
Big Data Reviews this time actually connect to my previous article entitled “Big Data Analysis” related to the benefits of what can be obtained by the Big Data platform. Current technological advances are able to condition a company to collect or store data from multiple sources that are in one container along with the increasing amount of data. Furthermore, the capacity of the capacity or store large volumes of data is then called the Big Data. That is, nowadays people know how to store data in large capacity, but the problem is not many people know how to analyze data in large capacity (Big Data Analytic) where the potential of Big Data technology actually exist in the creation of business insight and know Information is hidden from a large amount of unused data in the digital world by analysis. Before going deeper, here’s my understanding of Big Data.
Understanding Big Data
Big Data can be understood as very large amounts of data on internet protocol traffic such as internet user accounts, banking transaction data, sales transactions, stellar images, GPS, camera recorders, logs, user communications, trillions of posts, personal documents, Government documents, company documents, organization documents, videos, pictures, MP3 audio, email data, data providers and their customers, online games and other internet applications. Referring to very large and complex data so that storage and processing with traditional database applications is no longer adequate. Processing with traditional database applications for example is processing using MySQL database, MsSQL and the like. Thus, there is a need for a solution to some problems that require distributed systems for storage or computing needs because a problem can no longer be solved in one machine (single node / host) and the ability of the machine can no longer be scaled up. One of the main features of the big data tool or framework is the partition, which can answer the problem. But it is not a solution to all problems. Partitions themselves have some fairly binding limitations (strict) so that not all data models or computing problems can be solved with big data technology.
Because Big Data is often discussed with a broad topic, often misinterpretation of the Big Data itself. In addition the “buzzwords” in the articles on Big Data add further confusion. As if to conclude that Big Data can do anything, but it’s actually not that simple. For simplicity we can divide Big Data into some of the following topics:
- Big Data Technology: The most important thing here is understanding the difference between Big Data and Traditional Database (DWH: Data Warehouse). In big data technology we talk about hardware and software that can be used to store, process, and analyze data. A popular technique now is Hadoop-based and computational storage using Map Reduce (Yarn).
- Big Data Science: If the company uses Big Data to perform the functions that have been done by DWH (and ETL Platform), Big Data in this case is nothing more than a replacement or complement of DWH itself. Big Data Science talks about algorithms used to solve specific problems. For example: determining whether Welly’s name is a male or female name? Using a classification technique such as Naive Bayes, it can be solved easily.
- Big Data Cases: For example one on one campaign by Bank to its customers through email, sms, and social media. Banks send specific promotional expenditures based on customer profiles contained in Banks combined with data on their Twitter or Facebook. Seen here Big Data Case includes technology selection and selection of appropriate algorithms. In Big Data Case we talk about big data implementation in real field.
- Big Data Visualization: The data must be processed and displayed intuitively. Here there is an application role that can explore Big Data in order to obtain useful conclusions. Some visualization techniques used such as network analysis friendship on facebook to see who is most influential in the group. Or use LinkedIn to track and analyze the skills, knowledge, experience, and career tracks of employees, former employees and prospective employees.
Based on the above explanation now you already know what is meant Big Data and from the four points above it turns Big Data can not be separated from three things that are very important, that is how to store data, the process of analyzing and the results of the analysis process which I then summarized as Big Data Analytical. Because the hope Big Data not only as a large data warehouse of the virtual world (digital) but also must be able to provide benefits or added value for the real world. Furthermore, in accordance with the title of this article I will begin to describe what are the problems in the Big Data related in analyzing it.
Problems In Big Data Analysis: Inflexible data structure, swelling of storage consumption, inefficient computing process, heterogeneity problem, analysis result is only deterministic (not decision making).
But for the opportunity this time I will explain three problems, namely the inflexible data structure, the swelling of storage consumption, the process of inefficient computing, where three things are concerned with the preparation of data structures that lead to the ability of the partition of big data.
Data Structure Not Flexible
The main problem of the partition is the inflexible data structure. Data structures that we operate on big data technology in general represent the effectiveness and efficiency of processing that we will do. To simplify the problem we try to simplify using analogies and simple examples, assuming we have user transaction data from a fictitious e-commerce with the following data structures that have been stored in a big data storage.
