
The key to perform any text mining operation, such as topic detection or sentiment analysis, is to transform words into numbers, sequences of words into sequences of numbers. Once we have numbers, we are back in the well-known game of data analytics, where machine learning algorithms can help us with classifying and clustering.
We will focus here exactly on that part of the analysis that transforms words into numbers and texts into number vectors: text encoding.
For text encoding, there are a few techniques available, each one with its own pros and cons and each one best suited for a particular task. The simplest encoding techniques do not retain word order, while others do. Some encoding techniques are fast and intuitive, but the size of the resulting document vectors grows quickly with the size of the dictionary. Other encoding techniques optimize the vector dimension but lose in interpretability. Let’s check the most frequently used encoding techniques.
1. One-Hot or Frequency Document Vectorization (not ordered)
One commonly used text encoding technique is document vectorization. Here, a dictionary is built from all words available in the document collection, and each word becomes a column in the vector space. Each text then becomes a vector of 0s and 1s. 1 encodes the presence of the word and 0 its absence. This numerical representation of the document is called one-hot document vectorization.
A variation of this one-hot vectorization uses the frequency of each word in the document instead of just its presence/absence. This variation is called frequency-based vectorization.
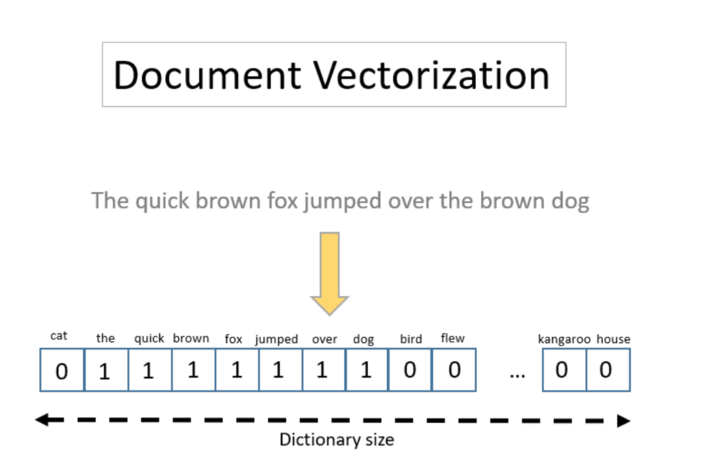
While this encoding is easy to interpret and to produce, it has two main disadvantages. It does not retain the word order in the text, and the dimensionality of the final vector space grows rapidly with the word dictionary.
The order of the words in a text is important, for example, to take into account negations or grammar structures. On the other hand, some more primitive NLP techniques and machine learning algorithms might not make use of the word order anyway.
Also, the rapidly growing size of the vector space might become a problem only for large dictionaries. And even in this case, the word number can be limited to a maximum, for example, by cleaning and/or extracting keywords from the document texts.
2. One-Hot Encoding (ordered)
Some machine learning algorithms can build an internal representation of items in a sequence, like ordered words in a sentence. Recurrent Neural Networks (RNNs) and LSTM layers, for example, can exploit the sequence order for better classification results.
In this case, we need to move from a one-hot document vectorization to a one-hot encoding, where the word order is retained. Here, the document text is represented again by a vector of presence/absence of words, but the words are fed sequentially into the model.
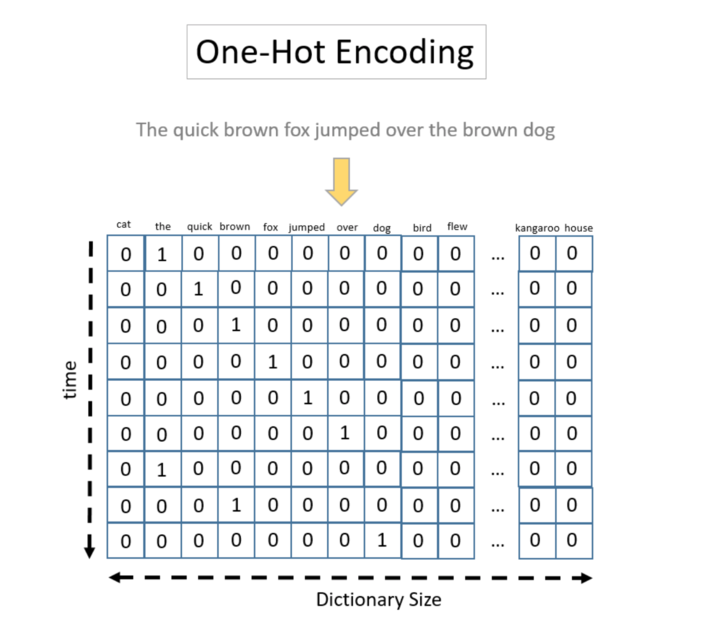
When using the one-hot encoding technique, each document is represented by a tensor. Each document tensor consists of a possibly very long sequence of 0/1 vectors, leading to a very large and very sparse representation of the document corpus.
3. Index-Based Encoding
Another encoding that preserves the order of the words as they occur in the sentences is the Index-Based Encoding. The idea behind the index-based encoding is to map each word with one index, i.e., a number.
The first step is to create a dictionary that maps words to indexes. Based on this dictionary, each document is represented through a sequence of indexes (numbers), each number encoding one word. The main disadvantage of the Index-Based Encoding is that it introduces a numerical distance between texts that doesn’t really exist.
