
 Data-based decision making is increasing in medicine because of its efficiency and accuracy.
Data-based decision making is increasing in medicine because of its efficiency and accuracy.- One branch of research uses Data Analytics and Machine Learning to predict stroke outcomes.
- Models can predict risk with high accuracy while maintaining a reasonable false positive rate.
 Data-based decision making is increasing in medicine because of its efficiency and accuracy.
Data-based decision making is increasing in medicine because of its efficiency and accuracy.Stroke is the second leading cause of death worldwide. According to the World Health Organization [1], 5 million people worldwide suffer a stroke every year. Of these, one third die and another third are left permanently disabled. In the United States, someone has a stroke every 40 seconds and every four minutes, someone dies [2]. The aftermath is devastating, with victims experiencing a wide range of disabling symptoms including sudden paralysis, speech loss or blindness due to blood flow interruption in the brain [3]. The economic burden to the healthcare system in the United States amounts to about $34 billion per year in the US [4]. An additional $40 per year is spend on care for elderly stroke survivors [5].
Despite these alarming statistics, there is a glimmer of hope: strokes are highly preventable if high risk patients can be identified and encouraged to make lifestyle modifications. While some risk factors like family history, age, gender, and race cannot be modified, it is estimated that 60 to 80% of strokes could be prevented through healthy lifestyle changes like losing weight, smoking cessation, and controlling high cholesterol and blood pressure levels [6, 7]. However, despite the wealth of data on these risk factors, traditional, non-DS methods typically perform quite poorly at predicting who will have a stroke and who will not; Identifying high risk patients is a challenge because of the complex relationship between contributory risk factors.
Predicting Stroke Outcome with Data Analytics and Machine Learning
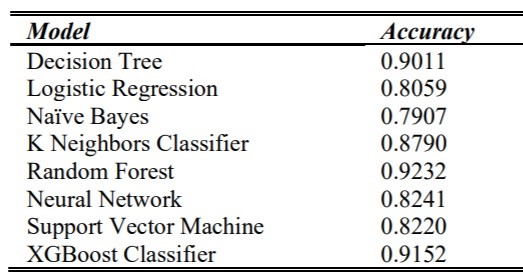
Various DA and ML models have been successfully applied in recent years to assess stroke risk factors and outcomes. They include evaluating a mixed-effect linear model to predict the risk of cognitive decline poststroke [8] and developing a deep neural network (DNN) model, applying logistic regression and random forest to predict poststroke motor outcomes [9]. In another study, researchers created a model capable of predicting stroke outcome with high accuracy and validity; The research applied an unbalanced dataset containing information for several thousand individuals with known stroke outcomes. Various algorithms including decision trees, Naïve Bayes and Random Forest were assessed, with random Forest classifier the most promising, predicting stroke outcome with 92% accuracy. The following table shows results for various methods employed in the study [10]:
Improving the False Negative Rate with ML
One of the major challenges with attempting to predict any major disease like stroke is the high cost of false negatives. A false negative result is where the patient has the disease, but the test (or predictive tool) does not identify the patient as having the disease (or risk for the disease). Unlike false negatives in a business setting, false negatives in medicine can have deadly consequences. If someone gets a false negative and is told they are not at risk for a major disease, then they are not in a position to make informed lifestyle choice–putting their life in danger. Historically, false negative rates from traditional approaches exceeds 50%, but this has been reduced to less than 20% by applying machine learning tools [11].
The Future of Stroke Prediction
Data Science is the optimal solution to dealing with the approximately 1.2 billion clinical documents being produced in the United States every year [12]. The results from DS based stroke prediction research look promising. The tools are more reliable and valid than traditional methods; They can also be acquired conveniently and at a low cost [11]. As data science continues to grow within medicine, it will open new opportunities for more informed healthcare and prevention of deaths from major diseases like stroke.
References
Image: mikemacmarketing / original posted on flickrLiam Huang / clipped and posted on flickr, CC by 2.0 via Wikimedia Commons
[1] Stroke, Cerebrovascular accident | Health topics – WHO EMRO
[2] Heart Disease and Stroke Statistics2020 Update: A Report From the …
[3] The science of stroke: Mechanisms in search of treatments
[4] American Heart Association Statistics Committee and Stroke Statisti…
[5] Care received by elderly US stroke survivors may be underestimated.
[6] Preventing Stroke: Healthy Living Habits | cdc.gov.
[7] The science of stroke: Mechanisms in search of treatments,
[8] Risk prediction of cognitive decline after stroke.
[9] Prediction of Motor Function in Stroke Patients Using Machine Learn…,
[10] Stroke prediction through Data Science and Machine Learning Algorithms
[11] A hybrid machine learning approach to cerebral stroke prediction ba… dataset
[12] Health story project
{kind=link}