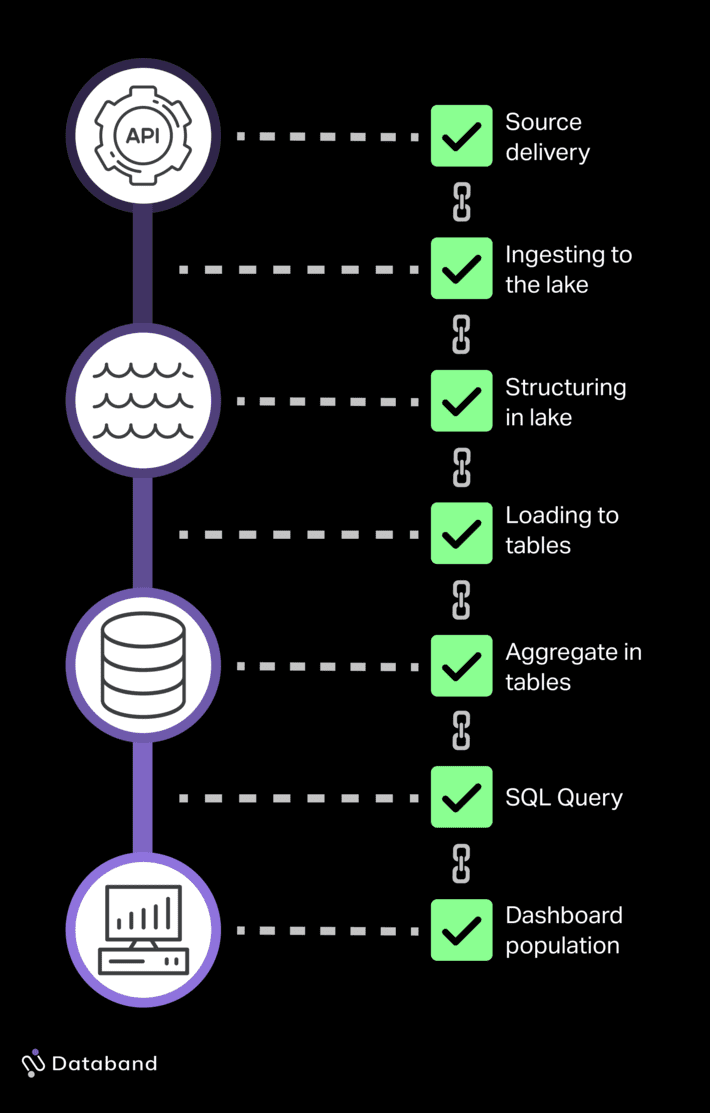
Let us be clear: this is an oversimplification of the data’s life cycle. That said, it illustrates how having observability only for the tables in your warehouse & the downstream pipelines leaves you in a position of blind faith.
In the ideal world, you would be able to set up monitoring capabilities & data health checkpoints everywhere in your system. This is no small project for most data-intensive organizations; some would even argue it’s impractical.
Realistically, one of the best places to start your observability initiative is at the beginning of the chain; at the data ingestion layer.
Shift-left data observability: why you need it
If you are one of these data-driven organizations, how do you set your data team up for success? While it’s important to have observability of the critical “checkpoints” within your system, the most important checkpoint you can have is at the data collection process. There are two reasons for that:
#1 – Loading data from external sources is one of the most vulnerable stages in your data pipeline
As a data engineer, you have some degree of control over your data & your architecture. But what you don’t control is your external data sources. When you have a data product that depends on external data arriving on time to function, that is an extremely painful experience.
This is best highlighted in an example. Let’s say you are running a large real estate platform called Willow. Willow is a marketplace where users can search for homes and apartments to buy & rent across the United States.
Willow’s goal is to give users all the information they need to make a buying decision; things like listing price, walkability scores, square footage, traffic scores, crime & safety ratings, school system ratings, etc.
In order to calculate “Traffic Score” for just one state in the US, Willow might need to ingest data from 3 external data sources. There are 50 states, so that means you suddenly have 150 external data sources you need to manage. And that’s just for one of your metrics.
Here’s where the pain comes in: You don’t control these sources. You don’t get a say whether they decide to change their API to better fit their data model. You don’t get to decide whether they drop a column from your dataset. You can’t control if they miss one of their data deliveries and leave you hanging.
