
Ecommerce sites generate tons of web server log data which can provide valuable insights through analysis. For example, if we know which users are more likely to buy a product, we can perform targeted marketing, improve relevant product placement on our site and lift conversion rates. However, raw web logs are often enormous and messy so preparing the data to train a predictive model is time consuming for data scientists.
According to a recent Forbes article, “Data preparation accounts for about 80% of the work of data scientists”, but “76% of data scientists view data preparation as the least enjoyable part of their work”. Data scientists know that if the preparation steps are not properly done, then the rest of their efforts will be wasted.
This blog post demonstrates how to streamline the process of data preparation for predictive modeling by combining Amazon SageMaker with AuriQ’s Essentia for a large corporate client.
Essentia is a data processing tool for efficient transformation of large volumes of unstructured data into a suitable format for modeling. Amazon SageMaker is a machine learning platform well suited to large datasets. Details about the nature of the client’s business can’t be shared, but we can share the technologies and approach used for you to apply to other large datasets.
Creating Data from Web Log
First, the web server log data we use is exported daily as a compressed TSV with over 1,000 columns. Each row has a customer’s unique id along with a URL path for the page they’re viewing. We need to create training data summarizing information about each customer such as, how many times they viewed a specific product page in the last 7 days. Using Essentia, we can transform massive data sets in Amazon cloud, and can export to Amazon’s S3 data storage. Jupyter Notebook supports SageMaker and can read data directly from S3, making a simple pipeline across tools.
This pipeline dramatically improves the timeline for processing our client’s over 700GB of raw web log data. Essentia handled all data processing for the client’s 8,200 files (each containing over 1,000 columns) in 1 hour with 100 Amazon EC2 m4.large instances. In contrast, Python/Pandas & R can’t readily handle such big data when shared memory is required across multiple instances. This fast iteration ability also proved useful later during feature engineering.
Train a Model on SageMaker
