
Summary: Objectively identifying hateful or abusive speech on social media platforms would allow those platforms to better control it. However to be objective and without bias that identification would have to be independent of the author especially where elected officials are involved.
 What could be more timely than discussions around what represents 1st Amendment free speech and what might be eliminated or controlled as hateful for abusive speech on social media.
What could be more timely than discussions around what represents 1st Amendment free speech and what might be eliminated or controlled as hateful for abusive speech on social media.
Although we understand that very few restrictions exist on our right to express aloud or in writing our personal opinions, be they fair or foul, we do not necessarily have unrestricted access to the communication channels most of us have come to rely on.
Specifically we’re talking about social media, Facebook, Twitter, Instagram and all the others. As private organizations they are not required to give us unfettered access to their platforms. And as a society we’ve come to broadly agree that some of the most extreme forms of speech, for example promoting human trafficking or torture are topics we support suppressing from these platforms.
Where the line is particularly fuzzy lately is where public figures who are widely followed, especially elected political figures, offer statements or opinions that are offensive to many but also supported by many others.
If only it were possible to identify hateful or abusive speech with some precision without regard to the author. Then we might encourage our social media platforms to adopt such measures without fear of intentionally or unintentionally silencing some voices more than others.
As it happens, a recently published paper in arXiv makes advances on this exact topic. In “To Target or Not to Target”: Identification and Analysis of Abusiv… Gaurav Verma, and his coauthors show how this might be done with reasonable accuracy using the Twitter Abusive Behavior dataset.
The dataset developed around 2018 and largely credited to Antigoni Founta and her coauthors used crowdsourcing to label 100,000 Tweets into four categories. After much analysis and updating that dataset is now labeled in four categories: normal (53%), spam (27%), abusive (14%), and hateful (5%).
Several researchers including those at Twitter have succeeded in building multi-class classifiers with accuracy in the range of 80% to 85%, more than enough to be useful. However they all relied on including data and metadata that identified the user and network.
The accomplishment of this new research is to achieve roughly the same accuracy (0.83 on the hold out test set) without any reference to user and network. Tweets could then be fairly (within the bounds of model accuracy) labeled as abusive or hateful regardless of the author and objectively suppressed, assuming Twitter and all its users could agree that was appropriate.
Their approach uses three separate models with the final score from a fourth ensemble models. To ensure all references to user and network were removed the researchers replaced all user mentions and web links with tokens.
Model 1
LIWC text analysis software categorizes words into 94 psychologically meaningful categories. LIWC is widely regarded as able to identify aspects of “attentional focus, emotionality, social relationships, thinking styles, and individual differences”. These category scores were then used to train a logistic regression.
Model 2
Model 2 used the fastText library to create a simple n=3 N-gram bag to capture information about word order which in turn was used to train a classifier. The trained model “provides vector representations (or embeddings) of the sentences as well as for the words in the vocabulary. The word embeddings allow us to execute nearest neighbor queries as well as perform analogy operations”.
Model 3
The third model used a bidirectional LSTM model with attention. The attention module allows weights to be assigned to determine which words are most crucial or determined to have the greatest contribution toward the prediction which were then used to classify highly attended words into each of the four prediction categories.
The Stacked Ensemble
As is usual, the probability estimates for each of the three base models were used as inputs to the ensemble logistic regression. The accuracy of each of the three base models were all good and reasonably close to one another. When combined in the ensemble the results were essentially as good as those achieved by other researchers who included user and network data. 
Where the model came up short was in differentiating between ‘hateful’ and ‘abusive’. In the original dataset these two terms are frequently labeled together (hateful emphasizing a well-defined target group).
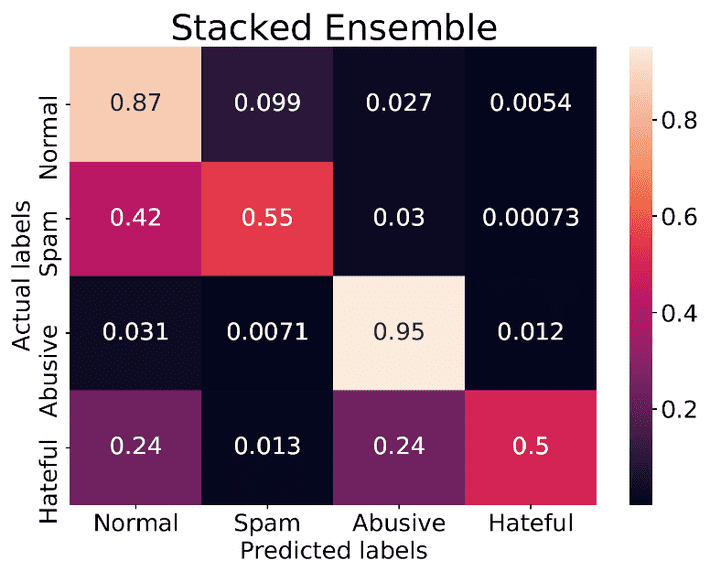
In any event, the model and its general approach to defining these categories without reference to author or network offers a way forward to objectively identifying and potentially controlling this type of content. Assuming that is what the social media platform and its users truly want.
Other articles by Bill Vorhies
About the author: Bill is Contributing Editor for Data Science Central. Bill is also President & Chief Data Scientist at Data-Magnum and has practiced as a data scientist since 2001. His articles have been read more than 2.1 million times.
{kind=link}