All of these factors put your carefully crafted data model at risk. All of them can break your pipelines downstream that follow strictly coded logic. And there’s really nothing you can do about it except catching it as early as you can.
Having data observability in your data warehouse doesn’t so much to solve this problem. It might alert you that there is bad data in your warehouse, but by that point, it’s already too late.
This brings us to our next point…
#2 – It makes the most sense for your operational flow
In many large data organizations, data in your warehouse is being automatically utilized in your business processes. If something breaks your data collection processes, bad data is being populated into your product dashboards and analytics and you have no way of knowing that the data they are being served is no good.
This can lead to some tangible losses. Imagine if there was a problem calculating a Comparative Analysis of home sale prices in the area. Users may lose trust in your data and stop using your product.
In this situation, what does your operational flow for incident management look like?
You receive some complaints from business stakeholders or customers, you have to invest a lot of engineering hours to perform root cause analysis, fix the issue, and backfill the data. All the while consumer trust has gone down, and SLAs have already been missed. DataOps is in a reactive position.
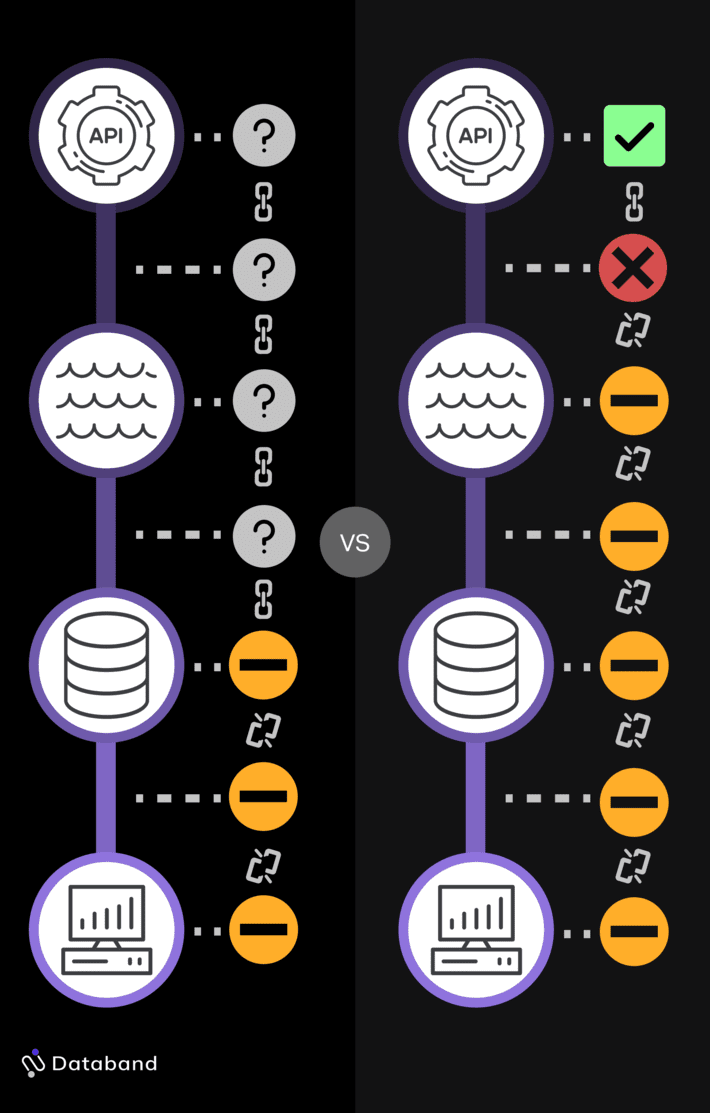
When you have data observability for your ingestion layer, there’s still a problem in this situation, but the way DataOps can handle this situation is very different:
- You know that there will be a problem.
- You know exactly which data source is causing the problem.
- You can project how this will affect downstream processes. You can make sure everyone downstream knows that there will be a problem so you can prevent the bad data from being used in the first place.
- Most importantly, you can get started resolving the problem early & begin working on a way to prevent that from happening again.
You cannot achieve that level of prevention when your data observability starts at your warehouse.
Bottom line: time to shift left
DataOps is learning many of the same, hard lessons as DevOps has. Just as application observability is the most effective when shifted left, the same applies to data operations. It saves money; it saves time; it saves headaches.
If you’re ingesting data from many external data sources, your organization cannot afford to focus all its efforts on the warehouse. You need real end-to-end data observability.
{kind=link}