After preparing the data, we can open Jupyter Notebook and start building a model using Amazon Sagemaker. We want to predict whether each customer will make a purchase in the coming month and will treat this as a classification problem (classifying each customer as buying or not).
Following Amazon’s instructions to get started, we’ve provided a quick example of the Hyperparameter tuning setup. SageMaker supports the popular XGBoost software for training gradient boosting machines, one of the top performing algorithms in predictive modeling competitions, and the most common algorithm used in industry today. The example below shows how easy it is to build an XGBoost model in SageMaker.
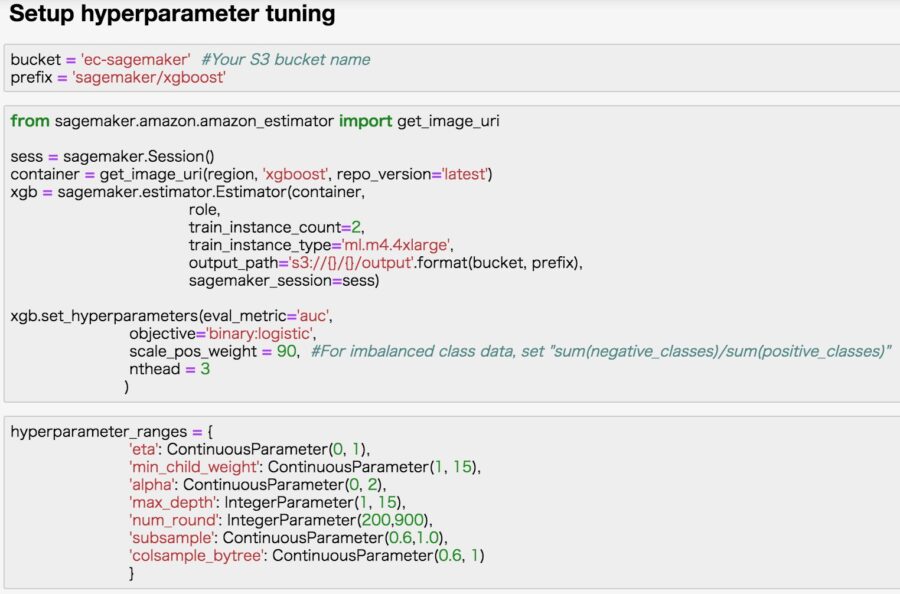
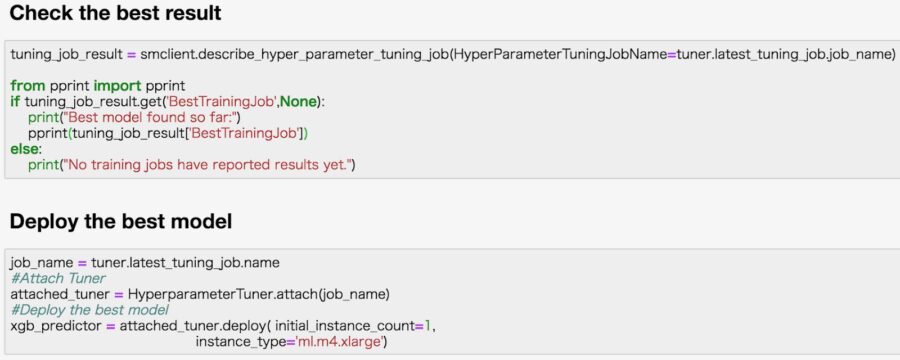
Check out Amazon SageMaker’s documentation for more examples:
- Targeting Direct Marketing with Amazon SageMaker XGBoost
- Direct Marketing with Amazon SageMaker XGBoost and Hyperparameter T…
Feature Engineering
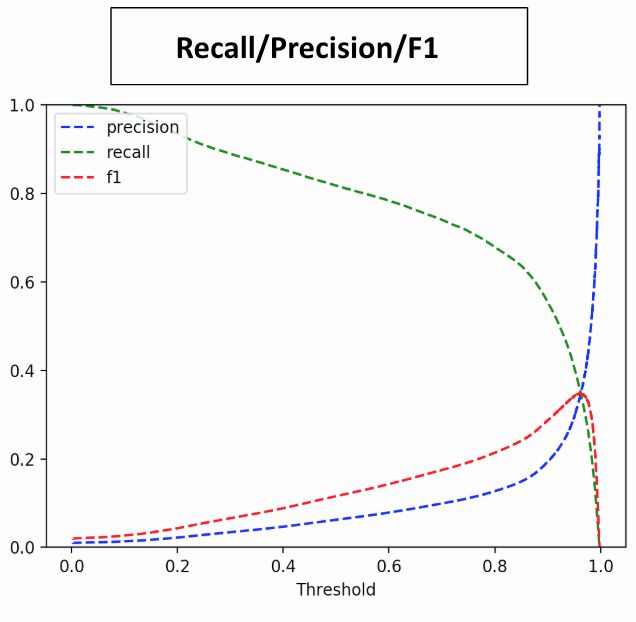
Because the data is highly imbalanced (positive class is 1% of all classes), we set the evaluation metric as AUC on a precision recall curve, and emphasize the value of recall since we’re trying to predict rare instances of purchasing customers (around 1%) and prefer false positives over false negatives for marketing: marketing to a few customers who don’t end up purchasing isn’t as bad as not marketing effectively to customers who are very close to purchasing. To improve performance, we continued feature engineering, creating new predictive features by expanding on those that were helpful initially. The fast iteration ability of the combined solutions also streamlined the feature engineering process as well.
Results on test dataset:

※1 Accuracy/Recall/Precision are calculated based on threshold, 0.5 temporarily.
※2 When randomed, AUC(PR curve) is 0.01 for this dataset. On the other hand, AUC(ROC curve) is always 0.5 against any dataset.
Deployment and Continuous Improvement
The client may want to generate updated predictions for all their customers on a daily, weekly, or monthly basis depending on their marketing strategy. With Essentia and SageMaker it’s straightforward to automate the entire process and notify related teams of any significant changes to the model’s performance over time. Overall, Essentia and Amazon SageMaker make it easy to transform large raw data sets into finely tuned predictive models.
{kind=link}