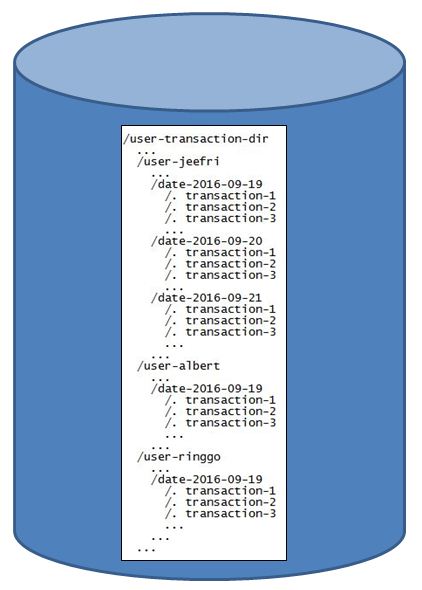 From that example, we will be able to easily find something if the partition is known, for example:
From that example, we will be able to easily find something if the partition is known, for example:
- How many Albert purchases on 2016-09-19? We can aggregate the sums directly into the partition (/ user-transaction-dir / user-albert / date-2016-09-19).
- How many times Jeefri has shopped in our store? We can look at the partition (/ user-transaction-dir / user-jeefri) and calculate the number of transactions that have been done. This may require a high resource if Pak Jeefri has made transactions for a long time and much so that the partitions and data in them are large enough, but it is still possible to do so.
However, for some examples of the following cases, the above data structures are no longer relevant:
- As of 2016-09-19 how many users did the transaction?
- What are the total transactions amounting to over one million rupiah (IDR) ?
The two examples above require that we track all partitions, which means we perform a full scan table (HBase / Cassandra terminology), because we do not know the primary partition of the data. It is not reliable because of the early mindset of big data technology, our data is very large, hundreds of terabytes, petabytes, and even infinite. So doing a full scan table obviously does not make sense. It could take hours, even months just to do one simple operation. That is one example of the limitations of big data technology related to the features or the principle of data partition, ie the data structure closely affects the effectiveness and efficiency of an operation, whether search, storage, or computing, depending on the technology we use.
Swelling of Storage Consumption.
Solutions for the problem of data structures that have been described one of them is by using a secondary data structure or specific as needed. For example, assume that the above-mentioned data structure is a structure to satisfy customer-related transaction needs, we can create new structures to transactions-time-related and numeric (amount-based-transaction) needs.
 Of the two additional data structures are automatic data that needs to be stored will multiply more and more at least three times from the beginning. In some cases there are times when the swelling of data storage consumption can no longer be avoided, especially for big data technologies that offer storage solutions such as HDFS, HBase, Cassandra. Although it can be done with other approaches, without the need to duplicate raw data by pre-computing, of course with other shortcomings and advantages (beyond the topic of this paper).
Of the two additional data structures are automatic data that needs to be stored will multiply more and more at least three times from the beginning. In some cases there are times when the swelling of data storage consumption can no longer be avoided, especially for big data technologies that offer storage solutions such as HDFS, HBase, Cassandra. Although it can be done with other approaches, without the need to duplicate raw data by pre-computing, of course with other shortcomings and advantages (beyond the topic of this paper).
Inefficient Computing Process
This is especially true for big data technologies that offer distributed computation like Hadoop, MapReduce and Apache Spark. Assume we perform a process with different approaches to the same amount of data as the exchangeable partition structure, eg in the above example which was originally “/ user / date /” to “/ date / user”. The more partitions means the more queuing processes, this can lead to the “bottle neck”, if the number of nodes we assign is too small, this will be an advantages if we do have a large number of nodes. Similarly vice versa if the less partition, which means the amount of data will be more in one partition, then the number of job queue will be less, but in one process will take more resources (longer), this is suitable if node we Assign a small amount or computing capacity (RAM and cores) in one high node.
Conclusion
Partitioning is indeed a basic and major feature in big data technology related to the physical location where the process is performed or data is stored. It is the solution of some scalability issues so that we can provide solutions scale out. But the partition itself also has some limitations and attachments that need to be considered, because the data structure that represents the partition greatly affects the effectiveness and efficiency of an operation on big data technology for storage, computing, and other processing. Could be the amount of investment costs that we have spent on big data technology does not give any impact if the design of our data structure is not appropriate.
Hopefully this article gives you many benefits
Thanks (^_^)
{kind=link}