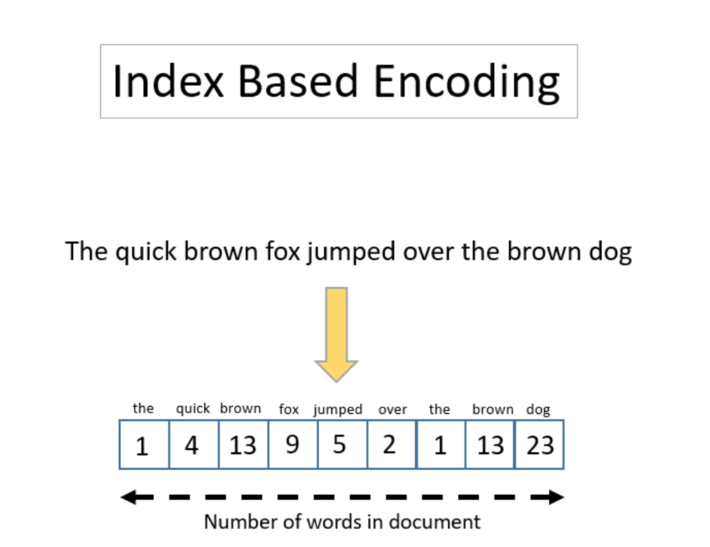
Notice that index-based encoding allows document vectors of different lengths. In fact, the sequences of indexes have variable length, while the document vectors have fixed length.
4. Word Embedding
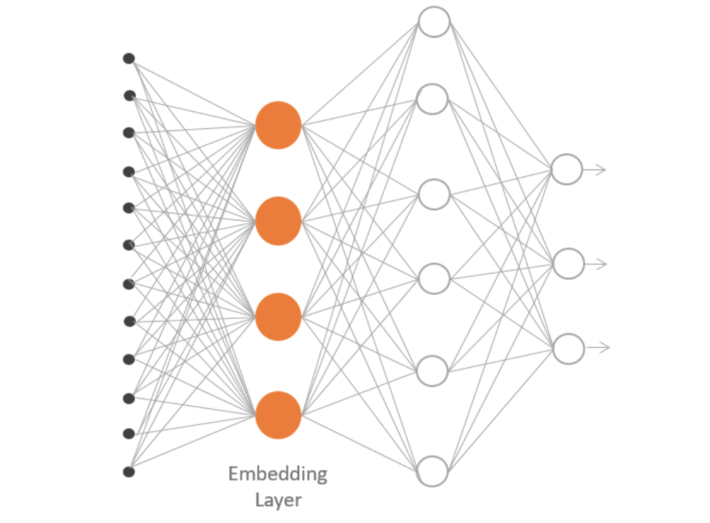
The last encoding technique that we want to explore is word embedding. Word embeddings are a family of natural language processing techniques aiming at mapping semantic meaning into a geometric space.1 This is done by associating a numeric vector to every word in a dictionary, such that the distance between any two vectors would capture part of the semantic relationship between the two associated words. The geometric space formed by these vectors is called an embedding space. The best known word embedding techniques are Word2Vec and GloVe.
Practically, we project each word into a continuous vector space, produced by a dedicated neural network layer. The neural network layer learns to associate a vector representation of each word that is beneficial to its overall task, e.g., the prediction of surrounding words.2
Auxiliary Preprocessing Techniques
Many machine learning algorithms require a fixed length of the input vectors. Usually, a maximum sequence length is defined as the maximum number of words allowed in a document. Documents that are shorter are zero-padded. Documents that are longer are truncated. Zero-padding and truncation are then two useful auxiliary preparation steps for text analysis.
Zero-padding means adding as many zeros as needed to reach the maximum number of words allowed.
Truncation means cutting off all words after the maximum number of words has been reached.
Summary
We have explored four commonly used text encoding techniques:
- Document Vectorization
- One-Hot Encoding
- Index-Based Encoding
- Word Embedding
Document vectorization is the only technique not preserving the word order in the input text. However, it is easy to interpret and easy to generate.
One-Hot encoding is a compromise between preserving the word order in the sequence and maintaining the easy interpretability of the result. The price to pay is a very sparse, very large input tensor.
Index-Based Encoding tries to address both input data size reduction and sequence order preservation by mapping each word to an integer index and grouping the index sequence into a collection type column.
Finally, word embedding projects the index-based encoding or the one-hot encoding into a numerical vector in a new space with smaller dimensionality. The new space is defined by the numerical output of an embedding layer in a deep learning neural network. The additional advantage of this approach consists of the close mapping of words with similar role. The disadvantage, of course, is the higher degree of complexity.
We hope that we have provided a sufficiently general and complete description of the currently available text encoding techniques for you to choose the one that best fits your text analytics problem.
1 Chollet, Francois “Using pre-trained word embeddings in a Keras model”, The Keras Blog, 2016
2 Brownlee, Jason “How to Use Word Embedding Layers for Deep Learning with Keras”, Machine Learning Mystery, 2017
Kathrin Melcher contributed to this article. She is a data scientist at KNIME. She holds a master’s degree in mathematics from the University of Konstanz, Germany. She enjoys teaching and applying her knowledge to data science, machine learning and algorithms.
{kind=link}